



































Table of Contents
- Why Connector?
- Kafka Connect
- Debezium
- 도커 컴포즈 파일
- kafka 컨테이너에서 워커 실행 모드 설정
- kafka 컨테이너에서 커넥터 워커 실행
- connect 제외한 아무 컨테이너(나의 경우 kafka 컨테이너)에서 REST API를 이용해 커넥터 등록/실행
- 기타 커넥터 관련 REST API
- 커넥터와 백엔드(Java Spring)의 관계
- 참고
Why Connector?
커넥터 없이도 프로듀서 컨슈머 사용 가능
하지만 커넥터를 이용하면 카프카를 사용하면서 발생할 수 있는 장애에 대한 복구를 비롯한 필요한 기능들을 따로 개발할 필요없이 사용가능
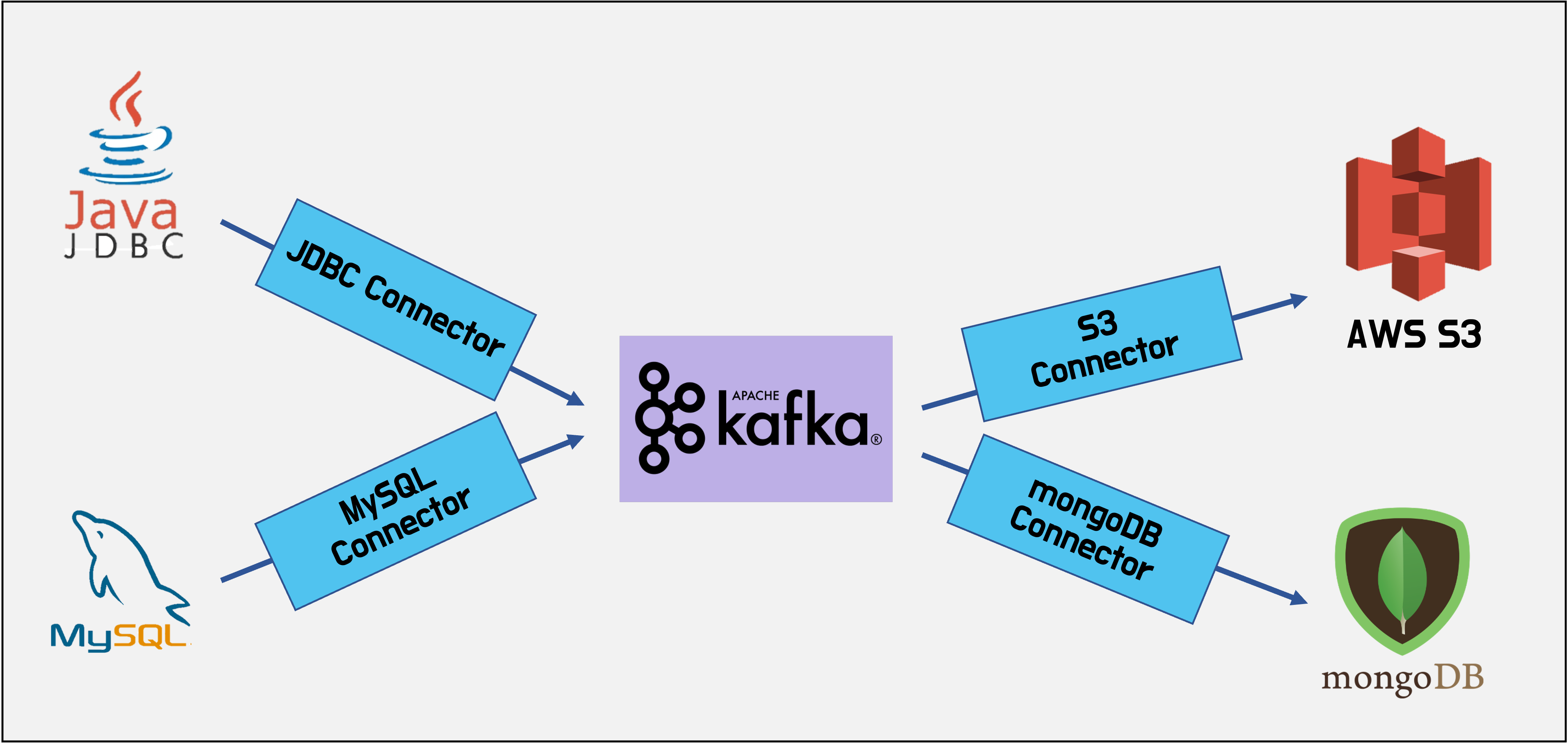
Kafka Connect
- Kafka Connect는 다른 데이터 시스템을 Kafka와 통합하는 과정을 표준화한 프레임워크
- 통합을 위한 Connector 개발, 배포, 관리를 단순화
Kafka Connect 구성요소
- Connector: Task를 관리하여 데이터 스트리밍을 조정하는 jar파일
- Task: 데이터 시스템간의 전송 방법을 구현한 구현체
- Worker: Connector와 Task를 실행하는 프로세스
- Converter: 데이터 포맷을 변환하는데 사용하는 구성요소
- Trasform: 데이터를 변환하는데 사용하는 구성요소
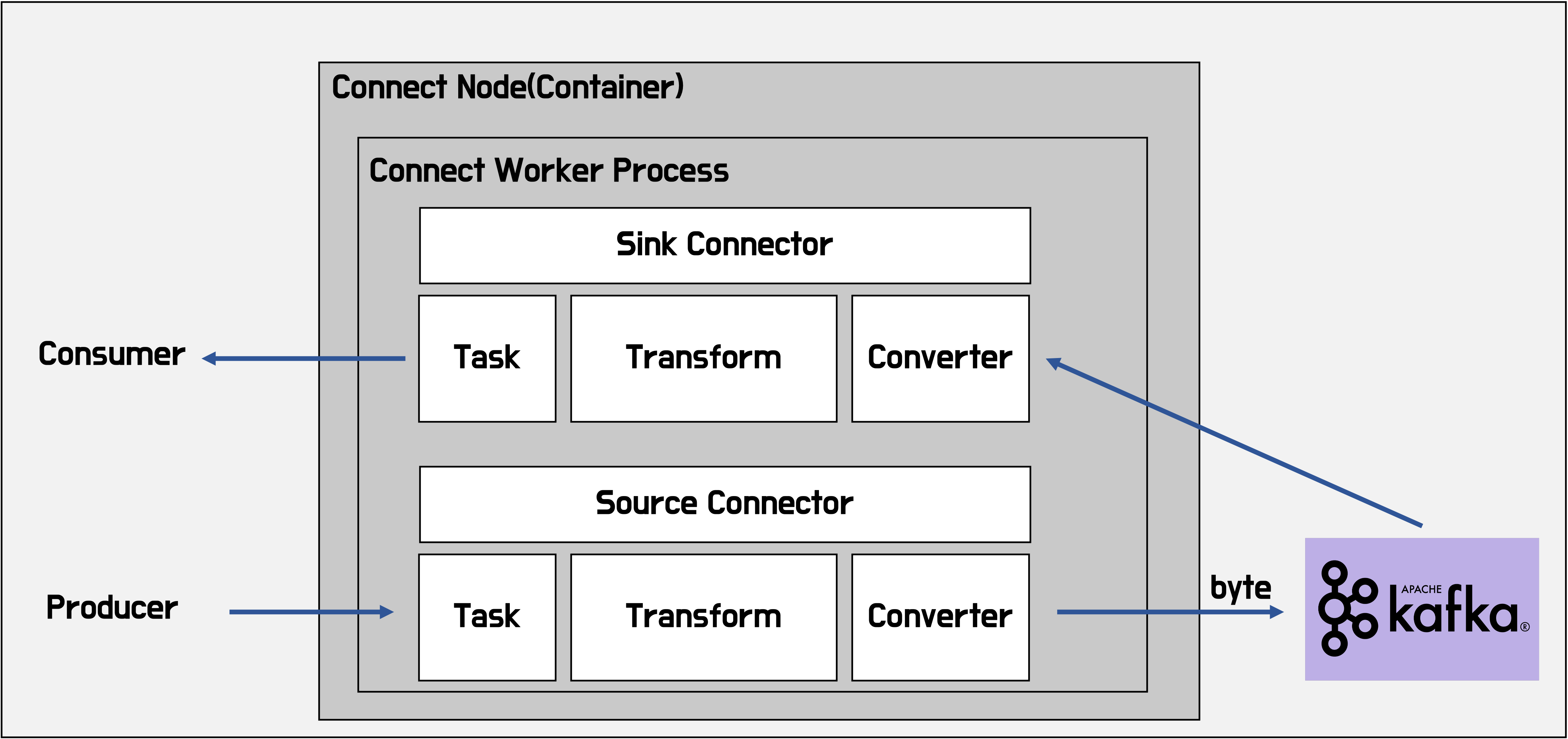
Connect? Connector?
커넥트는 커넥터를 실행시키기 위한 환경(프레임워크)을 제공해줌. 커넥트 위에서 커넥터 설치하고 커넥터(jar파일) 실행하면 됨
커넥트 이미지로 인스턴스 띄우고 거기서 각종 커넥터 다운로드 받아서 커넥터를 몽고db, mysql, s3같은데 RESTapi로 등록
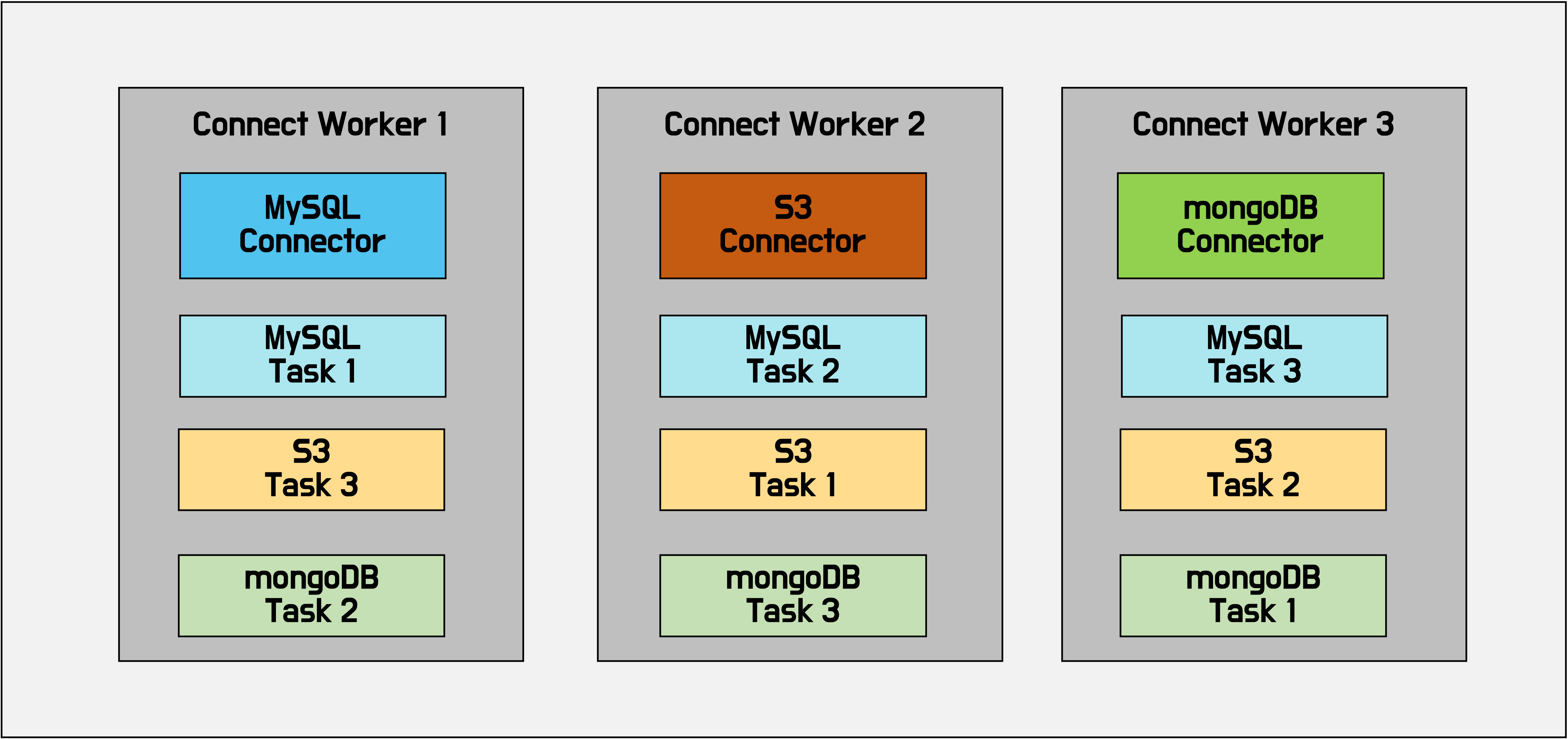
Standalone과 Distributed Workers
Worker 프로세스를 한 개만 띄우는 Standalone 모드와 여러개 실행시키는 Distributed 모드가 있다.
보통 확장성과 내결함성을 이유로 Distributed 모드를 많이 사용한다.
Debezium
Debezium은 변경 데이터 캡처를 위한 오픈 소스 분산 플랫폼이다.
Debezium 에서 변경된 데이터 캡쳐를 위해 mysql의 경우 binlog, postgresql의 경우 replica slot(logical)을 이용하여 데이터베이스에 커밋하는 데이터를 감시하여 Kakfa, DB, ElasticSearch 등 미들웨어에 이벤트를 전달한다
도커 컴포즈 파일
version: '3.2'
services:
mongodb:
image: mongo:latest
hostname: mongodb
ports:
- "27017:27017"
environment:
MONGO_INITDB_ROOT_USERNAME: root
MONGO_INITDB_ROOT_PASSWORD: root
tty: true
zookeeper:
image: zookeeper:3.7
hostname: zookeeper
ports:
- "2181:2181"
environment:
ZOO_MY_ID: 1
ZOO_PORT: 2181
volumes:
- ./data/zookeeper/data:/data
- ./data/zookeeper/datalog:/datalogco
kafka:
image: wurstmeister/kafka
hostname: kafka
ports:
- "9092:9092"
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
tty: true
volumes:
- ./data/kafka/data:/tmp/kafka-logs
depends_on:
- zookeeper
connect:
image: confluentinc/cp-kafka-connect:latest.arm64
hostname: connect1
depends_on:
- kafka
environment:
CONNECT_BOOTSTRAP_SERVERS: kafka:29092
CONNECT_REST_ADVERTISED_HOST_NAME: connect1
CONNECT_GROUP_ID: connect-cluster
CONNECT_KEY_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_VALUE_CONVERTER: org.apache.kafka.connect.json.JsonConverter
CONNECT_CONFIG_STORAGE_TOPIC: connect-configs
CONNECT_OFFSET_STORAGE_TOPIC: connect-offsets
CONNECT_STATUS_STORAGE_TOPIC: connect-status
CONNECT_CONFIG_STORAGE_REPLICATION_FACTOR: 1
CONNECT_OFFSET_STORAGE_REPLICATION_FACTOR: 1
CONNECT_STATUS_STORAGE_REPLICATION_FACTOR: 1
CONNECT_PLUGIN_PATH: /usr/share/java/,/usr/share/confluent-hub-components/mongodb-kafka-connect-mongodb/lib/
CONNECT_REST_PORT: 8083
ports:
- 18083:8083
volumes:
- ./connectors/1:/usr/share/confluent-hub-components
command:
- bash
- -c
- |
confluent-hub install --no-prompt mongodb/kafka-connect-mongodb:1.7.0
/etc/confluent/docker/run &
sleep infinity
producer:
build:
context: ./
dockerfile: Dockerfile_producer
stdin_open: true
tty: true
consumer:
build:
context: ./
dockerfile: Dockerfile_consumer
stdin_open: true
tty: true
volumes:
mongodb:
kafka 컨테이너에서 워커 실행 모드 설정
cd opt/kafka/config
vi connect-distributed.properties
# connect 컨테이너에서 커넥터(jar파일)가 설치되어 있는 경로 설정
plugin.path=/usr/share/java/,/usr/share/confluent-hub-components/mongodb-kafka-connect-mongodb/lib/
# 컨버터 설정
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false
kafka 컨테이너에서 커넥터 워커 실행
./bin/connect-distributed.sh ./config/connect-distributed.properties
connect 제외한 아무 컨테이너(나의 경우 kafka 컨테이너)에서 REST API를 이용해 커넥터 등록/실행
curl -X POST -H'Accept:application/json' -H'Content-Type:application/json' http://connect1:8083/connectors
-w "\n"
-d '{"name": "mongo-sink",
"config": {
"connector.class":"com.mongodb.kafka.connect.MongoSinkConnector",
"connection.user": "root",
"connection.password": "root",
"connection.uri":"mongodb://root:root@mongodb:27017",
"database":"quickstart",
"collection":"topicData",
"topics":"taxi",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter.schemas.enable": "false"
}
}'
기타 커넥터 관련 REST API
# 커넥터 상태 확인(커넥터 등록과 태스크 실행이 RUNNING이면 성공)
curl -X GET http://connect1:8083/connectors/mongo-sink/status
# 커넥터 삭제
curl -X DELETE http://connect1:8083/connectors/mongo-sink
커넥터와 백엔드(Java Spring)의 관계
커넥터가 있으면 알아서 커넥터가 토픽에서 데이터를 가져와 DB로 잘 반영을하는 것 같다.
이런거보면 딱히 스프링부트 같은 걸 이용해서 백엔드 프로그램을 개발하지 않아도 되는 것 같아보인다.
하지만 만약 내가 스프링부트 같은 거를 엄청 잘 알아서 직접 개발하는데 불편함이 없다면 왠만한 것들은 스프링 부트를 이용하고 부분적으로 특정 프로듀서/컨슈머는 커넥터를 사용하는 것이 아마 가장 좋은 방법이 아닐까 라는 생각이 든다.
나는 지금 스프링부트를 모른다. 심지어 자바 언어도 써본 적이 없다. 커넥터는 아예 러닝 커브가 없는 것은 아니지만 훨씬 쉽다.
하지만 백엔드의 중요한 철학들을 공부하는 것은 굉장히 중요해보인다.
결론은 지금 당장 구현이 필요한 부분들은 커넥터로 구현을 하고, 백엔드 공부는 스프링 부트를 통해서 계속 하자.
백엔드 공부를 스프링 부트로 하기로 한 이유는, 내가 사용하고 있는 언어는 파이썬이지만 데이터 엔지니어링 공부에서 자바 언어는 필요해보인다. (데이터 엔지니어링 분야의 관련 오픈 소스들이 자바로 많이 개발됨)
파이썬으로 백엔드를 구현하도록 해주는 장고나 플라스크도 있지만, 아직은 스프링 부트를 사용하는 비중이 더 커보이고 뭔가 공부하는 관점에서는 스프링 부트가 더 도움이 많이 될 것 같다.
참고
- Confluent 공식문서: Kafka Connect Tutorial on Docker
- Connect 도커 이미지
- Confluent 공식문서: MongoDB 커넥터
- MongoDB 공식문서: MongoDB 커넥터를 위한 Configuration
- kudl: CDC - debezium 설정
- Confluent 공식문서: 커넥터 관련 강의
- Confluent 공식문서: Connect 관련 configuration
- sup2is: Kafka Connect로 데이터 허브 구축하기
- 깃허브: mongodb-university/kafka-edu
- Kafka Connect Deep Dive – Converters and Serialization Explained
- 정몽실이: 카프카 커넥트 실행
- Stackoverflow: Connector and Spring Kafka