Table of Contents
카프카의 탄생
2011년 링크드인에서는 파편화된 데이터 수집 및 분배를 위한 데이터 파이프라인을 운영하는 데에 어려움을 겪었습니다.초기 운영시에는 데이터를 생성하고 적재하는데 큰 어려움이 없었지만, 서비스 사용자가 증가함에 따라 데이터량이 폭발적으로 증가하기 시작했고 아키텍처도 점점 복잡해지기 시작했습니다.
이를 해결하기 위해 기존에 나와있던 데이터 프레임워크와 오픈소스를 활용해 파이프라인의 파편화를 개선하려고 노력했지만 결국 한계를 느끼고 링크드인의 데이터팀은 데이터 파이프라인을 위한 새로운 시스템을 만들기로 결정했습니다.
그 결과물로 등장한 것이 카프카(Kafka)입니다. 카프카는 이후 아파치 재단의 최상위 프로젝트로 등록되었습니다. 그리고 2014년 카프카 개발의 핵심 멤버였던 제이 크랩스(Jay Kreps)는 컨플루언트(Confluent)라는 회사를 창업해 카프카를 더욱 편리하게 운영할 수 있도록 몇 가지 추가적인 기능을 추가해 현재 카프카 관련 다양한 서비스를 제공하고 있습니다.
카프카의 구조
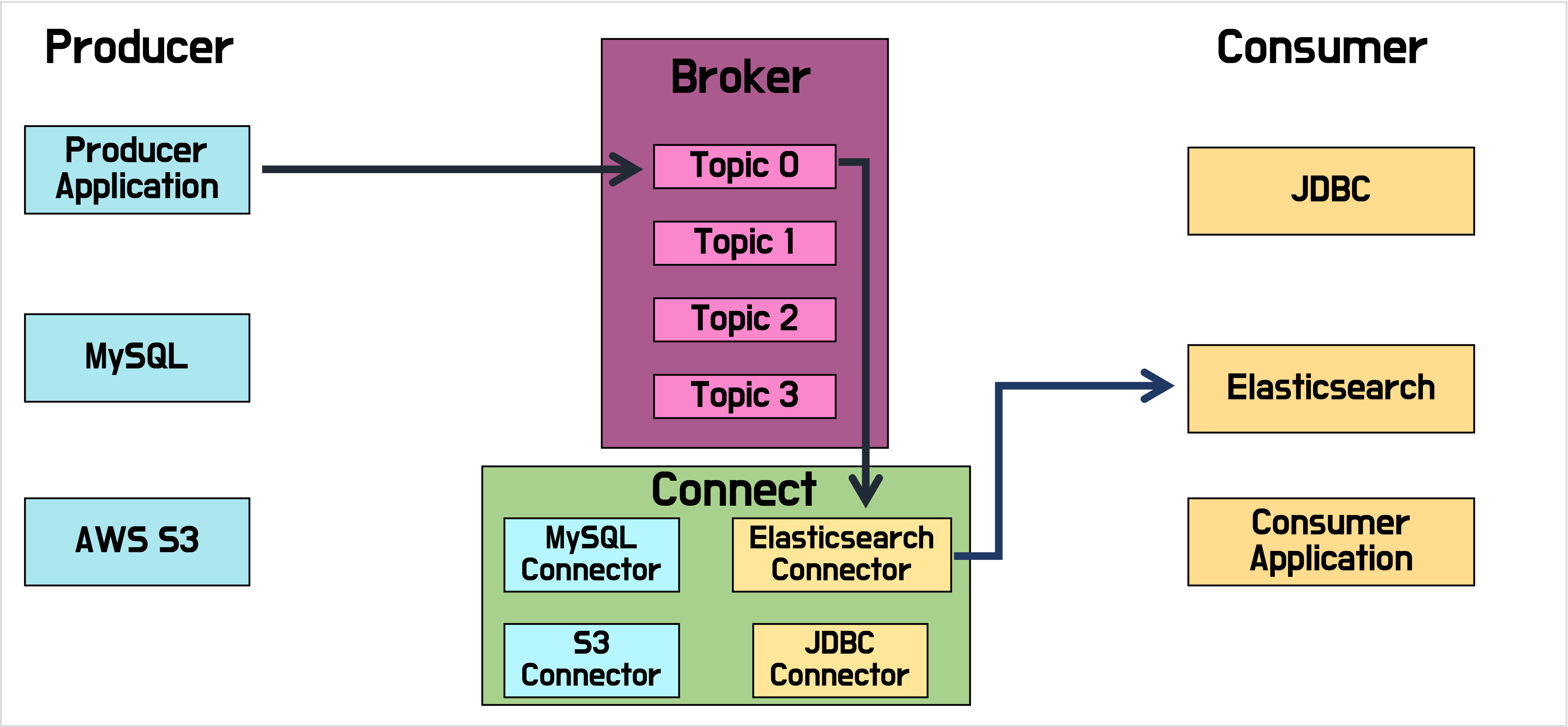
카프카는 더이상 각각의 애플리케이션을 서로 연결해서 데이터를 처리하는 것이 아니라 한 곳에 모아 처리할 수 있도록 중앙 집중화 하였습니다.
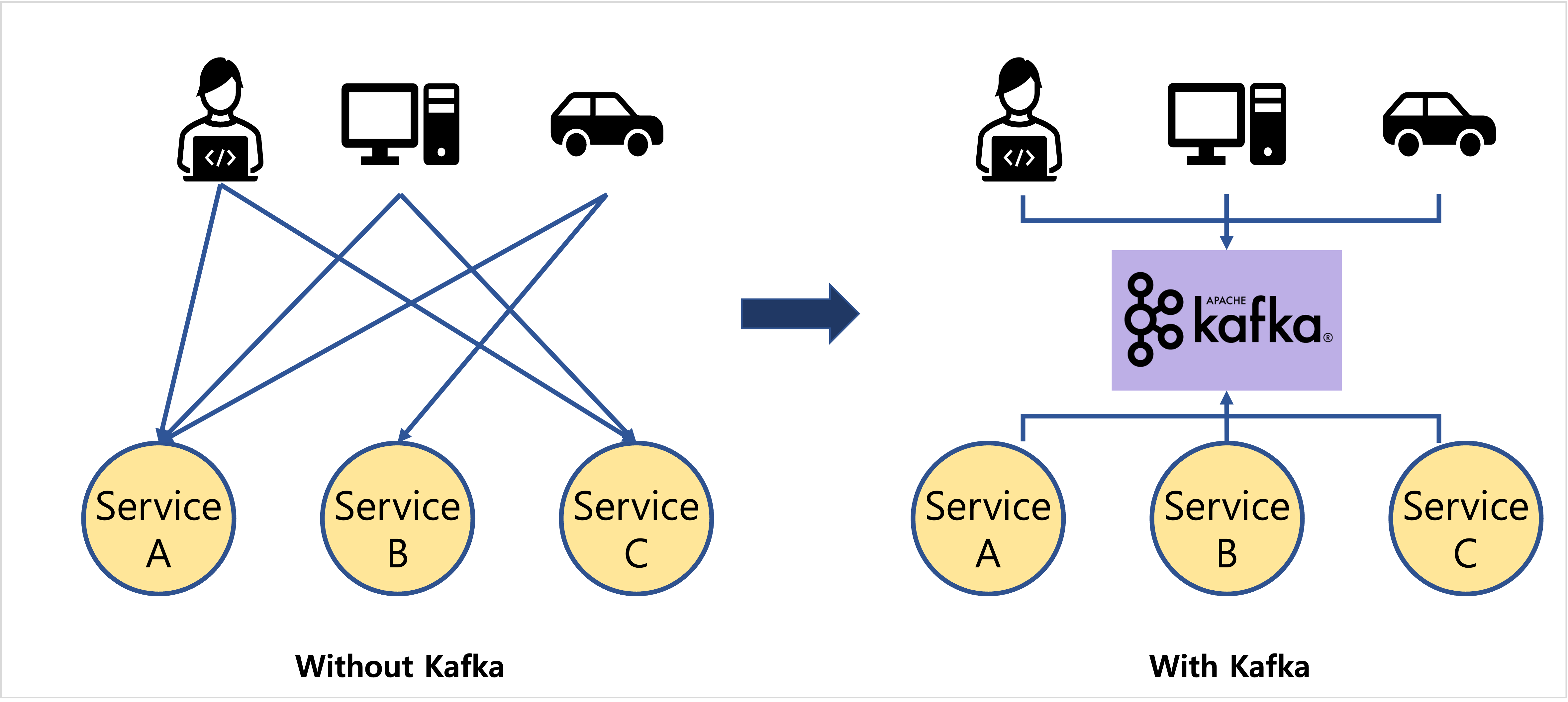
기존에 있던 데이터 파이프라인은 소스와 타겟의 직접적인 연결로 한쪽의 이슈가 다른 쪽의 애플리케이션에 영향을 미치곤 했지만 카프카는 이러한 높은 의존성 문제를 해결했습니다. 이제 소스 애플리케이션은 어느 타겟 애플리케이션으로 보낼지 고민하지 않고 일단 카프카로 넣으면 됩니다.
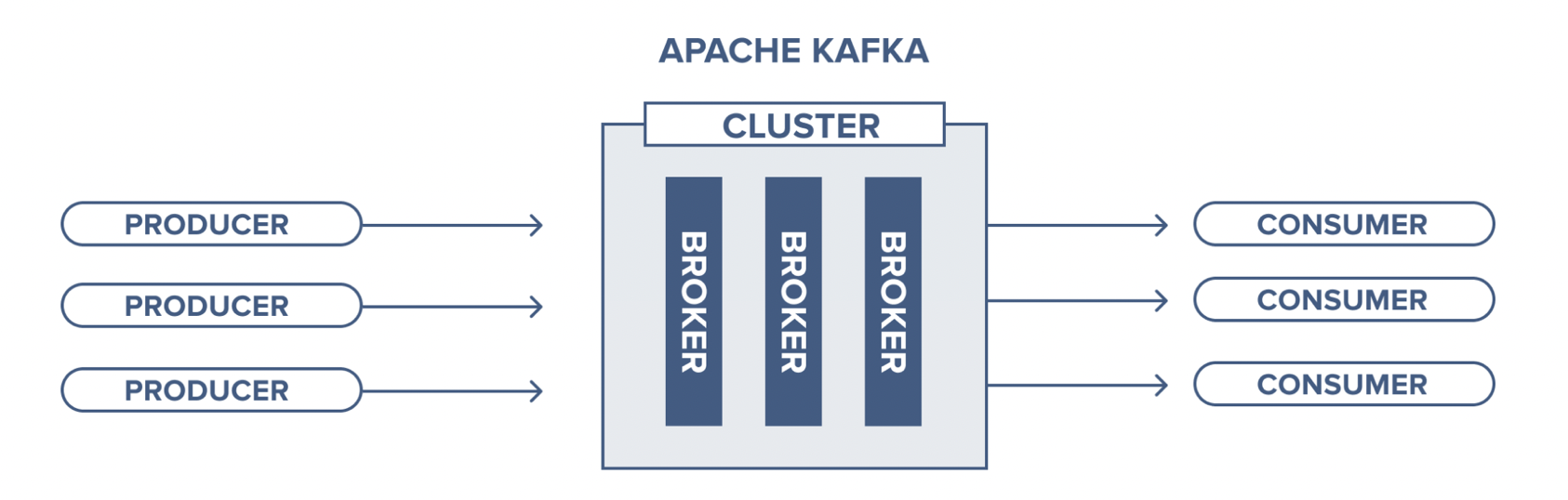
카프카 내부에 데이터가 저장되는 파티션의 동작은 FIFO 방식의 큐 자료구조와 유사합니다. 카프카에서는 이러한 큐를 브로커(broker), 소스 애플리케이션을 프로듀서(producer), 타겟 애플리케이션을 컨슈머(consumer)라고 합니다.
카프카를 소개하는 좋은 문장이 있어 가져와봤습니다.
Apache Kafka is an open-source distributed publish-subscribe messaging platform that has been purpose-built to handle real-time streaming data for distributed streaming, pipelining, and replay of data feeds for fast, scalable operations.
- 실시간 데이터를 스트리밍하는 분산환경의 publish-subscribe 메시지 플랫폼
- 복잡한 데이터 파이프라인 구조를 간단하게 해주며 파이프라인의 확장성을 높여준다
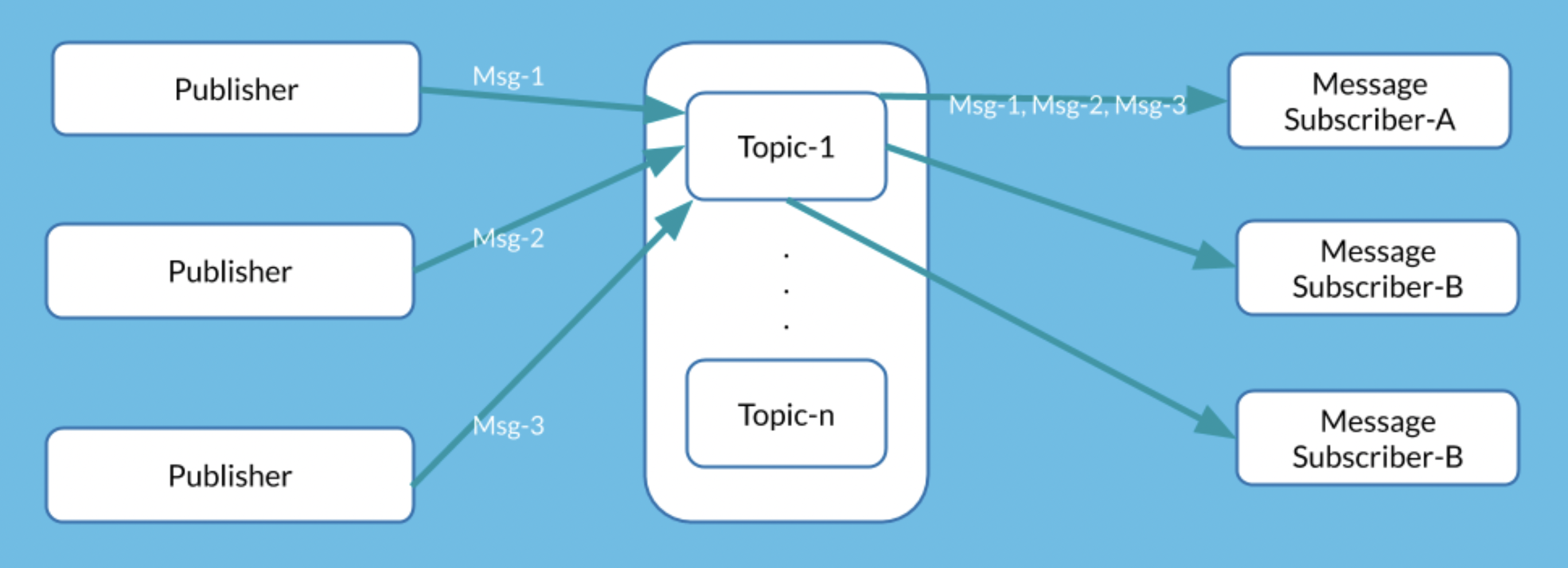
Publish/subscribe messaging is a pattern that is characterized by that a piece of data (message) of the sender (publisher) is not directing to certain receiver. Instead, the publisher classifies the message somehow, and that receiver (subscriber) subscribes to receive certain classes of messages. Pub/sub systems often have a broker, a central point where messages are published, to facilitate this.
- 데이터를 소스에서 목적지로 직접 전달하는 것이 아니다
- 프로듀서가 데이터를 생성(발행)해서 브로커(잡지)에 저장한다
- 컨슈머는 브로커(잡지)에 저장된 데이터를 읽어간다(구독)
카프카의 장점
높은 처리량
- 배치 처리 제공 -> 네트워크 비용 낮춤 -> 처리량 증가
- 데이터를 파티션 단위로 나눔 -> 컨슈머 개수를 파티션 수 만큼 늘림 -> 컨슈머 수만큼 처리량 증가
- 데이터를 압축하여 브로커에 전송 가능 -> 처리량 증가
낮은 지연
- 높은 처리량에 초점이 맞춰져 있지만 설정값을 통해 낮은 지연율을 얻을 수 있음
- (카프카에 관한 글을 읽으면 카프카가 제공하는 큰 장점 중 하나가 낮은 지연율이라고 생각이 들지만 직접 써보게 되면 낮은 지연율 보다는 높은 처리량에 초점이 맞춰져있다. 하지만 설정값을 바꿔줌으로써 낮은 지연율을 얻을 수 있다)
확장성
- 카프카는 분산 시스템 -> 트래픽량에 따라 스케일 아웃 가능 -> 높은 확장성
영속성
- 다른 메세징 플랫폼과 다르게 데이터를 파일 시스템에 저장 -> 종료되더라도 데이터가 남아있다 -> 영속성
- (또한 페이지 캐시 영역을 메모리에 따로 생성해 데이터 읽는 속도도 느려지지 않음)
고가용성
- 여러 대의 브로커에 데이터 복제 -> 브로커가 고장나도 장애 복구 가능 -> 높은 가용성
카프카의 핵심 기능
순서 보장
이벤트 처리 순서가 보장되면서, 엔티티 간의 유효성 검사나 동시 수정 같은 무수한 복잡성들이 제거됨으로써 구조 또한 매우 간결해졌습니다.
적어도 한 번 전송 방식
분산된 여러 네트워크 환경에서의 데이터 처리에서 중요한 것은 멱등성(idempotence)입니다. 멱등성이란 동일한 작업을 여러 번 수행하더라도 결과가 달라지지 않는 것을 의미합니다. 하지만 실시간 대용량 데이터 스트림에서 이를 완벽히 지켜내기란 쉽지 않습니다. 그래서 차선책으로 데이터가 중복은 되더라도, 손실은 일어나지 않도록 하는 방식이 ‘적어도 한 번’ 전송 방식입니다. 만약 백엔드 시스템에서 중복 메세지만 처리해준다면 멱등성을 위한 시스템 복잡도를 기존에 비해 훨씬 낮출 수 있게 되고, 처리량 또한 더욱 높아집니다. 최근에는 ‘정확히 한 번’ 전송 방식이 도입되어 카프카내에서 중복성을 제거하는 방법이 많이 사용되고 있습니다.
Idempotent: Characteristic that we can apply operation multiple times without changing the result beyond the initial application.
카프카에서 정확히 한 번 전송 방식을 지원하는데 멱등적인 방법은 아님. De-duplication 방식임.
In the de-duplication approach, we give every message a unique identifier, and every retried message contains the same identifier as the original. In this way, the recipient can remember the set of identifiers it received and executed already. It will also avoid executing operations that are executed.
It is important to note that in order to do this, we must have control on both sides of the system: sender and receiver. This is because the ID generation occurs on the sender side, but the de-duplication process occurs on the receiver side.
it’s impossible to have exactly-once delivery in a distributed system. However, it’s still sometimes possible to have exactly-once processing.
(정확히 한 번 전송은 사실 Producer는 중복 전송하더라도, 브로커에서 저장하는 과정을 한 번만 수행함으로서 보장된다)
강력한 파티셔닝
파티셔닝을 통해 확장성이 용이한 분산 처리 환경을 제공합니다.
비동기 방식
데이터를 제공하는 Producer와 데이터를 소비하는 Consumer가 서로 각기 원하는 시점에 동작을 수행할 수 있습니다. (데이터를 보내줬다고 해서 반드시 바로 받을 필요가 없습니다)
정리
- Kafka는 Pub/sub모델의 실시간 데이터 처리 플랫폼이다.
- 데이터를 분산처리하여 높은 처리량을 제공하고, 선택적으로 낮은 지연율을 얻을 수 있다
- 심플한 데이터 처리 파이프라인과 용이한 확장성을 제공한다.
다음 포스트에서는 Kafka의 주요 구성 요소에 대해 알아보겠습니다.
카프카 생태계