



































Table of Contents
RNN
시퀀스 데이터 vs 시계열 데이터
- 시퀀스 데이터는 순서만 중요한 데이터 (문장, 음성)
- 시계열 데이터는 순서뿐 아니라 데이터가 발생한 시간도 중요한 데이터 (주식, 센서 데이터)
시퀀스 데이터
- 시퀀스 데이터는 IID가정을 대체로 위배하기 때문에, 순서를 바꾸면 데이터의 확률 분포도 바뀌게 됩니다.
- 이전 시퀀스의 정보를 가지고 앞으로 발생할 데이터의 확률 분포를 다루기 위해 조건부 확률을 이용할 수 있습니다.
- 다음과 같은 문제를 해결하기 위한 모델을 만든다고 생각해 봅시다.
이미지에 대한 설명문 달기
주가 예측하기
한국어 영어로 번역하기
다음과 같은 문제는 입력과 출력이 시퀀스 형태를 가지고 있습니다. 이러한 시퀀스 데이터를 처리하기 위해 고안된 모델을 시퀀스 모델이라고 합니다. 그 중에서도 RNN은 딥러닝에서 가장 기본적인 시퀀스 모델입니다.
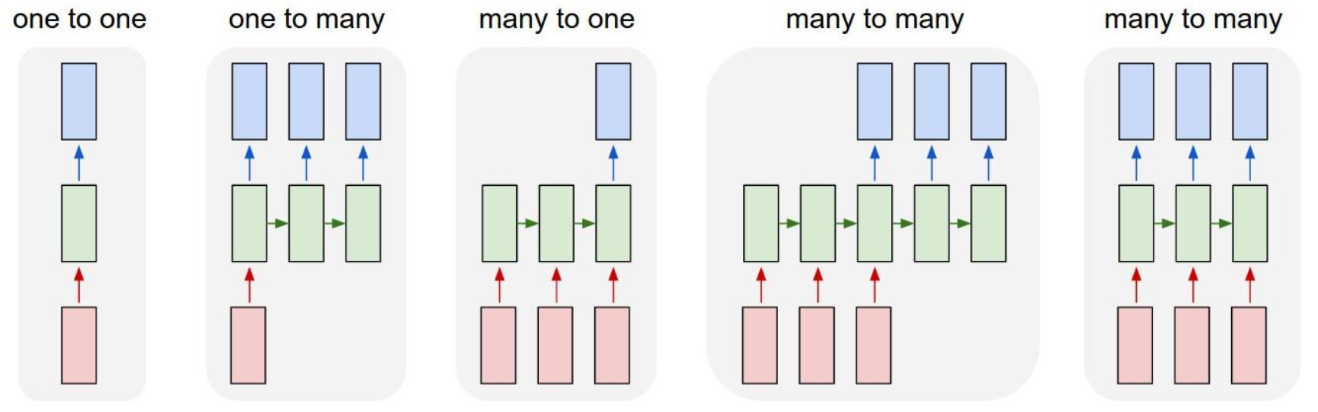
one to one: 비 시퀀스 데이터를 다루는 경우
one to many: 이미지 캡셔닝
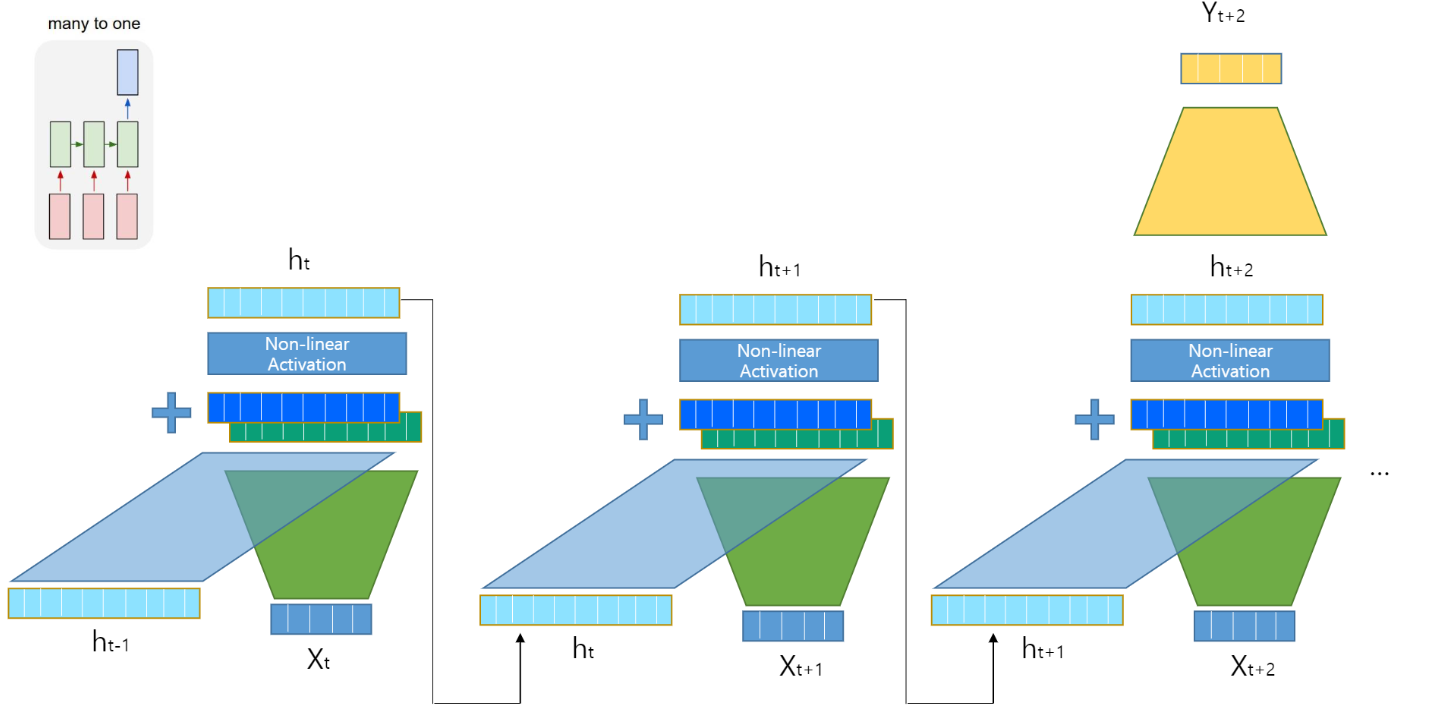
many to one: 주가 예측, 텍스트 분류
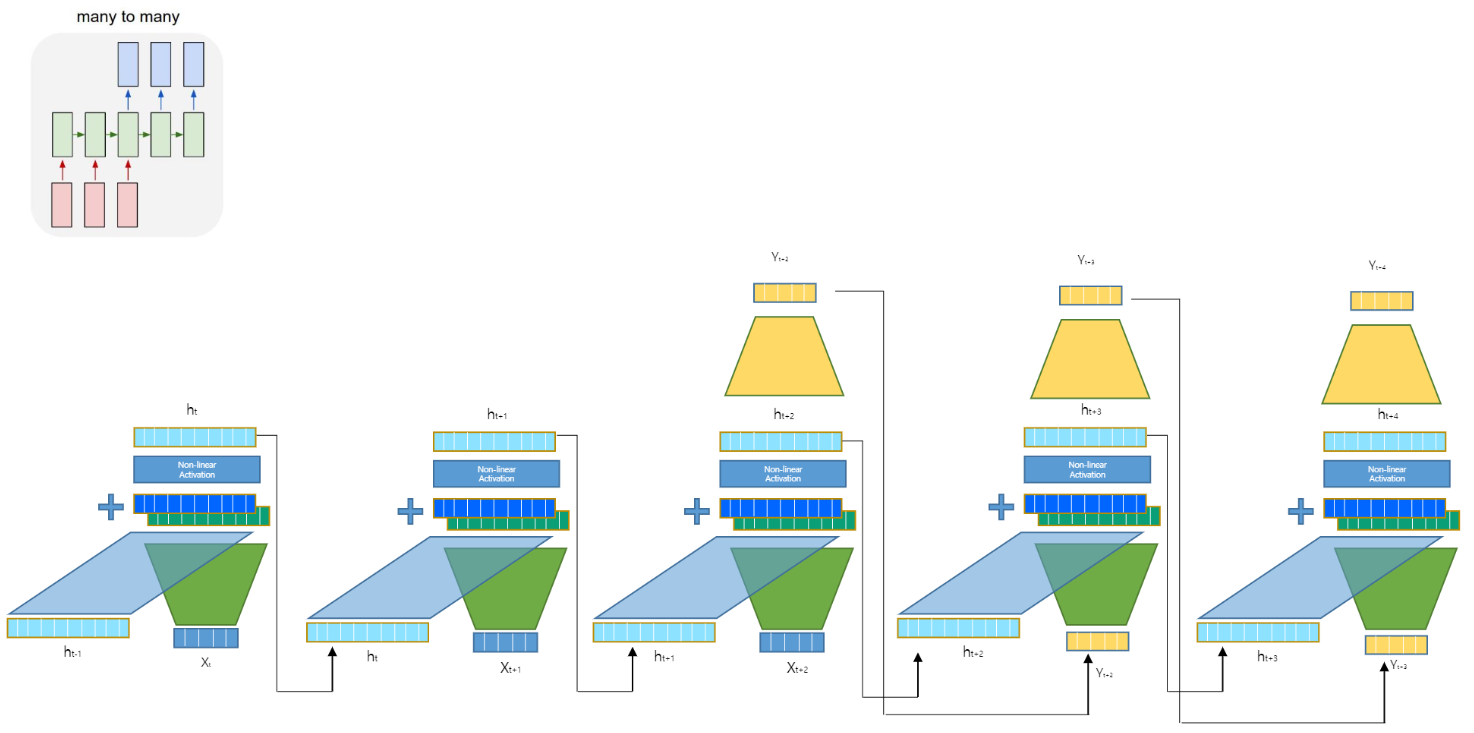
many to many: 번역
바닐라 RNN
그동안 신경망들은 은닉층에서 활성화 함수를 지난 값은 오직 출력층 방향으로만 향했습니다. 이와 같은 신경망들을 피드 포워드 신경망(Feed Forward Neural Network)이라고 합니다. 그런데 그렇지 않은 신경망들도 있습니다. RNN(Recurrent Neural Network)이 그 중 하나입니다.
RNN은 해당 층의 입력 데이터와 이전 층에서의 출력을 함께 입력으로 사용합니다.
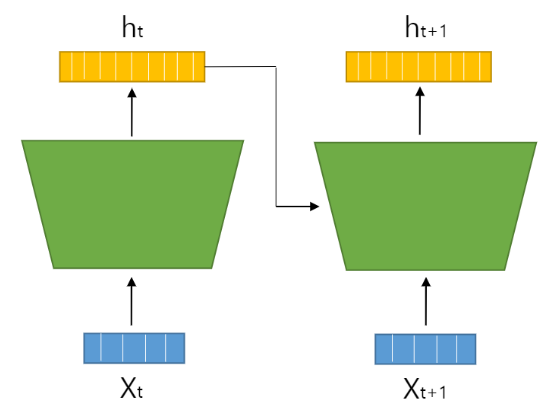
그리고 이전 층의 출력과 해당 층의 입력은 다음과 같이 결합되게 됩니다.
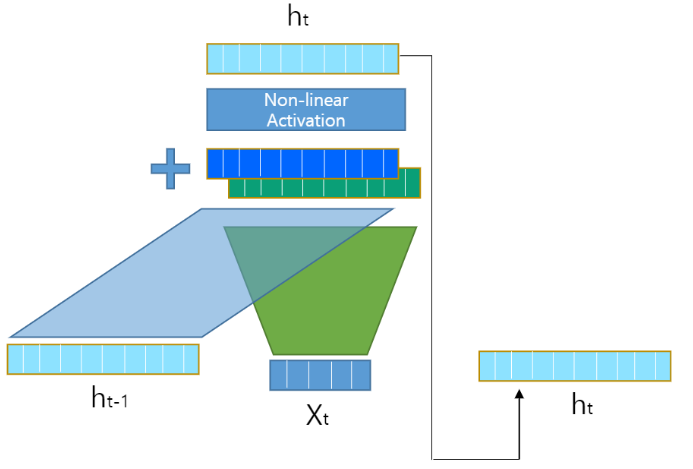
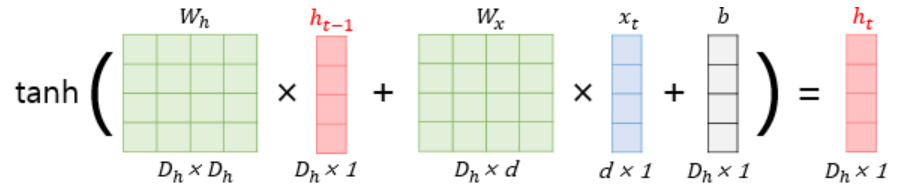
(참고로 W_d와 W_h를 concatenation해서 쓸 수도 있습니다.)
이를 모델에 적용해 다시 한 번 살펴보면 다음과 같습니다.
이를 식으로 표현하면 다음과 같습니다.
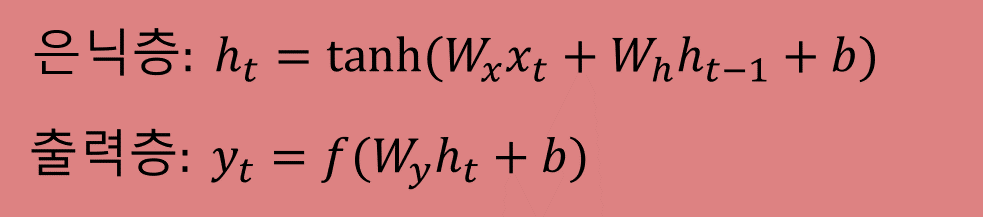
평가
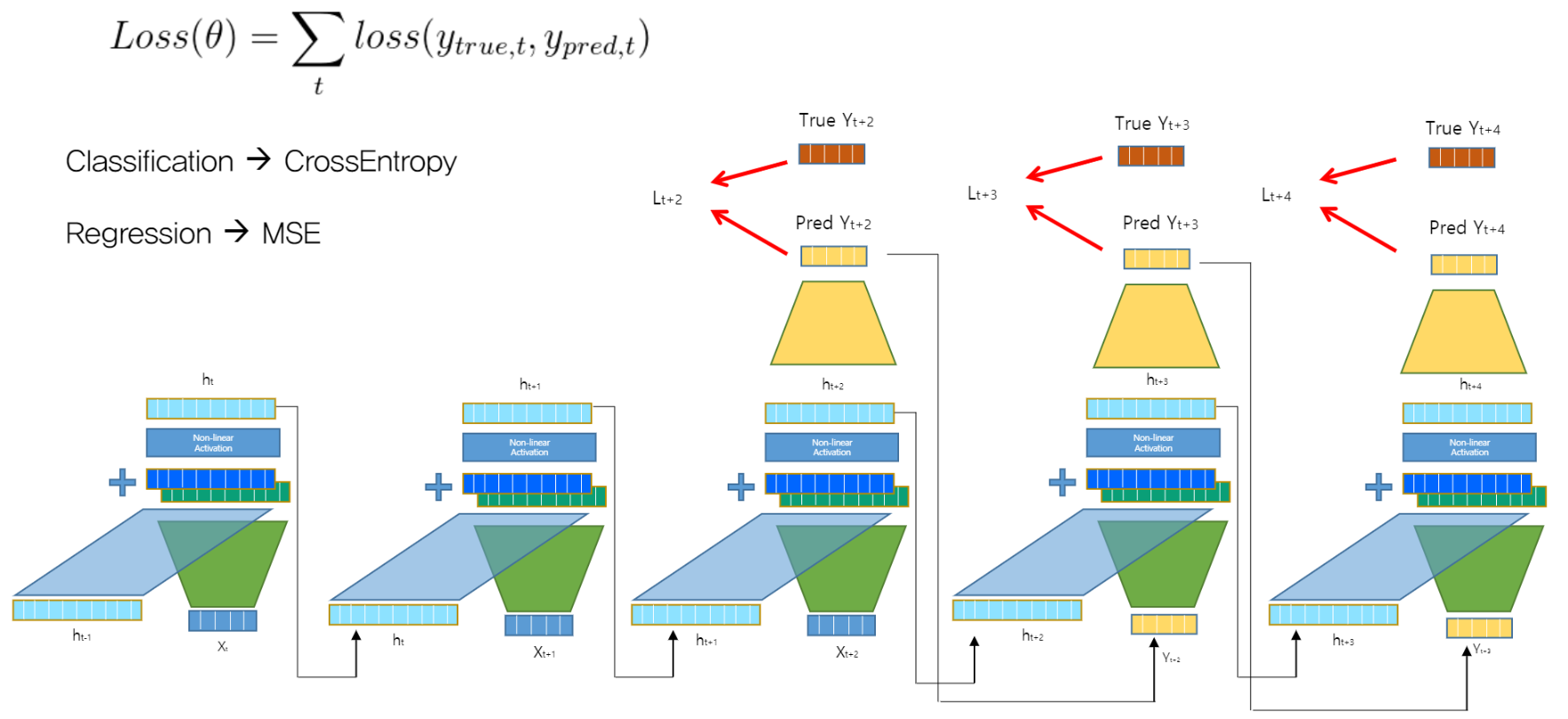
Loss함수 식을 보면 변수 t에 대해 theta값은 변하지 않는다 -> 펼쳐져 있지만 W_h와 W_d는 같은 레이어입니다.
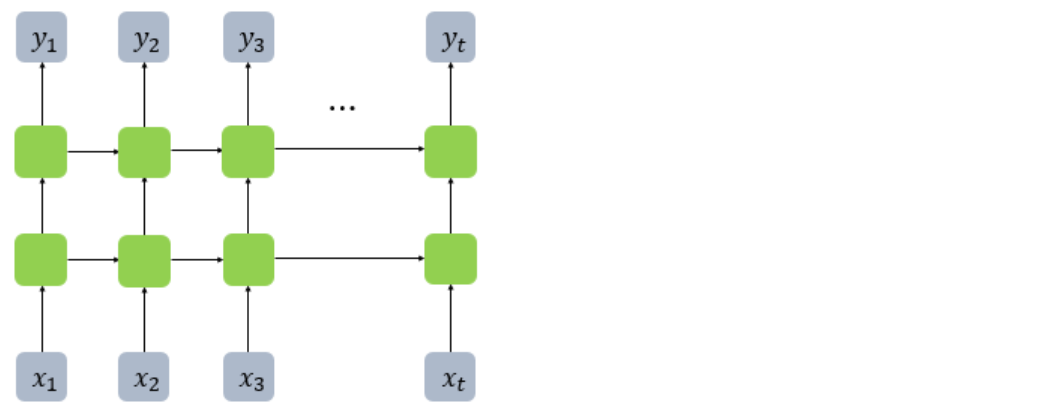
깊은 RNN 모델
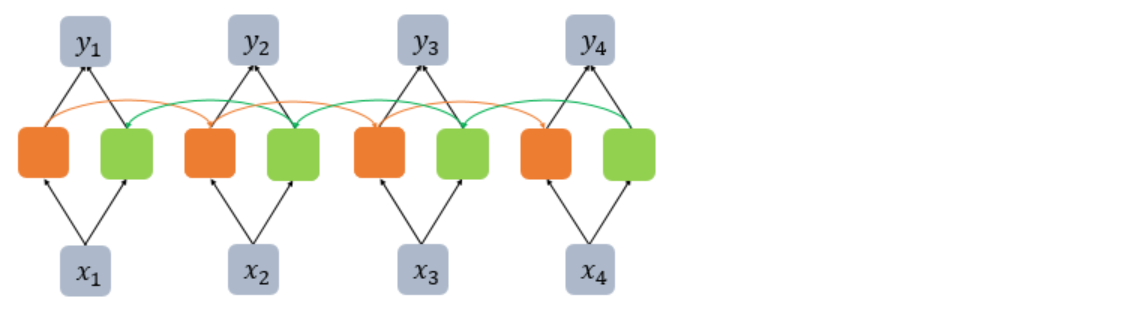
양방향 RNN 모델
양방향 순환 신경망은 시점 t에서의 출력값을 예측할 때 이전 시점의 데이터뿐만 아니라, 이후 데이터로도 예측할 수 있다는 아이디어에 기반합니다.
즉, RNN이 과거 시점(time step)의 데이터들을 참고해서, 찾고자하는 정답을 예측하지만 실제 문제에서는 과거 시점의 데이터만 고려하는 것이 아니라 향후 시점의 데이터에 힌트가 있는 경우도 많습니다. 그래서 이전 시점의 데이터뿐만 아니라, 이후 시점의 데이터도 힌트로 활용하기 위해서 고안된 것이 양방향 RNN입니다.
바닐라 RNN의 한계점
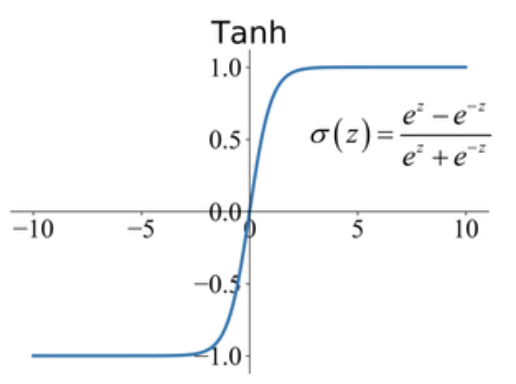
바닐라 RNN은 출력 결과가 이전의 계산 결과에 의존한다는 것을 언급한 바 있습니다. 하지만 바닐라 RNN은 비교적 짧은 시퀀스(sequence)에 대해서만 효과를 보이는 단점이 있습니다. 바닐라 RNN의 시점(time step)이 길어질 수록 앞의 정보가 뒤로 충분히 전달되지 못하는 현상이 발생합니다. 그 이유는 다음과 같이 셀을 거듭할수록 tanh함수의 출력값이 가지는 제한(절댓값의 크기가 1보다 같거나 작습니다) 때문입니다.
만약 tanh가 아니라 relu를 쓴다면, 반대로 맨 앞에서 받았던 정보가 층을 거듭할수록 값이 너무 커져서 시퀀스 뒤에 위치한 데이터의 학습을 방해할 수 있습니다.
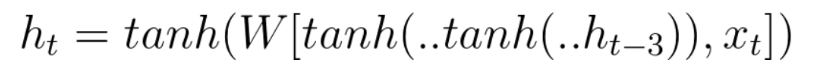
이를 해결하기 위해 RNN의 advanced 버전인 LSTM과 GRU에 대해서는 다음 포스트에서 살펴보도록 하겠습니다.