



































Table of Contents
ORM
- ORM(Object-Relational Mapping)은 개발자가 원시 SQL 쿼리를 작성하는 대신 객체 지향 프로그래밍(OOP) 개념을 사용하여 데이터베이스와 상호 작용할 수 있도록 하는 프로그래밍 기술입니다.
-
데이터베이스 테이블을 클래스에 매핑하고 행을 프로그래밍 언어의 개체에 매핑합니다.
- ORM을 사용하면 다음과 같은 장점을 얻을 수 있습니다.
- 추상화: ORM은 더 높은 수준의 추상화를 제공하여 데이터베이스와의 상호 작용을 단순화합니다. 이를 통해 개발자는 SQL 쿼리 대신 개체 및 클래스로 작업할 수 있으므로 코드를 더 읽기 쉽고 유지 관리할 수 있습니다.
- 보일러 플레이트 코드 감소: ORM은 대부분의 일반적인 데이터베이스 작업을 ORM 시스템이 처리하기 때문에 반복적인 보일러 플레이트 코드를 줄일 수 있습니다.
- 이식성: ORM 시스템은 일반적으로 여러 데이터베이스 시스템을 지원하므로 개발자는 코드 변경을 최소화하면서 서로 다른 데이터베이스 간에 전환을 쉽게 할 수 있습니다. 이를 통해 다양한 환경이나 요구 사항에 맞게 응용 프로그램을 더 쉽게 조정할 수 있습니다.
- 생산성: ORM을 사용하면 개발자는 복잡한 SQL 쿼리를 작성하는 대신 애플리케이션의 비즈니스 논리에 집중할 수 있습니다. 이는 생산성 향상으로 이어질 수 있습니다.
- 유지 관리성: ORM은 객체 지향 설계 패턴 사용을 촉진하여 더 잘 구조화되고 유지 관리하기 쉬운 코드베이스를 만듭니다.
- 이런 이유들로 개발자들은 ORM을 사용하는 경우가 많습니다. 특히 최근 트랜드는 높은 생산성과 MSA를 위한 다양한 DB를 사용하기 위한 이식성도 중요해 졌기 때문에 ORM을 사용하는 것이 일반적이기도 합니다.
N+1 문제
- ORM을 사용해 데이터베이스의 데이터를 조회할 때, 쿼리 결과로 N개의 데이터를 반환하고, N개의 데이터 각각에 대해 연관 관계를 가지는 다른 테이블에서 데이터를 가져오기 위해 N번의 쿼리를 추가로 실행하게 되는 문제를 말한다
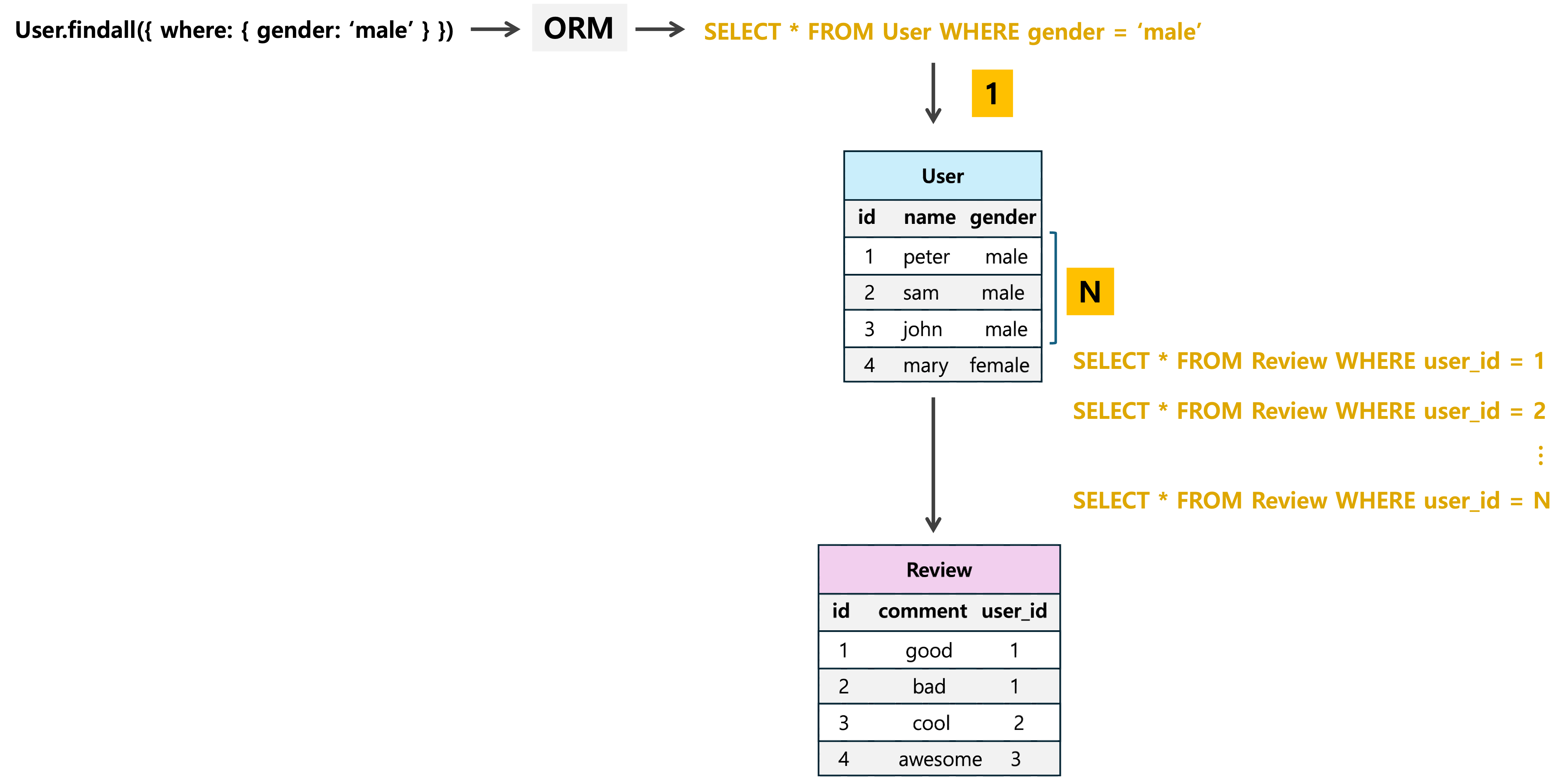
- 위의 예시를 봤을 때,
User를 쿼리할 때, 유저가 작성한Review데이터를 가져오기 위해 추가로 N번의 쿼리를 실행한다 - 쿼리에 따라
User목록만 필요한 경우가 있고,User와 유저가 작성한Reivew까지 필요한 쿼리가 있을 수 있다 - 또
Review가 필요할 때 위와 같이 N개의 쿼리를 추가로 실행하는 것이 아니라, 조인 방식으로 처음부터 같이 읽어오고 싶을 수도 있다
- 정리하면 가장 좋은 방식은, 연관 관계의 데이터는 필요할 때만 가져오고, 가져올 때는 조인 방식으로 가져오도록 하고 싶다
- TypeORM은 이를 지원한다
find메서드의relations옵션을 사용하거나,QueryBuilder의leftJoinAndSelect메서드를 사용하면 된다
- 다른 ORM 에서는 Lazy loading, Eager loading 이라는게 있는데, N+1 문제는 Lazy loading 때문에 일어나는 문제이다
- 그러면 그냥 무조건 Eager loading 하면 되잖아? 라고 할 수 있지만, 각각의 장단점이 있다
- Lazy: 초기에 데이터를 빨리 읽어오지만, 이 후 연관 데이터 읽어오려면 추가로 쿼리 요청해야 하기 때문에 이 때 비교적 느리다
- Eager: 처음부터 연관 데이터 다 조인 방식으로 읽어와서 느리지만, 이 후 연관 데이터 읽어올 때 추가적인 쿼리가 필요없어서 빠르다
- TypeORM의 경우
- find 메서드와 QueryBuilder 모두 lazy, eager 다 아니다
- lazy가 아닌 이유는, lazy는 연관 관계 데이터 접근하면 추가로 쿼리 요청 보내서 읽어온다
- 하지만 TypeORM은 추가 쿼리 보내지 않고 그냥 undefined 반환한다
- 하지만 find + relations, QueryBuilder + leftJoinAndSelect 조합은 eager loading 이다
- (relations 없이, 엔티티 정의할 때 OneToMany 데코레이터에 eager: true 옵션 추가해도 되지만 이렇게 하면 eager loading을 쿼리마다 선택적으로 적용한게 아니라, 모든 쿼리에 일괄 적용되기 때문에 좋은 방법처럼 보이진 않는다)
- lazy loading은 아래와 같은 방법으로 사용 가능하다. 하지만 lazy loading은 N+1 문제를 야기한다
// Pseudo code @Entity() class User { @OneToMany(() => Review, (reviews) => reviews.user) reviews: Promise<Review[]> // 이렇게 Promise를 타입으로 하는 것이 lazy loading을 나타낸다 } ... const user = await User.find() // 1 const reviews = await user?.reviews // N
SQL vs ORM
- ORM은 추가적인 레이어가 들어간 것이기에 성능의 손해가 발생할 수 있다
- 또한 ORM이 작성해주는 SQL문이, 개발자가 직접 작성하는 SQL보다 성능이 떨어질 수도 있다
- 성능 문제: ORM에서 생성된 쿼리는 때때로 신중하게 작성된 SQL 쿼리보다 효율이 떨어질 수 있습니다. 이로 인해 리소스 사용량이 증가하고 응답 시간이 느려져 데이터베이스의 성능에 부정적인 영향을 미칠 수 있습니다.
- 제어력 상실: ORM은 데이터베이스 작업의 많은 세부 사항을 추상화하여 데이터베이스에 대한 세밀한 제어력을 상실하게 합니다. DBA들은 쿼리 최적화와 데이터베이스의 성능 관련 측면에 대한 제어력이 덜한 것처럼 느낄 수 있습니다.
- 복잡성: ORM은 응용 프로그램에 추가적인 복잡성을 도입하여, DBA가 데이터베이스 상호 작용과 관련된 문제를 이해하고 문제를 해결하는 것이 어렵게 만듭니다. 이로 인해 데이터베이스 문제를 해결하는 데 필요한 시간과 노력이 증가할 수 있습니다.
- 데이터베이스 기능 지원 제한: ORM은 특정 데이터베이스 시스템의 모든 기능을 완전히 지원하지 않을 수 있어 DBA가 이러한 제한을 해결하거나 원시 SQL 쿼리(Raw Query)를 작성해야 할 수 있습니다. 이는 DBA가 선택한 데이터베이스 시스템의 기능을 완전히 활용하는 데 방해가 될 수 있습니다.
- 적절하지 않은 데이터베이스 설계: ORM은 개발자들이 객체 지향 설계에 집중하도록 유도하기 때문에, 때로는 최적의 데이터베이스 설계 하는데 있어 희생을 감수 할 수 있습니다. 이로 인해 최적화되지 않은 데이터베이스 스키마와 데이터 모델이 발생할 수 있고, 성능 및 확장성 문제를 초래할 수 있습니다.
- 데이터베이스 문제 숨기기: ORM은 데이터베이스 작업의 복잡성을 많이 추상화하기 때문에 개발자들은 잠재적인 문제나 모범 사례에 대해 인식하지 못할 수 있습니다. 이로 인해 숨겨진 문제와 성능 병목 현상이 발생하며, 이러한 문제는 응용 프로그램이 높은 부하가 발생하는 시기 혹은 서비스를 확장할 시기가 되서야 문제가 나타날 수 있습니다.