



































Table of Contents
NLP
- Natural Language Processing
- 인간의 언어 즉, 자연어와 관련된 인공지능 분야
- 단순히 단어의 뜻을 아는 것을 넘어서, 문맥을 이해하는 것을 목표로 한다
NLP Tasks
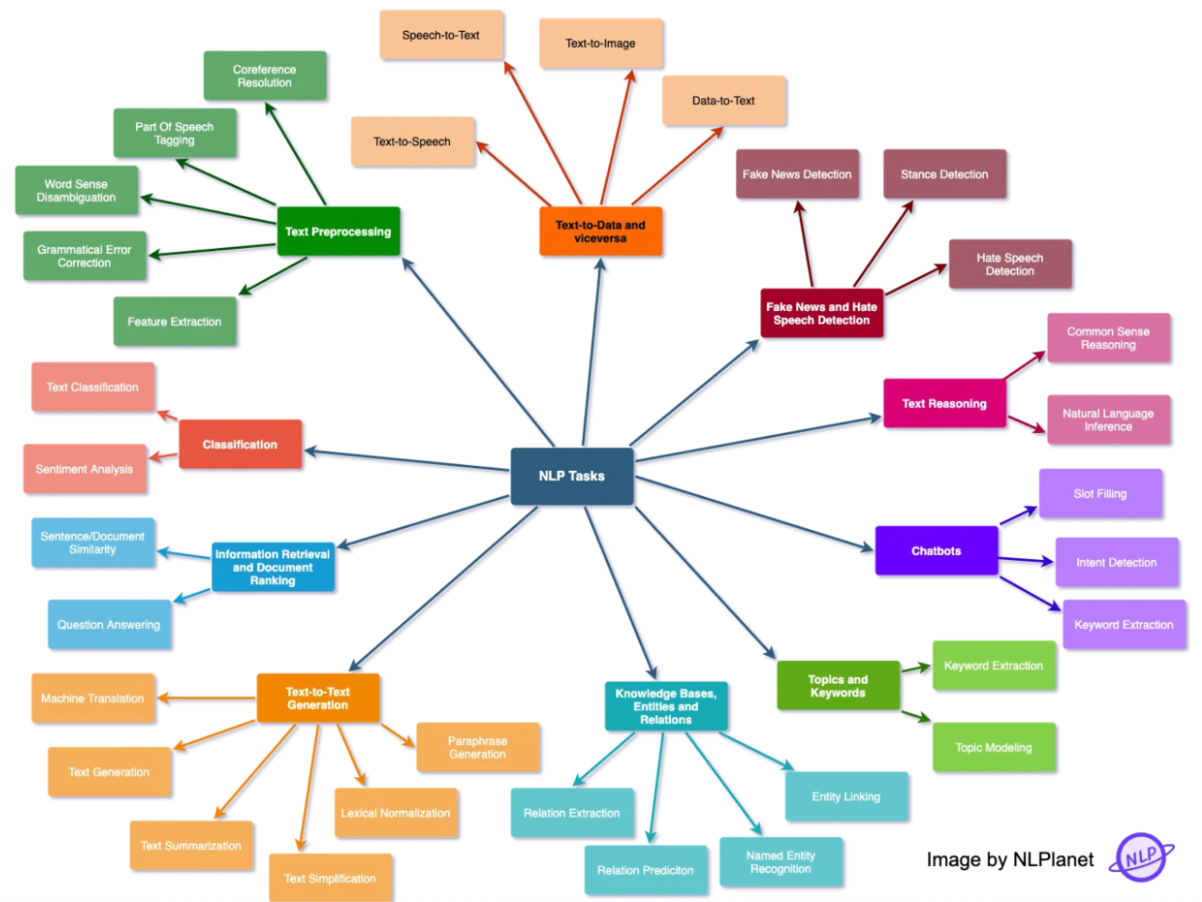
Classification
- 텍스트를 특정 범주에 따라 나누는 태스크를 말한다
- 감정 분석 (Sentiment Analysis)
- 주식 호재/악재
- 스팸 여부
- 리뷰의 종류
Information Retrieval and Document Ranking
- 주어진 텍스트로부터 관련 정보/문서를 찾아 제공하는 태스크를 말한다
- 텍스트 유사도 (Text Similarity)
- 질문/응답 (Question Answering)
Text-to-Text Generation
- 주어진 텍스트로부터 새로운 텍스트를 생성하는 태스크를 말한다
- 기계 번역 (Machine Translation)
- 문서 요약 (Text Summarization)
- 텍스트 생성 (Text Generation)
Chatbots
- 사용자와 대화하는 태스크를 말한다
- 사용자의 정보, 이 전에 나눴던 대화 등의 상태를 저장하고 이러한 지식을 활용해 대화할 수 있어야 한다
NLP Process
- 토큰화 해서 사전(Vocabulary)을 만든다
- 사전에 있는 단어들을 임베딩 벡터로 나타낼 수 있어야 한다
- 태스크에 맞는 모델을 정의한다
- 임베딩 벡터들을 입력으로 해서 모델을 학습시킨다
- 모델을 학습시키는 과정에서 임베딩 벡터가 점점 개선된다
- 임베딩 벡터가 점점 개선되기 때문에, 모델은 점점 언어에 대한 이해가 높아지고, 우리의 태스크(ex. 감정 분석)를 더 잘 풀게 된다
-
Pretrained Language Model을 쓸 경우, 처음에 임베딩 벡터에 대한 좋은 초기값을 가지고 출발할 수 있다 (ex. BERT, GPT)
- 이미 만들어진 임베딩을 다른 작업을 학습하기 위한 입력값으로 쓰기도 한다. 이를 전이 학습(transfer learning)이라 한다
-
전이 학습은 task specific한 모델을 학습하는 fine tuning 과정을 위한 좋은 초기값을 제공한다
- 단어 임베딩: 가장 적절한 단어를 찾아내는 과정에서 임베딩 벡터를 얻는다
-
문장 임베딩: 단어 시퀀스를 찾아내는 과정에서 임베딩 벡터를 얻는다
- 단어 임베딩은 동음이의어 문제를 해결하지 못한다
- 문장 임베딩은 왜 동음이의어 문제를 해결할 수 있는거지?
- 단어 임베딩이든, 문장 임베딩이든 결국 임베딩 벡터 한개는 토큰을 나타낸다
- 동음이의어 문제를 해결했다는게, 예를 들어 ‘배’를 가리키는 임베딩 벡터가 먹는 ‘배’, 타는 ‘배’에 따라 임베딩 벡터가 바뀐다는 그런게 아니라,
-
‘배’ 라는 단어를 모델이 해석할 때, ‘배’ 하나만 이용 하는게 아니라, ‘배’ 단어 주변의 문맥까지 살펴서 문제를 해결한다는 의미
- Seq2seq, Transformer 같은 모델들은 학습 과정에서 임베딩 벡터가 구해진다
- GPT, BERT 같은 모델들은 대규모 코퍼스로 임베딩 벡터의 초기값을 얻고, 파인 튜닝을 통해 task specific한 임베딩 벡터가 구해진다