



































Table of Contents
IPC
- Inter-Process Communication의 줄임말 -> 프로세스간 통신을 의미
- 프로세스끼리 서로 데이터를 주고 받는 방법들을 일컫어 IPC라고 함
- 스레드끼리는 메모리를 공유한다 -> 공유하는 공간이 있기 때문에 데이터를 주고 받는데 크게 어려움이 없다
- 프로세스는 별도의 메모리에 생성된다 -> 공유하는 공간이 없다 -> 이를 위해 운영체제 커널에서 IPC를 위한 여러 도구를 제공
- 공유 메모리, 파일, 파이프, 소켓, 메세지 큐, RPC
Use Cases
There are several good reasons and common use cases for IPC:
- Sharing information/data: 프로세스간 데이터 동기화
- Computational Speedups: 데이터 처리를 다른 쪽에 넘김
- Modularity: 같은 응용 프로그램을 여러 프로세스로 띄울 때 프로세스간 데이터 공유 (ex. 크롬 브라우저의 탭)
- Development: 하나의 서비스안에 있는 여러 어플리케이션을 독립적으로 개발하고, 필요한 데이터를 IPC 통신을 통해 공유
공유 메모리
- 여러 프로세스가 별도의 공간에 위치해 있는 메모리의 주소를 참조해 해당 메모리를 함께 읽고 쓰는 것을 말한다
- read, write를 모두 할 수 있다
- 중개자 없이 메모리에 바로 접근 가능하기 때문에 IPC 방법 중에 가장 빠른 방법이다
- 메모리 영역에 대한 동시적인 접근을 제어하기 위해 잠금(locking)이나 세마포어(semaphore) 등을 사용할 수 있다
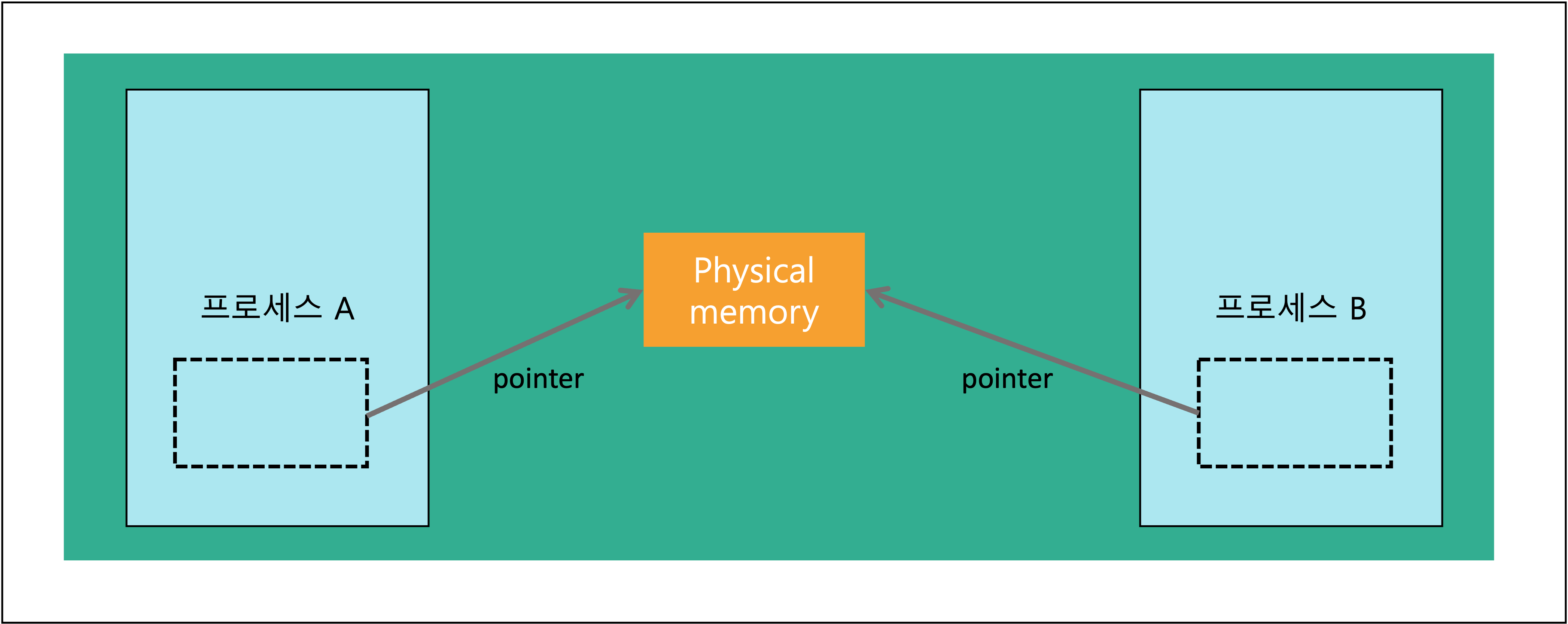
공유 메모리의 장점
- 커널의 관여 없이 메모리를 직접 사용하여 IPC 속도가 빠르다
- 프로그램 레벨에서 통신 기능을 제공하여, 자유로운 통신이 가능하다
공유 메모리의 단점
- 구현하기 어렵다는 단점이 있다.
파일
- 파일을 이용한 통신은 부모-자식 프로세스 간 통신에 많이 사용한다
- 운영체제가 별다른 동기화를 제공하지 않아도 된다
- 동기화를 위해 주로 부모 프로세스가
wait()함수를 이용하여 자식 프로세스의 작업이 끝날 때까지 기다린다
파이프
- 파이프는 프로세스간의 데이터를 파이프를 통해 주고 받는 것을 의미한다
- 공유 메모리와 가장 큰 차이점은 OS가 동시 접근 제어를 알아서 관리해준다는 점이다
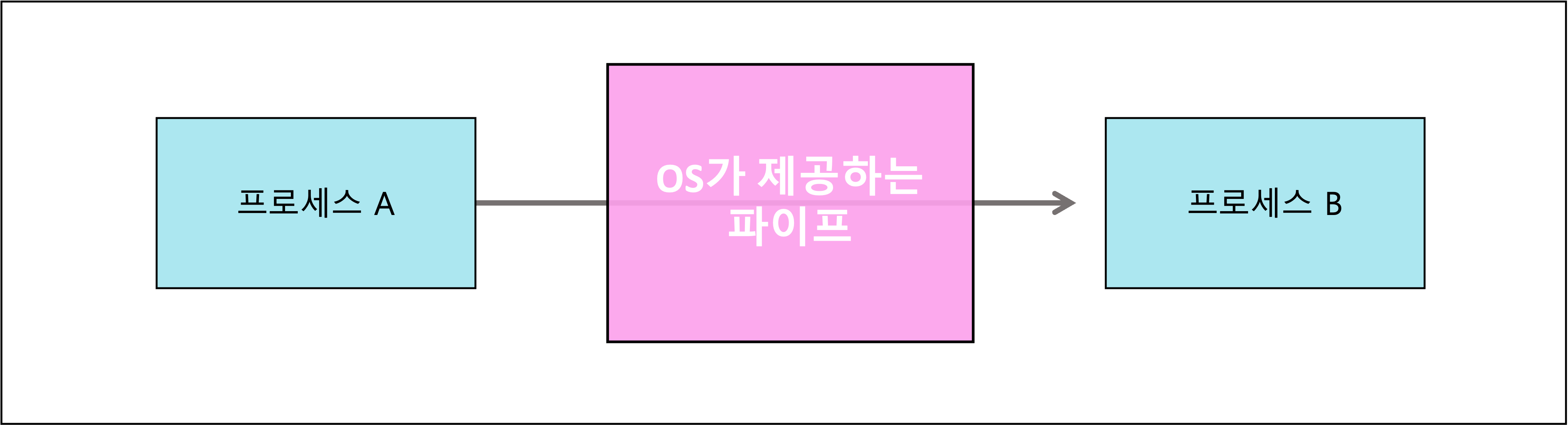
- 익명 파이프 (Anonymous Pipe)
- 기본 파이프
- 부모-자식, 형제 프로세스간 통신에 사용
- 기본적으로 하나의 프로세스는 read, 다른 하나는 write만 가능한 단방향 통신 -> 양방향 통신을 위해서는 2개의 파이프 필요
- 파이프를 사용하는 프로세스가 없으면 자동으로 제거됨
- 네임드 파이프 (Named Pipe)
- 부모-자식, 형제 프로세스가 아닌 서로 무관한 프로세스간 통신에도 사용 가능
- FIFO라 불리는 특수한 파일 사용
- 네임드 파이프로 양방향 통신을 위해서는 2개의 파이프 필요
- 파이프를 사용하는 프로세스가 없어도 제거되지 않고 남아있음
메세지 큐
- 파이프와 비슷하게 단방향 통신
- 파이프와 다른점은 메세지 큐는 메모리를 사용
- 다수의 프로세스간 데이터 전달 가능
- 메시지 큐를 사용하기 위해서는, “메시지 큐 ID”를 알아야 함 (cf.소켓은 상대방 프로세스의 “포트 번호”만 알면 가능)
소켓
- 소켓은 두 프로세스간 통신을 위해 제공되는 엔드포인트
- 소켓은 네트워크 연결을 지원하기 때문에 원격에 있는 프로세스간 통신도 제공한다
- 양방향 통신이 가능하다
- 서버/클라이언트 구조의 프로세스간 통신에 자주 사용
- 소켓은 대부분의 언어에서 API 형태로 제공하는 편리함 때문에 지금도 많이 사용되고 있지만, 일련의 통신 과정을 직접 구현하므로 통신 관련 장애를 처리하는 것은 고스란히 개발자의 몫이 된다
- 서비스가 고도화될 수록 데이터의 종류도 많아지고, 결과적으로 데이터 포맷팅이 어려워진다
- 이런 소켓의 한계를 극복하기 위해 RPC(Remote Procedure Call)라는 기술이 등장했다
RPC
Remote Procedure Call is a technique for building distributed systems. Basically, it allows a program on one machine to call a subroutine on another machine without knowing that it is remote
- IPC의 한 종류
- 분산 시스템에서 많이 사용하는 방식
- 원격에 있는 프로세스와의 통신을 마치 로컬에 있는 프로시저를 실행하듯 사용
- (프로시저(procedure)는 서브루틴(subroutine)이 될 수도 있고, 서비스가 될 수도 있고, 함수가 될 수도 있다)
- MSA(Micro Service Architecture)패턴으로 서비스를 개발하는 환경에서 유용하게 활용됨
- RPC는 Java, Python, Go와 같은 다양한 언어로 구현할 수 있음
- RPC는 프로세스간 통신 과정을 추상화
- 네트워크 장비, 프로토콜, 운영체제에 무관하게 개발 가능
RPC: 네트워크로 연결된 서버 상의 프로시저(함수, 메서드 등)를 원격으로 호출할 수 있는 기능
네트워크 통신을 위한 작업 하나하나 챙기기 귀찮으니. 통신이나 call 방식에 신경쓰지 않고 원격지의 자원을 내 것처럼 사용할 수 있죠. IDL(Interface Definication Language) 기반으로 다양한 언어를 가진 환경에서도 쉽게 확장이 가능하며, 인터페이스 협업에도 용이하다는 장점이 있습니다.
RPC의 핵심 개념은 ‘Stub(스텁)’이라는 것인데요. 서버와 클라이언트는 서로 다른 주소 공간을 사용 하므로, 함수 호출에 사용된 매개 변수를 꼭 변환해줘야 합니다. 안그러면 메모리 매개 변수에 대한 포인터가 다른 데이터를 가리키게 될 테니까요. 이 변환을 담당하는게 스텁입니다.
client stub은 함수 호출에 사용된 파라미터의 변환(Marshalling, 마샬링) 및 함수 실행 후 서버에서 전달 된 결과의 변환을, server stub은 클라이언트가 전달한 매개 변수의 역변환(Unmarshalling, 언마샬링) 및 함수 실행 결과 변환을 담당하게 됩니다. 이런 Stub을 이용한 기본적인 RPC 통신 과정을 살펴보겠습니다.
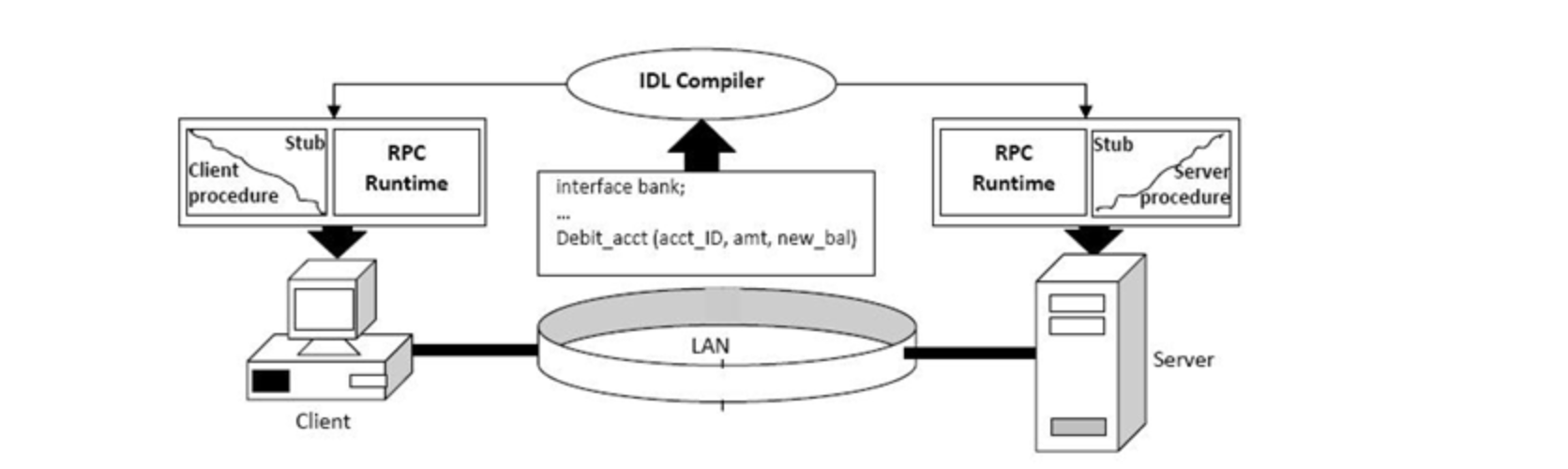
- IDL(Interface Definition Language)을 사용하여 호출 규약 정의합니다.
- 함수명, 인자, 반환값에 대한 데이터형이 정의된 IDL 파일을 rpcgen으로 컴파일하면 stub code가 자동으로 생성됩니다.
- Stub Code에 명시된 함수는 원시코드의 형태로, 상세 기능은 server에서 구현됩니다.
- 만들어진 stub 코드는 클라이언트/서버에 함께 빌드합니다.
- client에서 stub 에 정의된 함수를 사용할 때,
- client stub은 RPC runtime을 통해 함수 호출하고
- server는 수신된 procedure 호출에 대한 처리 후 결과 값을 반환합니다.
- 최종적으로 Client는 Server의 결과 값을 반환받고, 함수를 Local에 있는 것 처럼 사용할 수 있습니다.
구현의 어려움/지원 기능의 한계 등으로 제대로 활용되지 못했습니다. 그렇게 RPC 프로젝트도 점차 뒷길로 가게되며 데이터 통신을 우리에게 익숙한 Web을 활용해보려는 시도로 이어졌고, 이 자리를 REST가 차지하게됩니다.
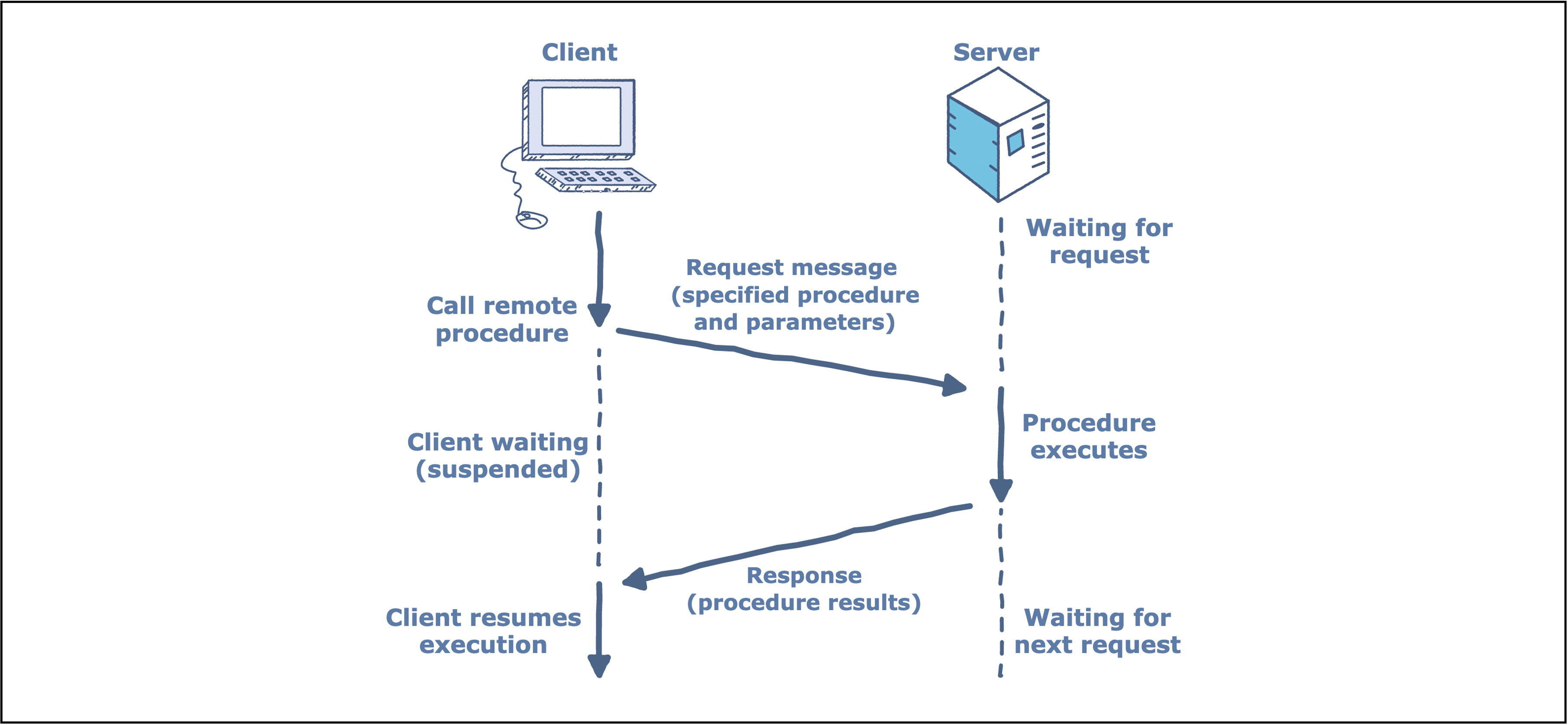
When the client calls the server, the RPC system must take care of:
- Taking all the parameters which are passed to the subroutine and transferring them to the remote node;
- Having the subroutine executed on the remote node; and
- Transferring back all the parameters which are returned to the calling routine.
The most common method of doing this is by the use of stub modules. The client program is linked to a client stub module. This is a subroutine which looks (from the outside) in every respect like the remote subroutine. On the inside, it is almost empty: all it does is take the values of the parameters which are passed to it, and put them in a message. This is known as marshalling.
The client stub then uses a routine in the RPC Run-Time System (RTS) to send the message off and wait for a reply message. When the reply arrives, the stub unmarshals the parameters that were returned in the reply message, putting their values into the variables of the calling program. The client stub then returns to the calling program just like a normal subroutine.
The following steps take place during a RPC
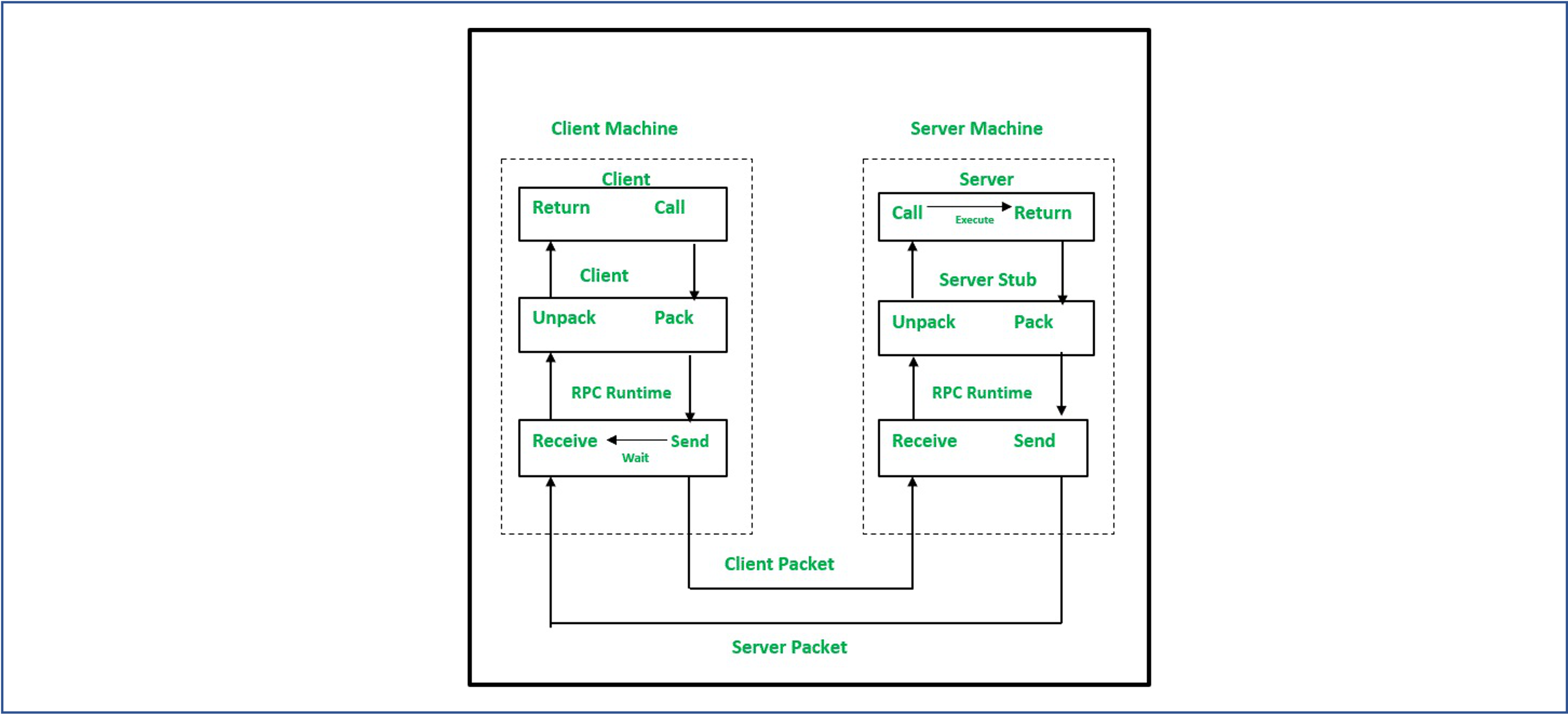
- A client invokes a client stub procedure, passing parameters in the usual way. The client stub resides within the client’s own address space.
- The client stub marshalls(pack) the parameters into a message. Marshalling includes converting the representation of the parameters into a standard format, and copying each parameter into the message.
- The client stub passes the message to the transport layer, which sends it to the remote server machine.
- On the server, the transport layer passes the message to a server stub, which demarshalls(unpack) the parameters and calls the desired server routine using the regular procedure call mechanism.
- When the server procedure completes, it returns to the server stub (e.g., via a normal procedure call return), which marshalls the return values into a message. The server stub then hands the message to the transport layer.
- The transport layer sends the result message back to the client transport layer, which hands the message back to the client stub.
- The client stub demarshalls the return parameters and execution returns to the caller.
RPC의 장점
- 비즈니스 로직에 집중할 수 있음.
- 다양한 언어를 가진 환경에서 쉽게 확장할 수 있음.
- 쉽게 인터페이스 협업이 가능함.
RPC의 단점
- 새로운 학습 비용이 듬.
- 사람의 눈으로 읽기 힘듬.
RPC의 대표적인 구현체
- Google의 ProtocolBuffer
- Facebook의 Thrift
- Twitter의 Finalge
REST (REpresentational State Transfer)
REST는 HTTP/1.1 기반으로 URI를 통해 모든 자원(Resource)을 명시하고 HTTP Method를 통해 처리하는 아키텍쳐 입니다. 자원 그 자체를 표현하기에 직관적이고, HTTP를 그대로 계승하였기에 별도 작업 없이도 쉽게 사용할 수 있다는 장점으로 현대에 매우 보편화되어있죠. 하지만 REST에도 한계는 존재합니다. REST는 일종의 스타일이지 표준이 아니기 때문에 parameter와 응답 값이 명시적이지 않아요. 또한 HTTP 메소드의 형태가 제한적이기 때문에 세부 기능 구현에는 제약이 있습니다.
덧붙여, 웹 데이터 전달 format으로 xml, json을 많이 사용하는데요.
XML은 html과 같이 tag 기반이지만 미리 정의된 태그가 없어(no pre-defined tags) 높은 확장성을 인정 받아 이기종간 데이터 전송의 표준이었으나, 다소 복잡하고 비효율적인 데이터 구조탓에 속도가 느리다는 단점이 있었습니다. 이런 효율 문제를 JSON이 간결한 Key-Value 구조 기반으로 해결하는 듯 하였으나, 제공되는 자료형의 한계로 파싱 후 추가 형변환이 필요한 경우가 많아졌습니다. 또한 두 타입 모두 string 기반이라 사람이 읽기 편하다는 장점은 있으나, 바꿔 말하면 데이터 전송 및 처리를 위해선 별도의 Serialization이 필요하다는 것을 의미합니다.
gRPC
gRPC는 google 사에서 개발한 오픈소스 RPC(Remote Procedure Call) 프레임워크입니다. 이전까지는 RPC 기능은 지원하지 않고, 메세지(JSON 등)을 Serialize할 수 있는 프레임워크인 PB(Protocol Buffer, 프로토콜 버퍼)만을 제공해왔는데, PB 기반 Serizlaizer에 HTTP/2를 결합하여 RPC 프레임워크를 탄생시킨 것이죠.
REST와 비교했을 때 기반 기술이 다르기에 특징도 많이 다르지만, 가장 두드러진 차이점은 HTTP/2를 사용한다는 것과 프로토콜 버퍼로 데이터를 전달한다는 점입니다. 그렇기에 Proto File만 배포하면 환경과 프로그램 언어에 구애받지 않고 서로 간의 데이터 통신이 가능합니다.
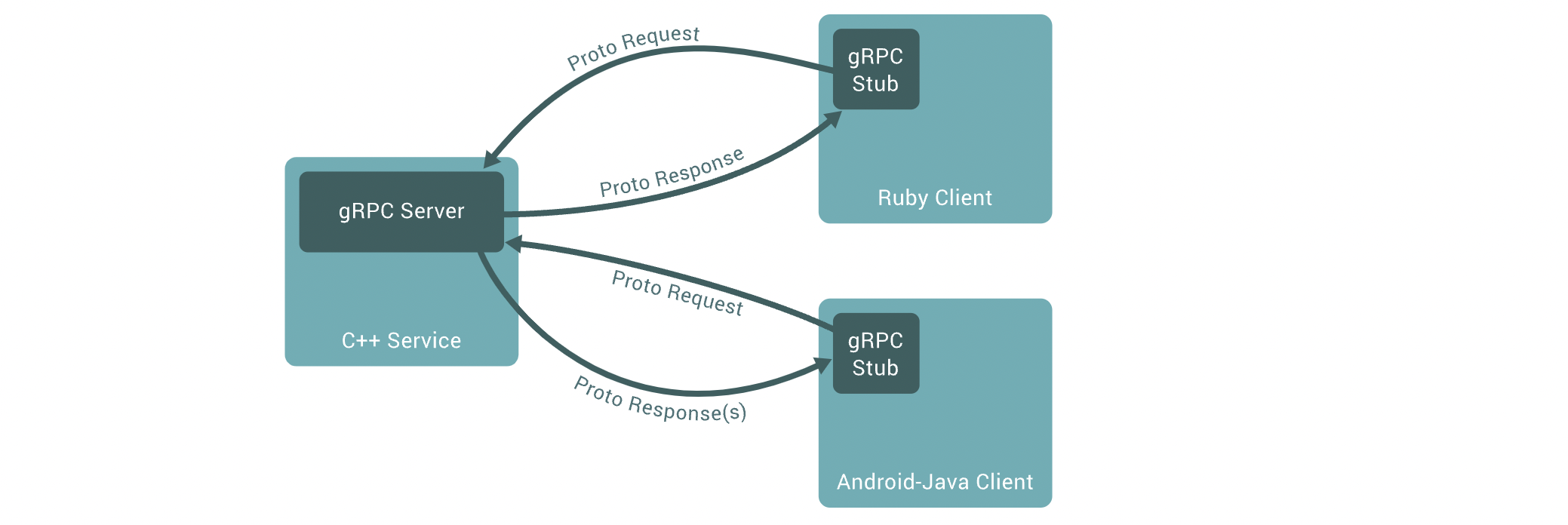
Monolithic 구조에서는 하나의 프로그램으로 동작하기 때문에 그 안에서 구조적인 2개의 서비스간의 데이터는 공유 메모리를 통해서 주고받을 수 있습니다. 따라서 이 경우 서비스간 메시지 전송 성능은 큰 이슈가 되지 않습니다. 반면 MSA에서는 여러 모듈로 분리되어있고 동일 머신에 존재하지 않을 수 있습니다. 따라서 일반적으로는 보편화된 방식인 REST 통신을 통해 메시지를 주고 받습니다. 문제는 Frontend 요청에 대한 응답을 만들어내기 위해 여러 마이크로 서비스간의 협력이 필요하다면, 구간별 REST 통신에 따른 비효율로 인해 응답속도가 저하된다는 점입니다.
HTTP 2.0
http/1.1은 기본적으로 클라이언트의 요청이 올때만 서버가 응답을 하는 구조로 매 요청마다 connection을 생성해야만 합니다. cookie 등 많은 메타 정보들을 저장하는 무거운 header가 요청마다 중복 전달되어 비효율적이고 느린 속도를 보여주었습니다. 이에 http/2에서는 한 connection으로 동시에 여러 개 메시지를 주고 받으며, header를 압축하여 중복 제거 후 전달하기에 version1에 비해 훨씬 효율적입니다. 또한, 필요 시 클라이언트 요청 없이도 서버가 리소스를 전달할 수도 있기 때문에 클라이언트 요청을 최소화 할 수 있습니다.
gRPC는 HTTP 2.0 기반위에서 동작하기 때문에 지금까지 HTTP 2.0의 특징에 대해서 살펴봤습니다. 짧게 정리하자면, Header 압축, Multiplexed Stream 처리 지원 등으로 인해 네트워크 비용을 많이 감소시켰습니다. 그렇다면 HTTP 2.0 특징을 제외한 gRPC만의 특징은 무엇이 있을까요?
먼저 REST API 통신의 문제점에 대해서 먼저 살펴본 다음 gRPC의 특징에 대해서 살펴보도록 하겠습니다. REST 구조에서는 JSON 형태로 데이터를 주고 받습니다. JSON은 데이터 구조를 쉽게 표현할 수 있으며, 사람이 읽기 좋은 표현 방식입니다. 하지만 사람이 읽기 좋은 방식이라는 의미는 머신 입장에서는 자신이 읽을 수 있는 형태로 변환이 필요하다는 것을 의미합니다. 따라서 Client와 Server간의 데이터 송수신간에 JSON 형태로 Serialization 그리고 Deserialization 과정이 수반되어야합니다. JSON 변환은 컴퓨터 CPU 및 메모리 리소스를 소모하므로 수많은 데이터를 빠르게 처리하는 과정에서는 효율이 떨어질 수 밖에 없습니다.
두 번째 이슈는 JSON 구조는 값은 String으로 표현됩니다. 따라서 사전에 타입 제약 조건에 대한 명확한 합의가 없거나 문서를 보고 개발자가 인지하지 못한다면, Server에 전달전에 이를 검증할 수 없습니다. 가령 위 예시와 같이 Server에서 zipCode는 숫자 타입으로 처리되어야하지만 Client에서는 이에 대한 제약 없이 문자열을 포함시켜 전달할 수 있음을 의미합니다.
그렇다면 gRPC 기술은 위 두 가지 이슈를 어떻게 풀어내었을까요?
Client에서 Server측의 API를 호출하기 위해서 기존에는 어떤 Endpoint로 호출해야할 지 그리고 전달 Spec에 대해서 API 문서 작성 혹은 Client와 Server 개발자간의 커뮤니케이션을 통해 정의해야했습니다. 그리고 이는 별도의 문서 생성이나 커뮤니케이션 비용이 추가로 발생합니다.
이러한 문제를 감소시키기 위해 다양한 방법이 존재합니다. 그 중 한가지는 Server의 기능을 사용할 수 있는 전용 Library를 Client에게 제공하는 것입니다. 그러면 Client는 해당 Library에서 제공하는 Util 메소드를 활용해서 호출하면 내부적으로는 Server와 통신하여 올바른 결과를 제공할 수 있습니다. 또한 해당 방법은 Server에서 요구하는 Spec에 부합되는 데이터만 보낼 수 있게 강제화 할 수 있다는 측면에서 스키마에 대한 제약을 가할 수 있습니다.
gRPC에서는 위 그림과 같이 이와 유사한 형태인 Stub 클래스를 Client에게 제공하여 Client는 Stub을 통해서만 gRPC 서버와 통신을 수행하도록 강제화 했습니다.
그렇다면 Stub 클래스는 무엇이고 위 그림에서 보이는 Proto는 무엇일까요?
Protocol Buffer
Protocol Buffer는 google 사에서 개발한 구조화된 데이터를 직렬화(Serialization)하는 기법입니다.
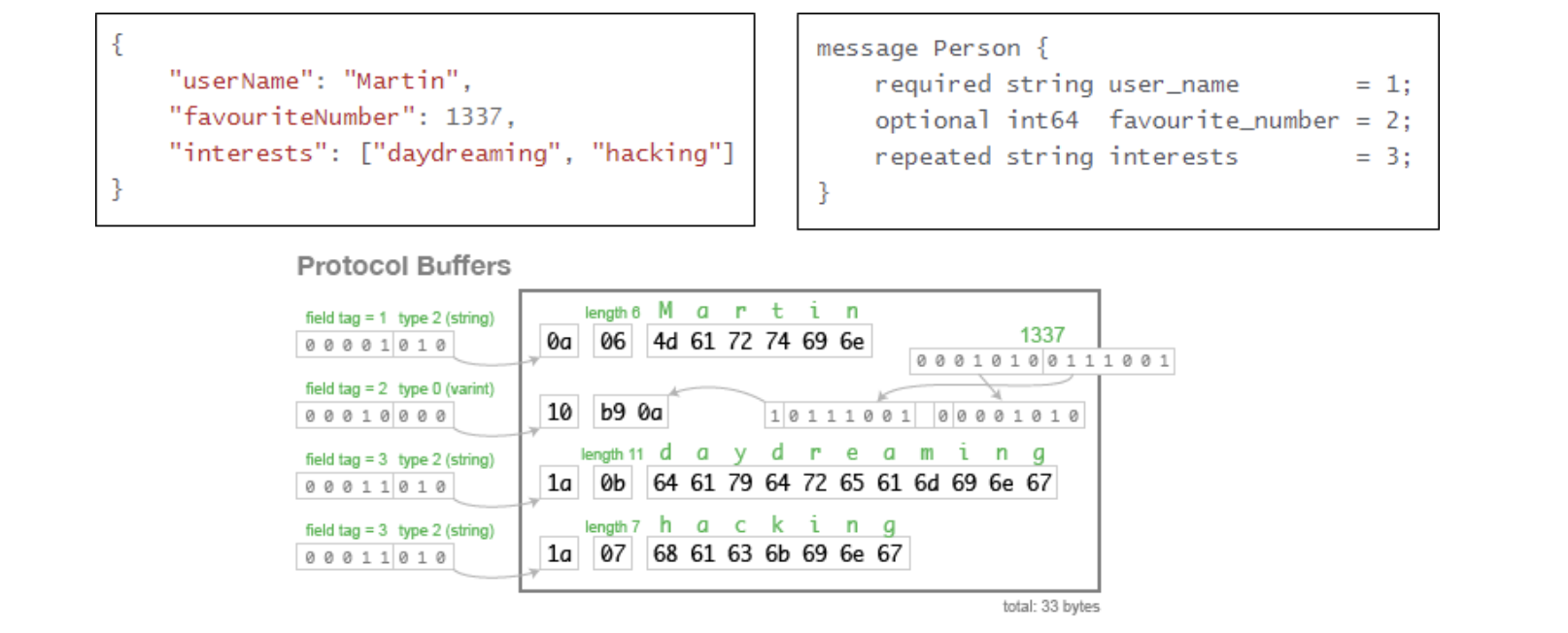
직렬화란, 데이터 표현을 바이트 단위로 변환하는 작업을 의미합니다. 아래 예제처럼 같은 정보를 저장해도 text 기반인 json인 경우 82 byte가 소요되는데 반해, 직렬화 된 protocol buffer는 필드 번호, 필드 유형 등을 1byte로 받아서 식별하고, 주어진 length 만큼만 읽도록 하여 단지 33 byte만 필요하게 됩니다.
Protocol Buffer는 Google이 공개한 데이터 구조로써, 특정 언어 혹은 특정 플랫폼에 종속적이지 않은 데이터 표현 방식입니다. 하지만 Protocol Buffer는 특정 언어에 속하지 않으므로 Java나 Kotlin, Golang 언어에서 직접적으로 사용할 수 없습니다.
따라서 Protocol Buffer를 언어에서 독립적으로 활용하기 위해서는 이를 기반으로 Client 혹은 Server에서 사용할 수 있는 Stub 클래스를 생성해야합니다. 이때 protoc 프로그램을 활용해서 다양한 언어에서 사용할 수 있는 Stub 클래스를 자동 생성할 수 있습니다.
Stub 클래스를 생성하면, 해당 클래스 정보를 Server와 Client에 공유한 다음 Stub 클래스를 활용하여 서로 양방향 통신을 수행할 수 있습니다.
지금까지 학습한 Protocol Buffer 내용을 정리하면 다음과 같은 장점을 지닌 것을 확인할 수 있습니다.
- 스키마 타입 제약이 가능하다
- Protocol buffer가 API 문서를 대체할 수 있다.
위 두가지 특징은 이전에 REST에서 다룬 이슈 중 하나인 API Spec 정의 및 문서 표준화 부재의 문제를 어느정도 해소해줄 수 있습니다. 그렇다면 또 하나의 이슈인 JSON Payload 비효율 문제와 대비하여 gRPC는 어떠한 이점을 지니고 있을까요?
JSON 타입은 위와같이 사람이 읽기는 좋지만 데이터 전송 비용이 높으며, 해당 데이터 구조로 Serialization, Deserialization 하는 비용이 높음을 앞서 지적했습니다.
gRPC의 통신에서는 데이터를 송수신할 때 Binary로 데이터를 encoding 해서 보내고 이를 decoding 해서 매핑합니다. 따라서 JSON에 비해 payload 크기가 상당히 적습니다.
또한 JSON에서는 필드에 값을 입력하지 않아도 구조상에 해당 필드가 포함되어야하기 때문에 크기가 커집니다. 반면 gRPC에서는 입력된 값에 대해서만 Binary 데이터에 포함시키기 때문에 압축 효율이 JSON에 비해 상당히 좋습니다.
결론적으로 이러한 적은 데이터 크기 및 Serialization, Deserialization 과정의 적은 비용은 대규모 트래픽 환경에서 성능상 유리합니다.
gRPC 이점
- 성능
- 네트워크 요청으로 보내기 위해 Protobuf를 직렬화(Serialization) 및 역직렬화(Deserialization)하는 작업은 JSON 형태의 직렬화/역직렬화 보다 빠르다. 또한 gRPC의 네트워크 속도가 HTTP POST/GET 속도보다 빠르다. 특히 POST 요청 시 많은 차이를 보인다. 자세한 내용은 Mobile gRPC Benchmarks 문서를 참고한다.
- API-우선 방식
- Protobuf를 통해 기능을 개발하기 전에 API를 먼저 정의할 수 있다. API가 먼저 정의될 경우 개발팀이 병렬적으로 일을 진행할 수 있고, 개발 속도가 빨라지며, API를 좀 더 안정적으로 제공할 수 있다. 자세한 내용은 Understanding the API-First Approach to Building Products 문서를 참고한다.
- REST API 지원
- Protobuf로 정의된 API는 envoyproxy나 grpc-gateway 같은 gateway 를 통해 REST API로 제공 가능하다. gRPC로 정의된 API를 OpenAPI 프로토콜로 변환하여 REST API를 사용하는 클라이언트에도 API-우선 방식을 적용할 수 있다.
참고
- Austin G. Walters, Intro to IPC
- DR-kim, 프로세스간 통신 방법
- 우당탕탕 히온이네, [운영체제] IPC 프로세스간 통신
- bycho211, 프로세스간 통신(IPC)
- 얼음연못, [개발상식] 프로세스간 통신(IPC)
- nesoy, RPC란?
- jakeseo, RPC란?
- w3, What is Remote Procedure Call?
- grpc공식문서, What is gRPC?
- navercloud, [네이버클라우드 기술&경험] 시대의 흐름, gRPC 깊게 파고들기 #1
- cla9, 1. gRPC 개요
- buzzvil Tech, gRPC