



































Table of Contents
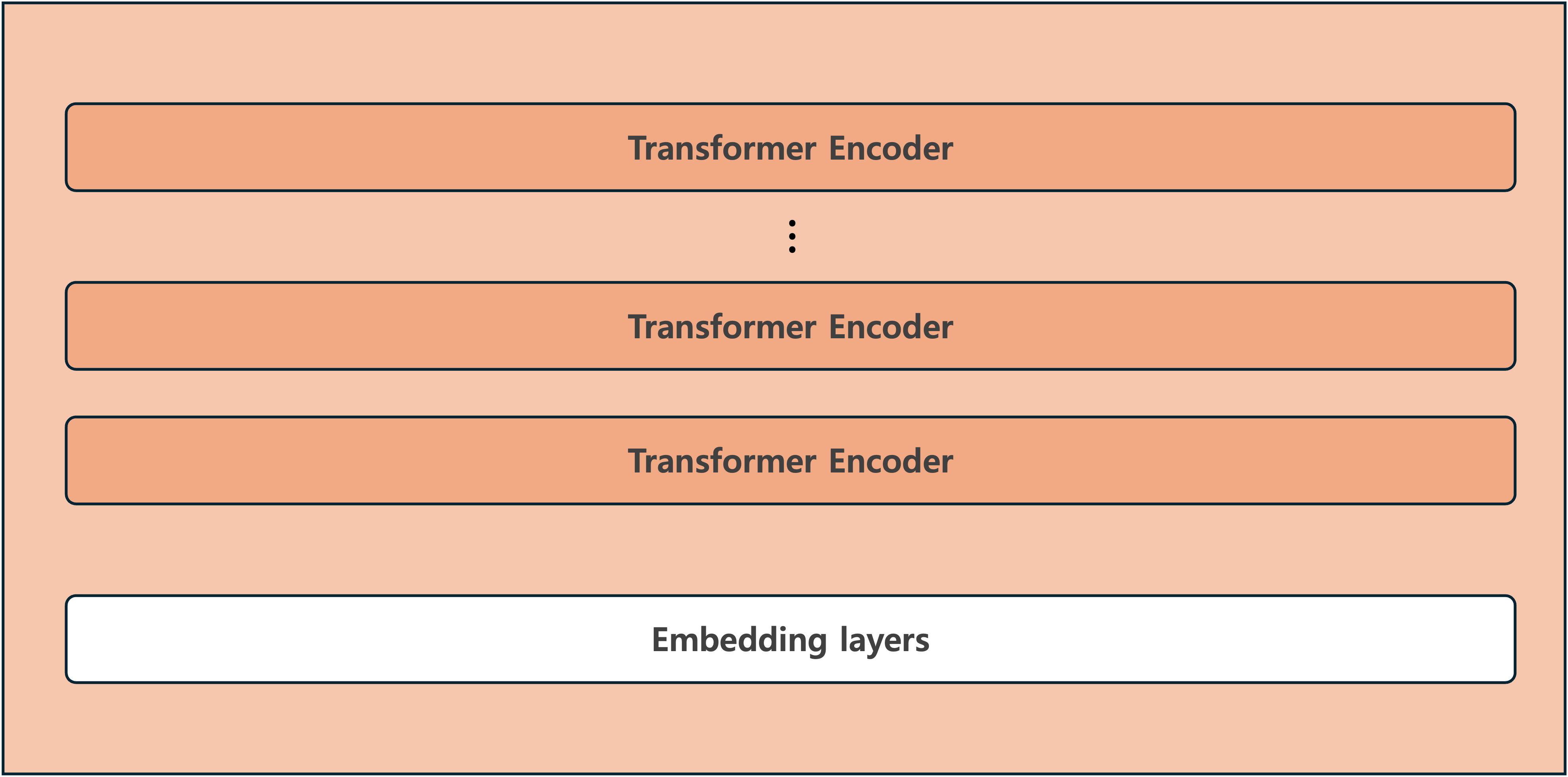
BERT
- Bidirectional Encoder Representations from Transformers
- 2018년에 구글이 공개한 사전 훈련(Pre-trained)된 모델이다
- 트랜스포머의 인코더를 여러 층 쌓아올린 구조이다
특징
- 대량의 unlabeled data 코퍼스로 먼저 사전 학습(pre-training) 하고, 이 후 특정 태스크에 대해 추가 학습(fine-tuning) 할 수 있는 모델이다
- (그래서 사전학습된 BERT 모델을 다운받은 후, 개발자가 원하는 태스크에 추가 학습 시키면 된다)
- 양방향 구조로 토큰 임베딩이 학습 되어, 앞뒤 문맥이 잘 반영된 임베딩 벡터를 얻었으며, 결과적으로 자연어에 대한 이해도가 높은 모델이 얻어졌다
Pre-Training
- 모델을 바로 태스크에 적용한다면 사전 훈련에 대해 자세히 알아야 될 필요는 없다
- 하지만 사전 훈련이 어떻게 이뤄졌는지 알게 되면,
- 대량의 unlabeled data 코퍼스로 어떻게 모델을 학습시켰는지
- BERT가 어떻게 양방향 구조를 얻게 되었는지
- 여러 태스크에 대해 높은 성능을 보일 수 있는 이유가 무엇인지
- 우리의 태스크에 적용하기 위해 입력을 어떻게 처리하고, 출력을 어떻게 활용할지 알 수 있게 된다
- BERT의 사전 훈련은 크게 다음 두 가지 문제를 푸는 방법으로 진행된다
- MLM(Masked Language Model): 마스킹된 단어를 예측하는 문제
- NSP(Next Sentence Prediction): 두 문장이 이어지는지를 예측하는 문제
MLM
- Masked Language Model
- unlabeled data 코퍼스에서 가져온 문장의 일부(15%)를 마스킹해서, 마스킹된 단어를 예측하도록 한다
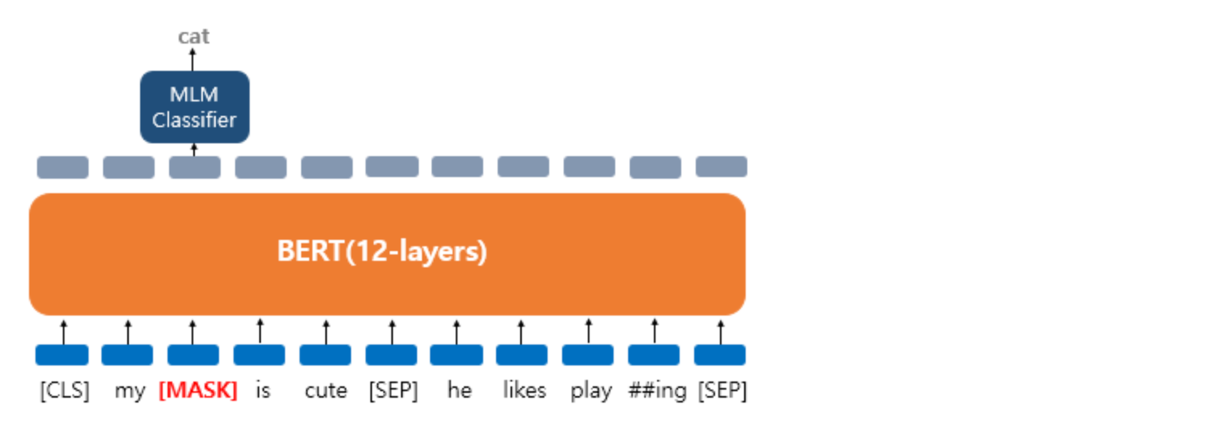
- 근데 15%를 모두
[MASK]로만 하지는 않고, 일부는 의도적으로 다른 단어를 넣거나, 그대로 넣기도 한다- 80%의 단어들은
[MASK]로 변경한다.- ex. The man went to the store → The man went to the
[MASK]
- ex. The man went to the store → The man went to the
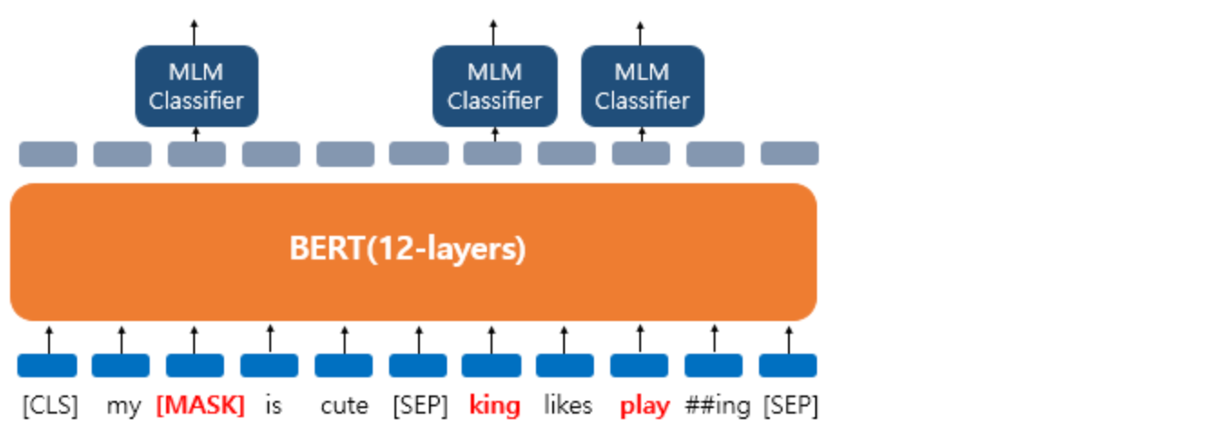
- 10%의 단어들은 랜덤으로 단어가 변경된다.
- ex. The man went to the store → The man went to the dog
- 10%의 단어들은 동일하게 둔다.
- ex. The man went to the store → The man went to the store
- 80%의 단어들은
- 이렇게 하는 이유는, 파인 튜닝 단계에서는
[MASK]토큰이 없기 때문에, 파인 튜닝 단계와의 데이터 불일치 문제를 완화하기 위해서이다
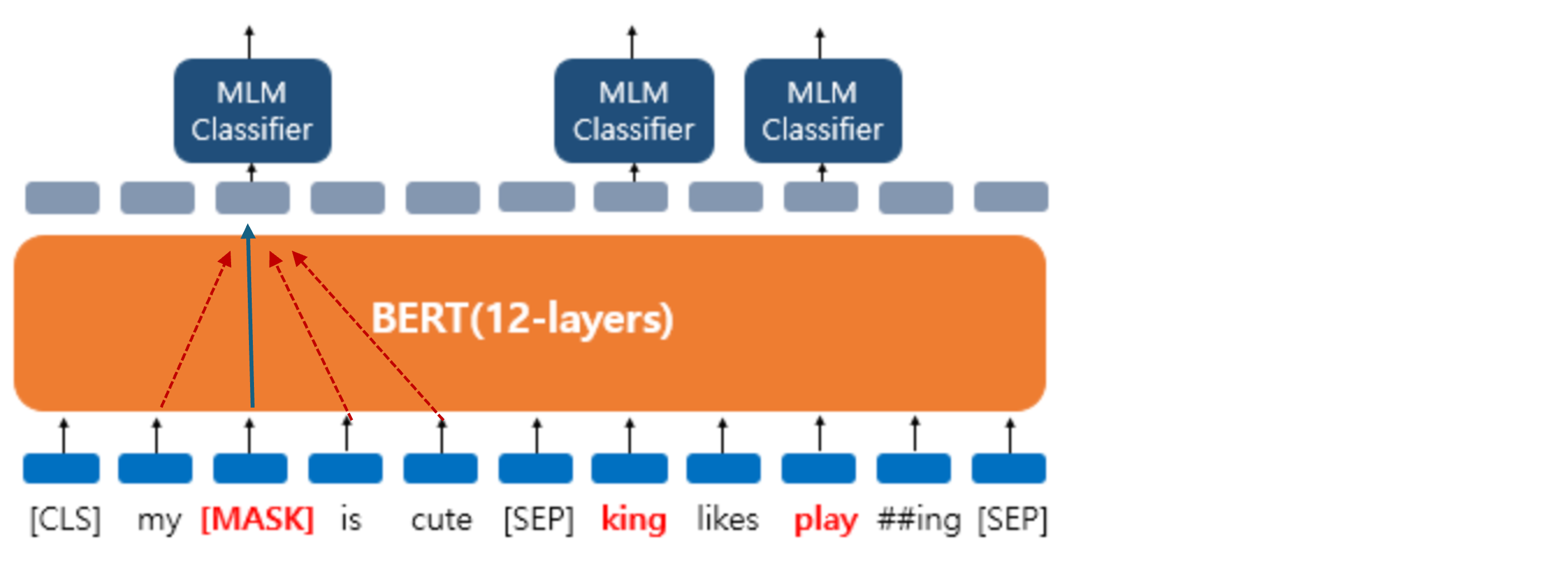
- 여기서 마스킹된 단어를 예측하기 위해 BERT 모델은 앞뒤 단어를 이용하게 된다. 결론적으로 셀프 어텐션을 사용하는 트랜스포머의 인코더 구조와, 마스크드 언어 모델(MLM)이 BERT를 양방향 구조로 만들었다고 할 수 있다
NSP
- Next Sentence Prediction
- BERT는 사전훈련 때 두 개의 문장을 준 후에 서로 이어지는 문장인지 맞추는 방식으로 훈련된다
- 5:5 비율로 실제 이어지는 두 개의 문장과 랜덤으로 이어붙인 두 개의 문장을 주고 훈련시킨다
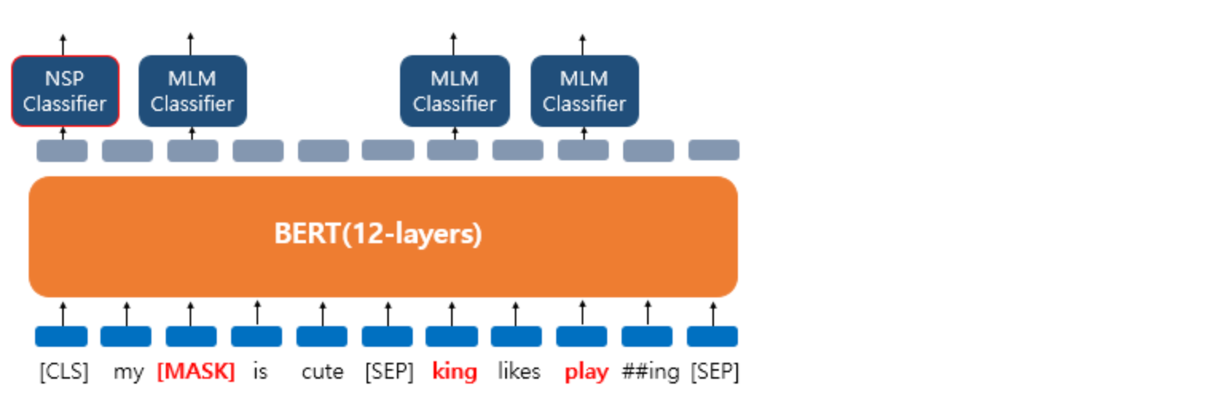
- BERT의 입력으로 넣을 때에는
[SEP]라는 특별 토큰을 사용해서 문장을 구분한다 - 첫번째 문장의 끝에
[SEP]토큰을 넣고, 두번째 문장이 끝나면 역시[SEP]토큰을 붙여준다 - 그리고 이 두 문장이 실제 이어지는 문장인지 아닌지를
[CLS]토큰의 위치의 출력층에서 이진 분류 문제를 풀도록 한다 - 최종적으로 loss 값은 마스크드 언어 모델과 다음 문장 예측의 loss를 합하여 학습이 동시에 이루어지게 된다
- BERT가 다음 문장 예측이라는 태스크를 학습하는 이유는 BERT가 풀고자 하는 태스크 중에서는 Question Answering 같이 두 문장의 관계를 이해하는 것이 중요한 태스크들이 있기 때문이다
- (파인 튜닝할 때는 문장 하나만 필요한 태스크인 경우 그냥 문장 하나만 입력으로 써도 된다)
Fine-Tuning
- 우리의 태스크에 맞게 파인튜닝하는 방법에 대해 알아보자
- 우리의 태스크가 분류 문제라면 출력의
[CLS]토큰 값을 활용한다 - 단어마다 어떤 값을 예측해야 한다면 그외의 출력 토큰을 활용한다
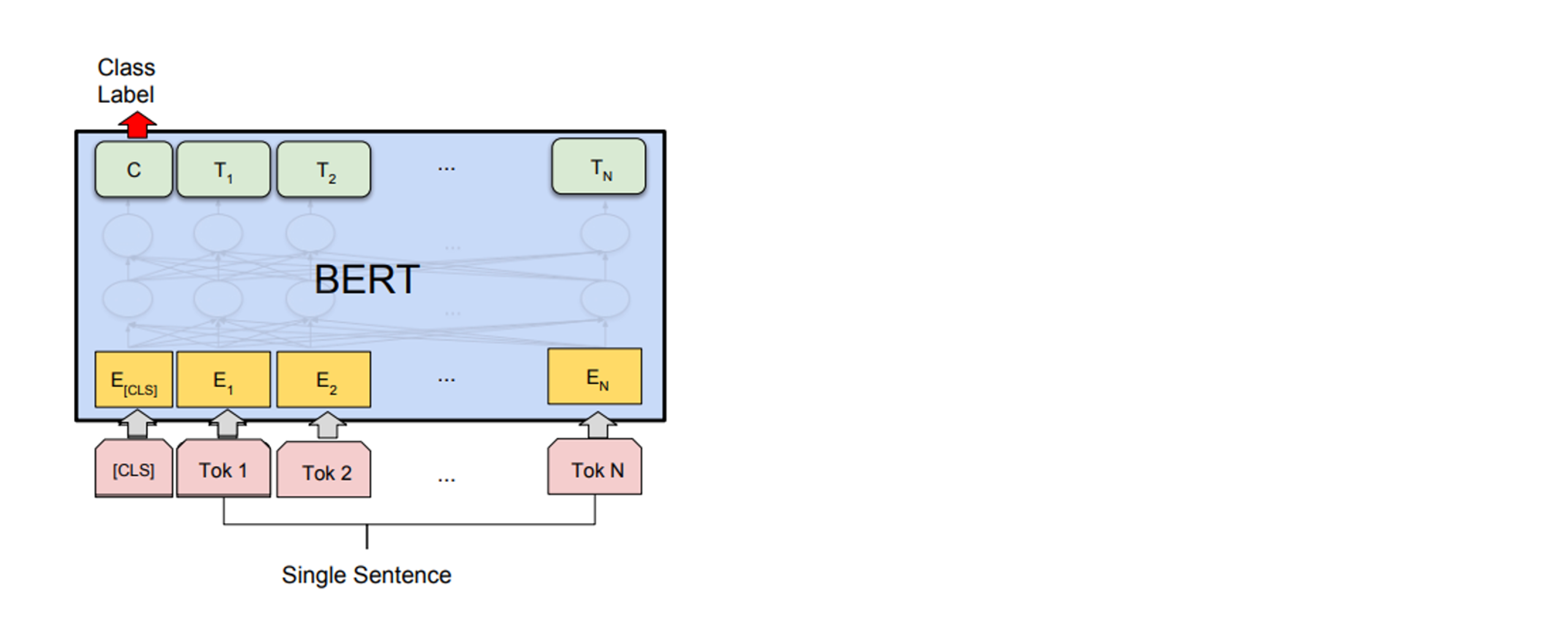
텍스트 분류 태스크
- 스팸 메일인지 아닌지, 긍정인지 부정인지 같은 분류 문제의 경우 아래 그림과 같다
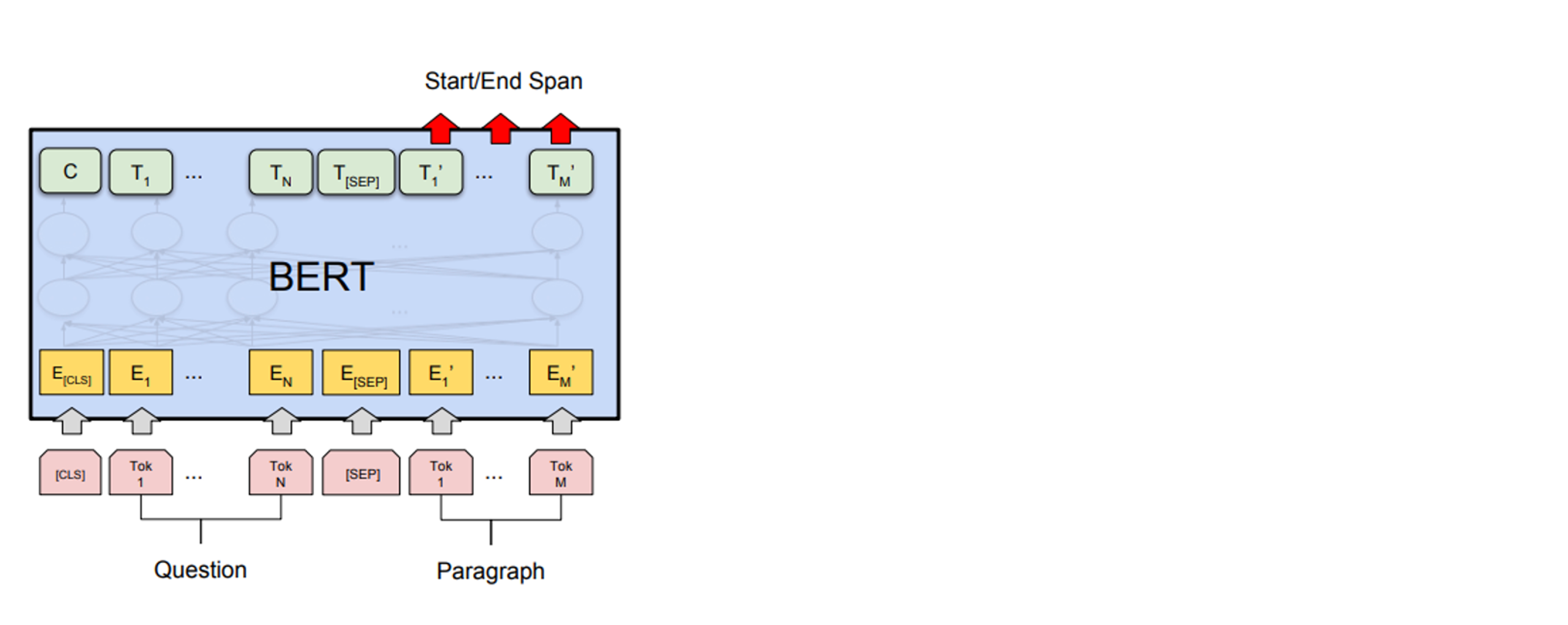
QA 태스크
- 질문에 대한 답변을 문단 내에서 일부 추출하는 방식이다
파인 튜닝할 때 신경써야 할 요소
- Token Embedding을 위해
vocabulary_size를 알려줘야 한다 - 한 개의 문장만 이용하는 태스크라면 Segment Embedding을 하나의 값으로, 두 개의 문장을 이용하는 태스크라면 Segment Embedding을 두 개의 값을 써서 문장을 구분해줘야 한다
QA 모델 실습
AutoClasses
- AutoClasses are here to do this job for you so that you automatically retrieve the relevant model given the name/path to the pretrained weights/config/vocabulary
Tokenizer
-
A tokenizer is in charge of preparing the inputs for a model
-
주요 역할
- Tokenizing
- Add new tokens to vocabulary
- Managing special tokens