Table of Contents
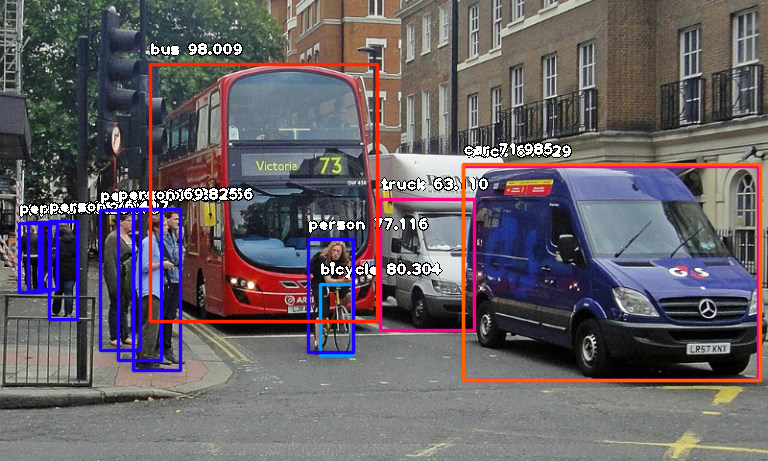
Object Detection
- 이미지 내에서 오브젝트를 찾고 해당 오브젝트의 클래스를 분류하는 태스크를 말한다
특징
- 실생활에서 짧은 시간 동안 여러 입력 이미지가 주어지는 경우가 많기 때문에 빠른 추론을 요구 한다
- 박스의 좌표값을 예측하는 regression 문제와, 오브젝트의 클래스를 판별하는 classification 문제가 합쳐져 있다
분류
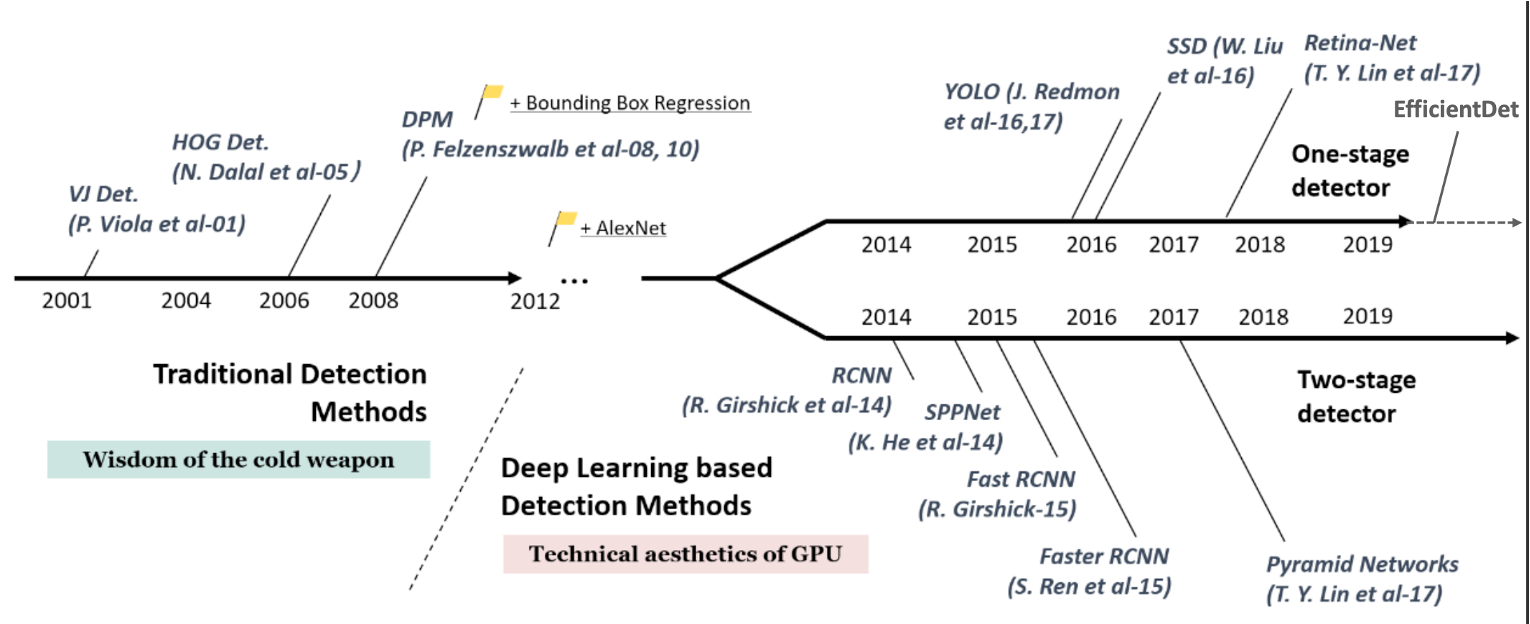
Two-stage detector
- 오브젝트가 있는 박스를 먼저 찾은 후, 박스 안의 오브젝트 클래스를 분류하는 방식
- 성능은 높지만, 추론 시간이 오래 걸린다
One-stage detector
- 박스를 찾는 태스크와 박스 안의 오브젝트 클래스를 분류하는 두 가지 태스크를 동시에 진행하는 방식
- 추론 시간이 빠르고, SSD(Single Shot Detector) 모델 부터 성능이 높아졌고 이러한 특성들이 YOLO2 부터 반영되면서 One-stage detector의 인기가 높아졌다
YOLO 모델 분석
- You Only Look Once
데이터 형태
입력 데이터
- 일반적인 이미지 데이터
- 이미지 데이터는 리사이즈(resize)와 텐서로 바꾸는 정도면 충분하다
레이블 데이터
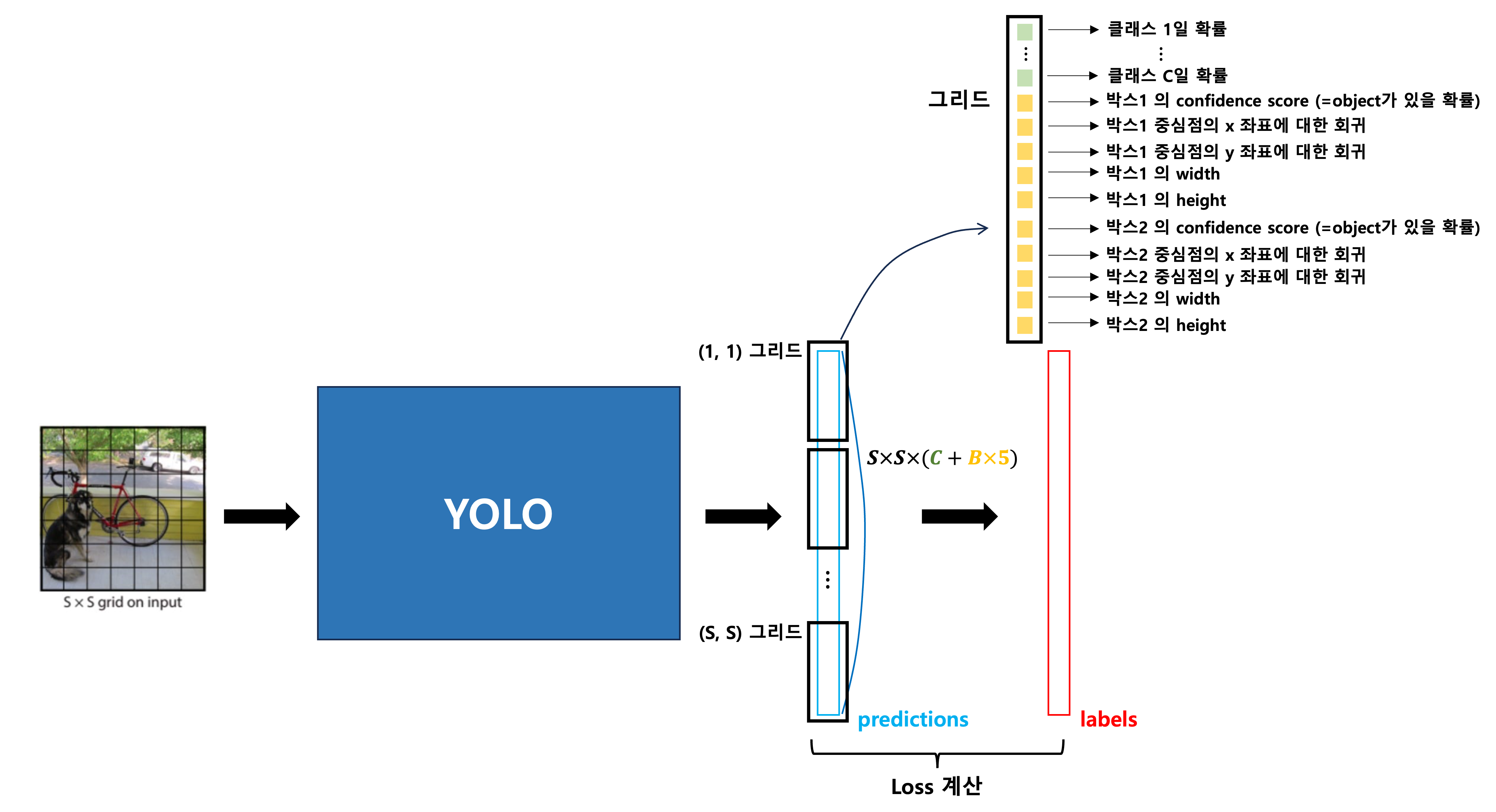
( S, S, (C + B*5) )형태의 데이터S: 그리드 크기 (기본값 7)C: 클래스 수B: 박스 수 (기본값 2)5: 오브젝트 유무, 박스 중심의 x좌표, 박스 중심의 y좌표, 박스의 너비, 의박스 높이
- 레이블(y) 데이터를 구하는 방법은 다음과 같다
torch.zeros((S, S, C + 5 * B))로 영벡터를 만든다- 실제 오브젝트가 있는 박스의
(x, y, w, h)정보를 담고 있는 리스트를 for문으로 돌며- 클래스의 확률 값을 해당 클래스만 1 나머지는 0으로 하도록 한다
- 각 박스의 오브젝트 유무를 1로 한다
- 각 박스의
(x, y, w, h)값을 그리드 단위로 바꾼다(x_cell, y_cell, width_cell, height_cell) - (박스가 2개면 뒤에 하나 더 concat 하면 된다)
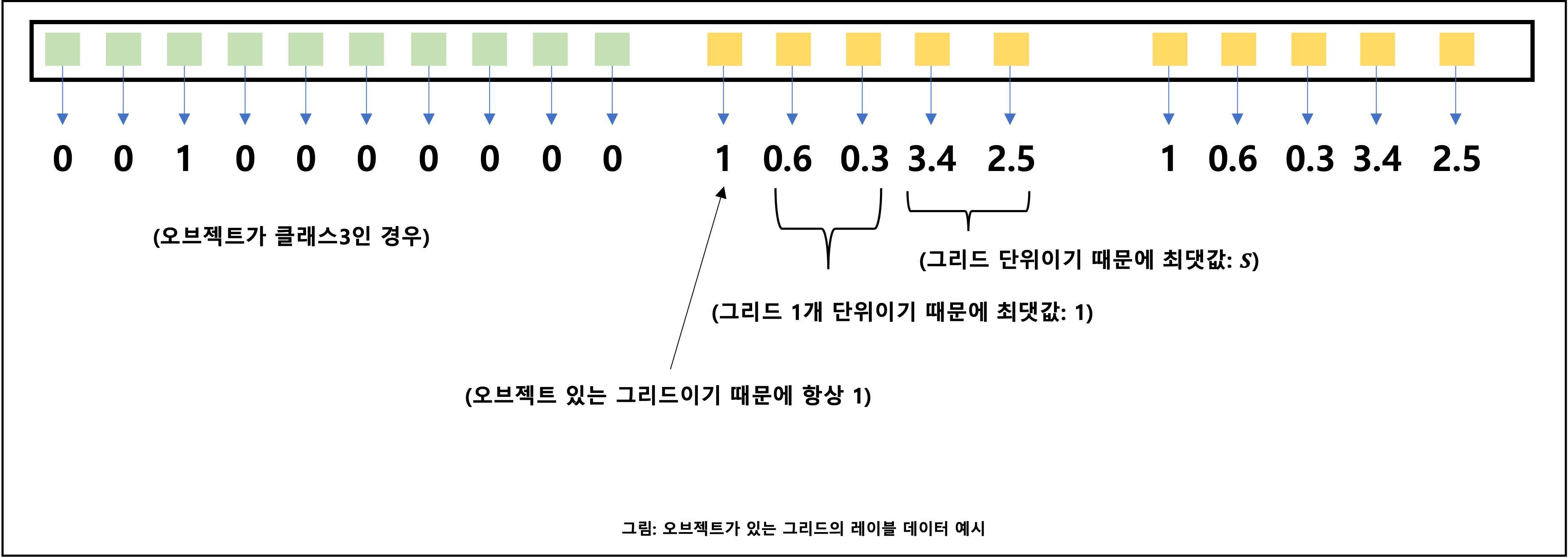
- 박스에 포함되지 않는 (즉, 오브젝트가 없는) 그리드는 영벡터로 초기화 했기 때문에 자연스럽게 모두 0인 값이 된다
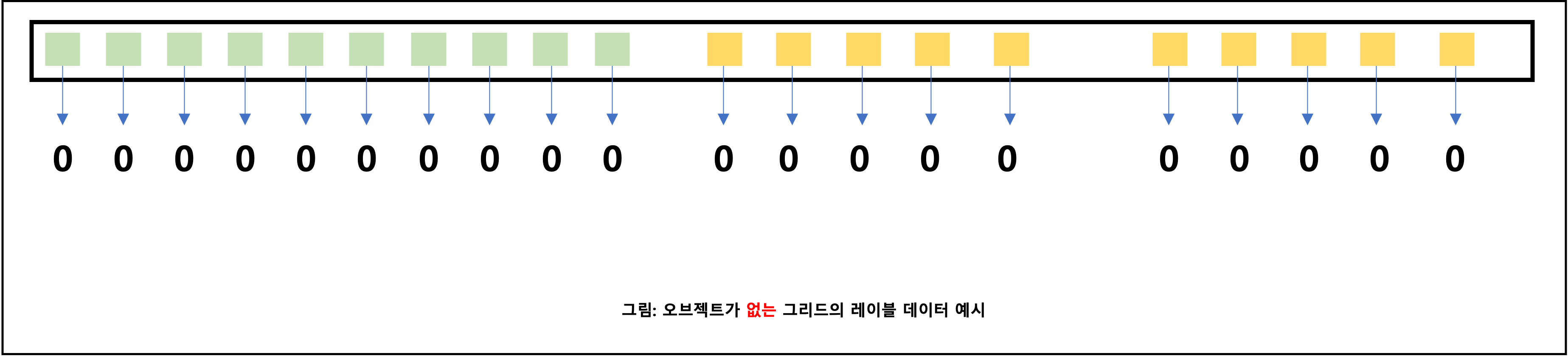
- 모든 그리드에 대해 (즉, 이미지 하나에 대해) 레이블 데이터의 모습을 보면 다음과 같다

모델
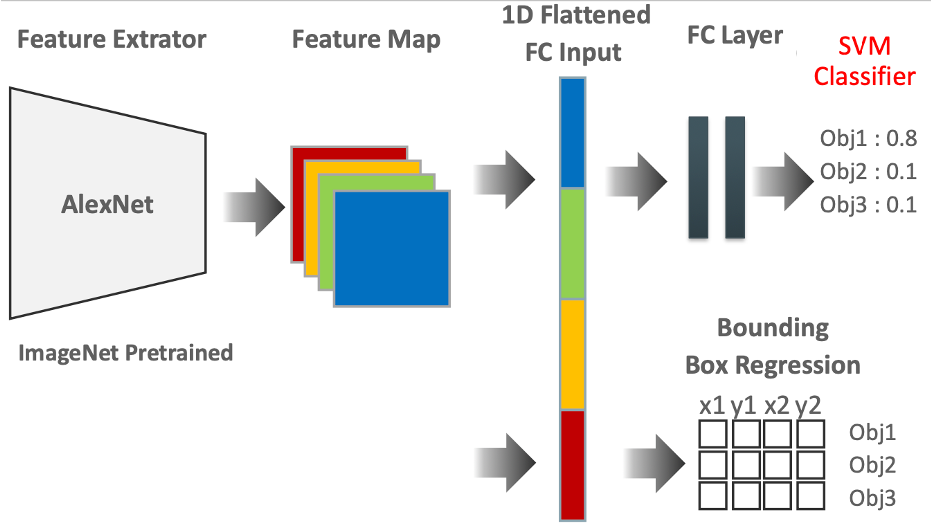
- 모델은 크게 이미지의 특성을 추출하는 Feature Extractor 역할을 하는 Backbone과 레이블의 형태에 맞게 값을 출력하는 역할을 하는 Head로 이루어져 있다
- 아래 그림은 정확히 YOLO 모델은 아니지만 Object Detection 모델의 일반적인 구조를 나타낸다
- 나는 모델 개발이 아닌 모델 사용에만 관심이 있기 때문에 출력의 형태만 살펴보면 아래 그림과 같다
손실 함수
- 모델이 출력하는 값과 레이블의 형태는
( S, S, (C + B*5) )이다 - 각 그리드의 첫 번째 박스의 IoU 값과, 두 번째 박스의 IoU 값을 계산해, 더 높은 IoU 값을 가지는 박스를 하나 선택한다
-
박스를 선택했으면 아래 식처럼 손실 함수를 정의한다
모든 그리드에 대해, 박스가 얼마나 정확한지 MSE + 박스 안에 오브젝트가 있을 때 얼마나 자신감이 있는지 MSE + 박스 안에 오브젝트가 없을 때 얼마나 자신감이 없는지 MSE + 클래스가 얼마나 정확한지 MSE - IoU (Intersection over Union)

성능 평가
- 검증 데이터에 대해 bbox를 모두 구한다 ( 7 * 7 그리드에 2개의 박스를 구하도록 한다면, 98개의 박스가 구해진다)
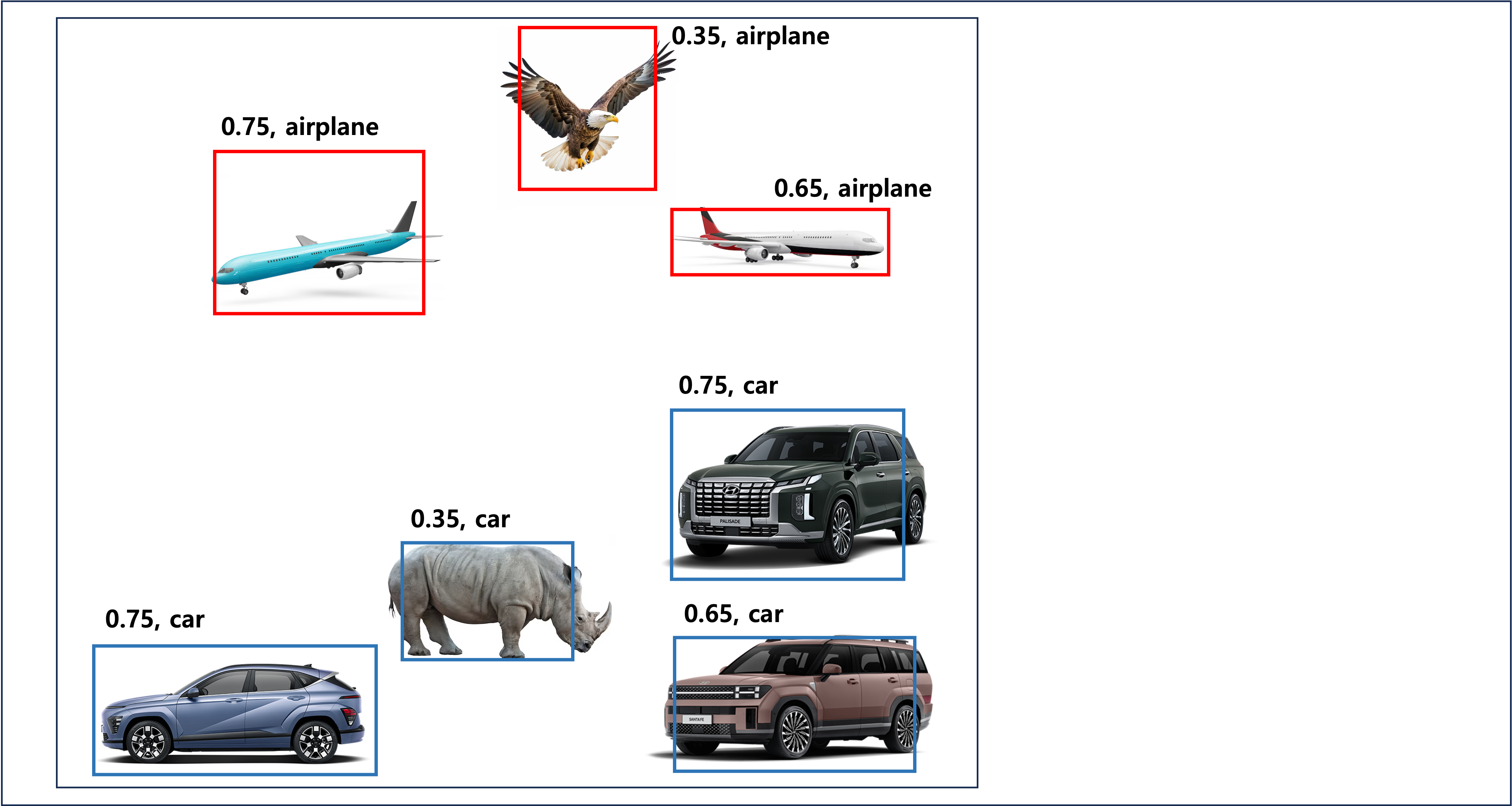
- NMS(Non Max Suppression)를 수행한다
- 박스를 confidence score를 기준으로 내림차순 정렬한다
- 각 박스에 대해
- 현재 박스와 같은 클래스를 가지는 박스 제거 (현재 박스가 같은 클래스에 대해 confidence score가 더 높으므로)
- 현재 박스와 IoU가 특정 임계값 이상인 박스 제거 (박스 주변에서 가장 확실한 오브젝트 하나만 선택하기 위해, 너무 겹쳐진 박스는 제거한다)

- 가장 확실한 박스들만 남았으므로 이제 이 박스들에 대해 mAP(mean Average Precision) 성능 평가를 한다
- 모든 클래스에 대해
- 해당 클래스의 박스들 중에서 confidence score 값에 따른 precision 값을 구한 후 평균한다 -> AP
- 모든 클래스에서 얻어진 AP 값을 평균하면 mAP가 된다