



































Table of Contents
Exploratory Data Analysis
데이터 샘플
df.head(3)

df.sample(3)

데이터 길이
len(df)
데이터 컬럼별 특성
df.info()
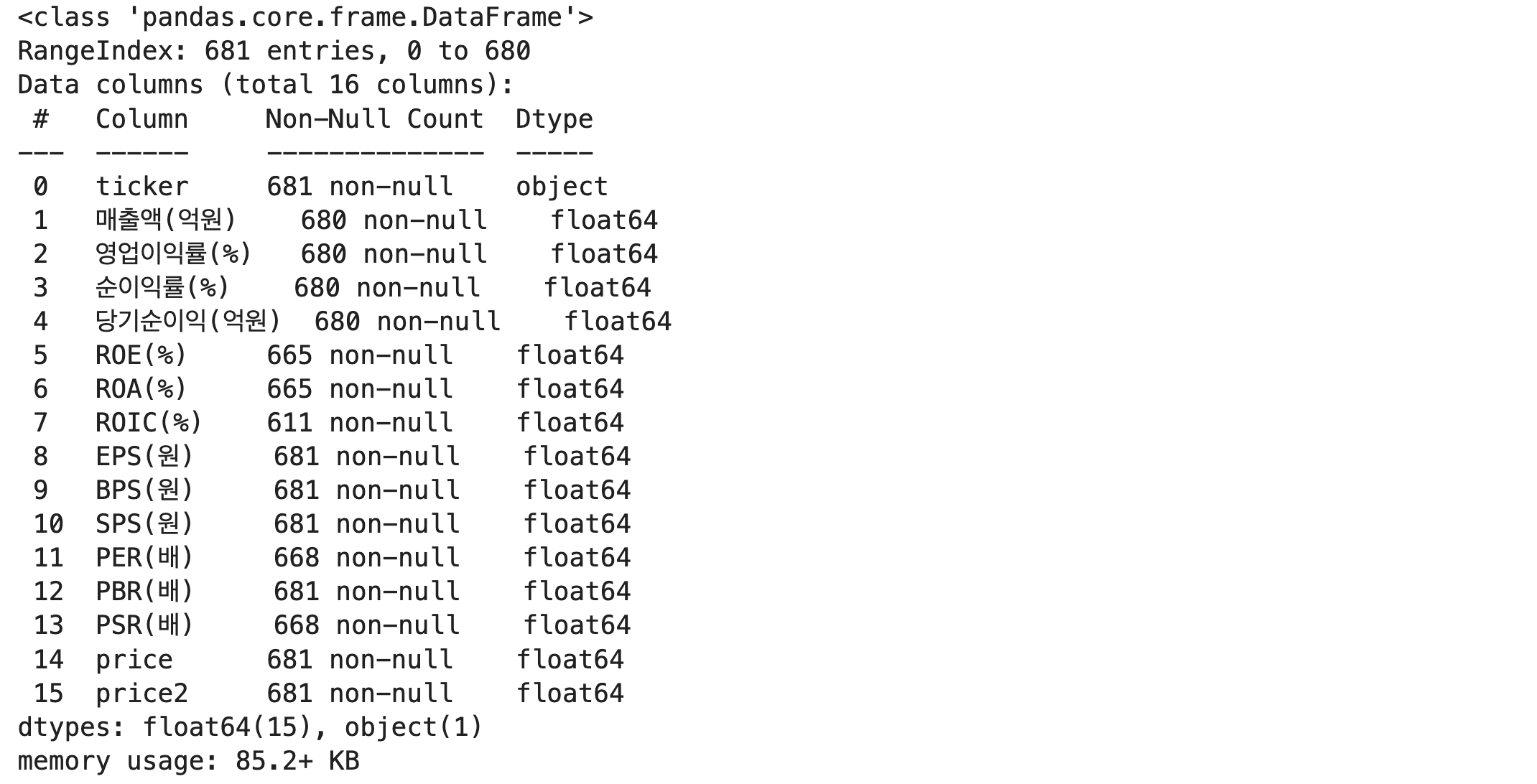
데이터 통계적 특성
df.describe()
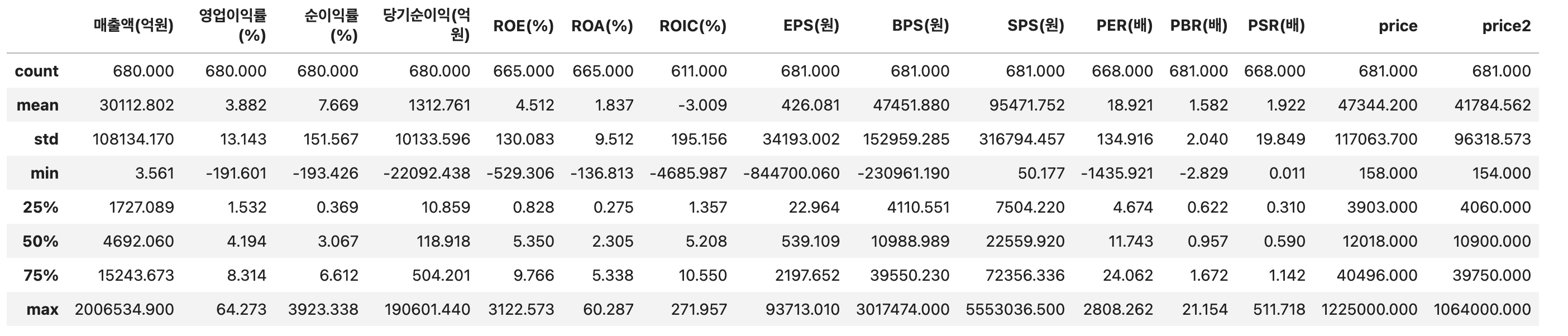
df.describe(include=['object', pd.Categorical])

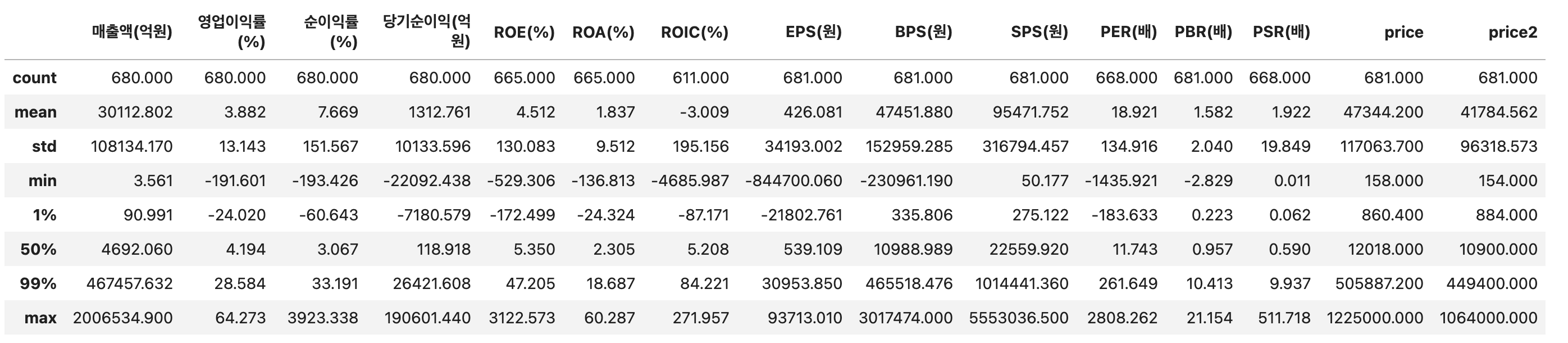
df.describe(percentiles=[0.01, 0.5, 0.99])
데이터 유니크
df.nunique()

df['ticker'].nunique()
------------------------
681
df['ticker'].unique()

데이터 빈도수
df.head(10)

df['Sector'].value_counts()

df['Sector'].value_counts(normalize=True)

데이터 정렬
df.head(3)
# 매출액(억원) 에 대해서 가장 큰 값 5개를 desceding order로 추출 (전체를 정렬하지 않음)
df.nlargest(5, '매출액(억원)')

# 5개에서 PER(배) 가장 작은 값 3개를 desceding order로 추출
df.nlargest(5, '매출액(억원)').nsmallest(3, 'PER(배)')

# 매출액(억원)에 대해서 전체 데이터 정렬
df.sort_values('매출액(억원)', ascending=False).head(3)

# 매출액(억원)에 대해서 내림차순 정렬한 후, 그 상태에서 매출액(억원)이 같은 데이터끼리 PER(배)에 대해 오름차순 정렬
# 이런 여러 컬럼에 대한 정렬이 의미를 가지려면 정렬하는 앞의 컬럼들이 범주형 데이터여야 한다
# ex. [계열사, 매출액] 이런식으로
df.sort_values(['매출액(억원)', 'PER(배)'], ascending=[False, True]).head(3)

df.sort_index(inplace=True).head(3)

df.index.is_monotonic_increasing
----------------------------------
True