



































Table of Contents
MongoDB
- C++로 개발된 도큐먼트 기반 NoSQL 오픈소스 데이터베이스이다
몽고DB의 역사
- Humongous(거대한) Database를 줄인 MongoDB로 명명
- 2007년 뉴욕 기반의 10gen 이라는 기관에서 시작
- 기존의 회사가 운영하던 관계형 데이터베이스의 확장성에 심각한 한계점을 느끼고 나서 높은 확장성을 제공하는 데이터베이스를 만들기로 결심
- Kevin P. Ryan, Dwight Merriman 그리고 Eliot Horowitz가 10gen을 나와 MongoDB Inc 라는 회사를 따로 설립
- 2009년에 오픈소스로 처음 MongoDB가 세상에 등장
NoSQL
- NoSQL은 RDBMS 처럼 엄격하게 스키마를 정의하지 않고, Semi-Structured한 형태의 데이터 저장을 지원하는 데이터베이스이다
- NoSQL의 일반적인 장점: 유연한 스키마, 유연한 확장성, 높은 가용성
- 데이터 형태를 표현하는 방법에 따라 Document store, Key-value store, Wide column store 등으로 더욱 세분화된다
MongoDB의 장점
- 유연한 스키마
- 유연한 확장성: Scale-out, 샤딩, 자체 로드 밸런싱(mongos)
- 높은 가용성: Replica Set
- 인덱스 지원: 프라이머리 키 인덱스, 세컨더리 인덱스
- 복잡하고 다양한 쿼리 가능: Ad-hoc 쿼리, 전문 검색
- BSON 형태의 데이터 저장 포맷: 데이터 크기가 가벼워짐, 다양한 데이터 타입 지원, 빠른 쿼리
MongoDB의 특징
데이터 구조
- Database
- 사용자 정의 db
admindb: 인증과 권한 부여와 관련된 데이터베이스localdb: 복제 처리와 관련된 데이터베이스configdb: 분산처리, 샤드(shard)에 관련된 데이터베이스
- Collection
- RDBMS의 테이블과 비슷한 개념
- 컬렉션 단위로 동적인 스키마를 가진다
- 컬렉션 단위로 인덱스를 생성할 수 있다
- 컬렉션 단위로 샤딩할 수 있다
- Document
- RDBMS의 레코드와 비슷한 개념
- 다른 도큐먼트, 배열과 같은 필드를 가질 수 있다
- JSON 형태로 표현하고, BSON 형태로 저장한다
- 도큐먼트마다 고유한
_id프라이머리 키 값이 있다. - 도큐먼트 한 개의 최대 크기는 16MB 이다
- Field
- 필드를 추가하기 위해 컬렉션의 스키마를 다시 정의할 필요가 없다
- 필드의 추가, 삭제가 자유롭다
_id 필드
- 어떤 데이터 타입이어도 상관 없지만
ObjectId가 기본이다 - 하나의 컬렉션에서 모든 도큐먼트는 고유한
_id값을 가진다 ObjectId데이터 타입을 사용하는 주된 이유는 몽고DB의 분산 특성 때문이다- 샤딩된 환경에서 고유 식별자를 쉽게 생성하도록 도와준다
- (여러 서버에 걸쳐 자동으로 증가하는 기본 키를 동기화하는 작업은 어렵고 시간이 걸린다)
- (https://www.mongodb.com/docs/manual/core/document/#the-_id-field 참고)
BSON
- 데이터 입출력 시에는 JSON 형식을 사용
- 데이터 저장 시에는 BSON 형식을 사용
- JSON 데이터를 이진 형식으로 인코딩한 포맷
- 컴퓨터가 쉽게 이해할 수 있는 이진 포맷으로 검색 속도가 빠름
- 날짜 및 이진 데이터 타입을 지원함
- (https://www.mongodb.com/docs/manual/reference/bson-types/ 참고)

Replica Set
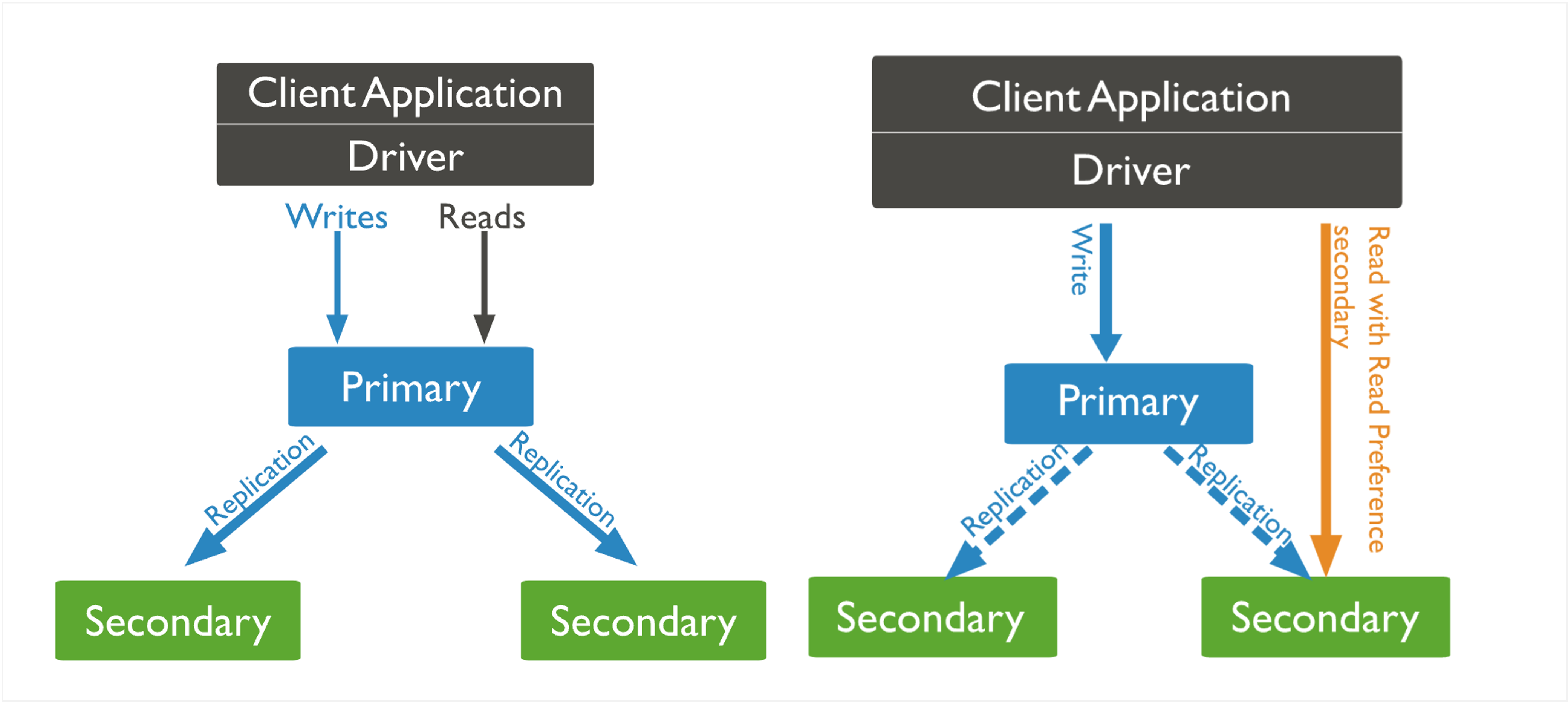
- 높은 가용성을 제공하기 위해 같은 데이터 셋을 저장 및 관리하는 몽고DB의 서버 그룹
- 크게 Primary와 Secondary로 구성
- Primary
- Leader Server
- Read/Write 모두 처리 가능
- Replica Set당 한 개만 존재
- Secondary
- Follower Server
- Read에 대한 요청만 처리 가능 -> Secondary 수를 늘림으로써 Read 분산 처리 가능
- 복제를 통해 Primary와 동일한 데이터 셋을 유지
- 지속적으로 하트비트(Heartbeat)를 주고 받으며 서버 살아 있는지 확인
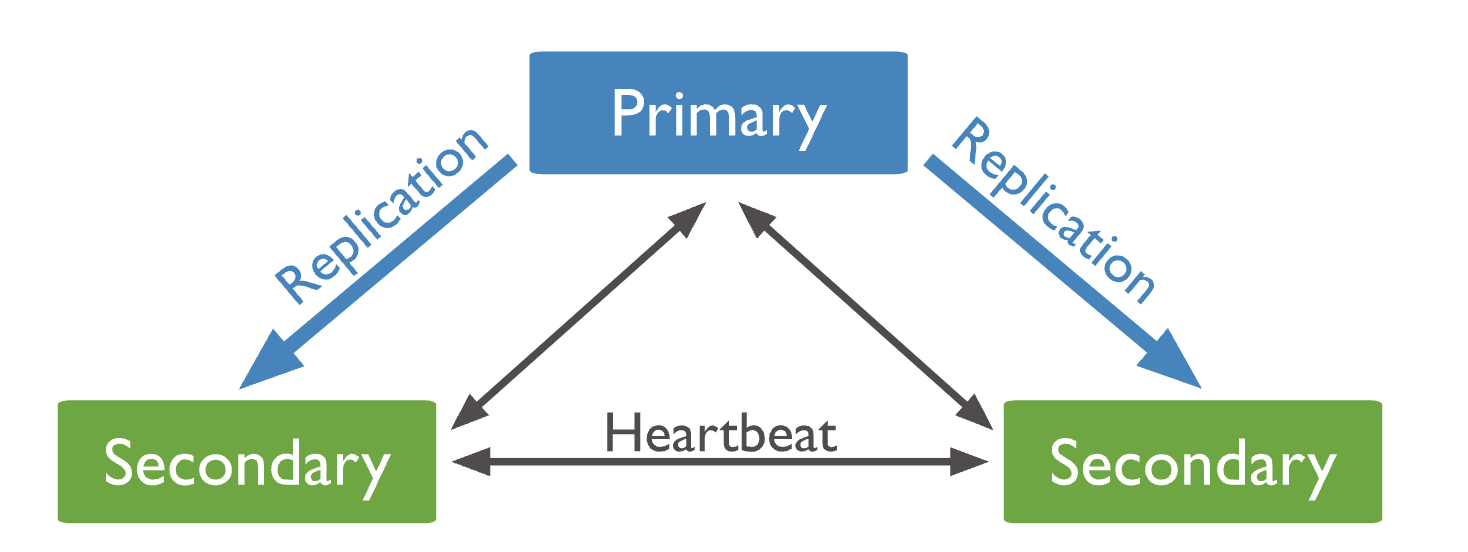
- Primary 서버가 Replica Set에서 이탈하면 Secondary중에서 새로운 리더를 선출해야함 (Leader election)
localdb의Oplog컬렉션을 통해 복제를 수행
Sharded Cluster
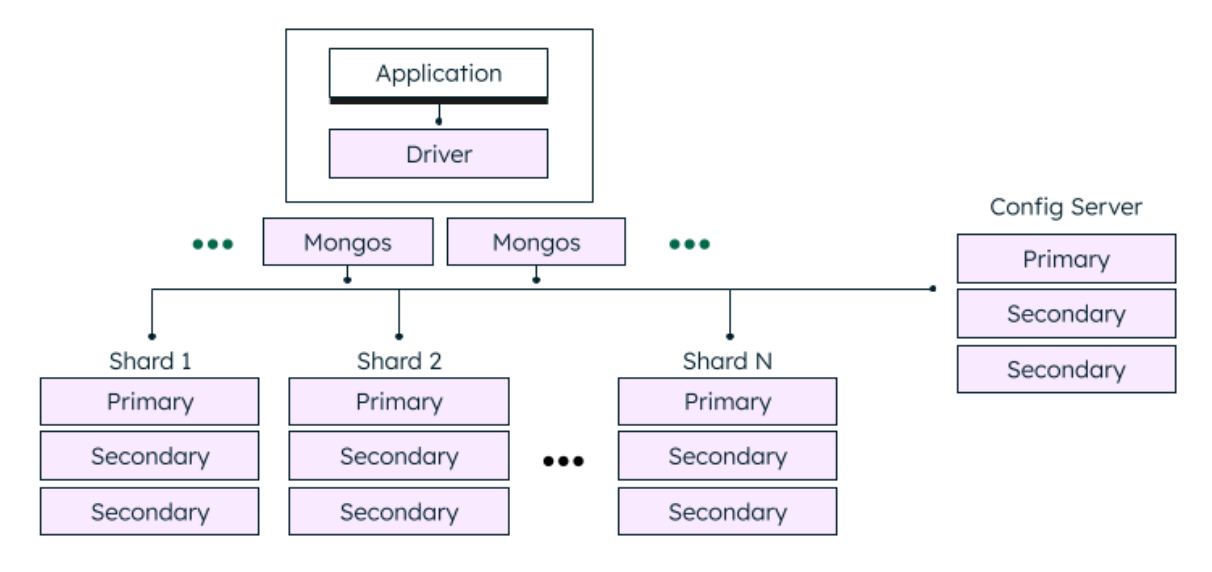
- 유연한 확장성을 제공하기 위해 데이터 셋을 일정 기준에 따라 나누어 여러 대의 서버에 분산 저장 및 처리(Write 작업)하는 몽고DB의 서버 그룹
- 모든 Shard는 Replica Set으로 구성 (높은 가용성과, 분산 Read 작업도 함께 지원)
- 샤딩을 위해서는 Shard Key를 선정해야 하고, 해당 필드에 인덱스가 만들어져 있어야 한다
- Ranged Sharding: 값의 범위에 따라 분산
- Hashed Sharding: 값의 해시 결과에 따라 분산 (가능하면 이 방법을 통해 분산한다)
- 비교적 관리가 복잡하다는 단점이 있다
WiredTiger Storage Engine
- MongoDB 3.2부터 기본 스토리지 엔진으로 WiredTiger를 사용
- 데이터 압축 지원: 4~6배 정도의 압축
- 도큐먼트 레벨의 잠금 지원
참고
- MongoDB 공식문서, Home
- MongoDB 공식문서, Why Use MongoDB and When to Use It?
- NHN 클라우드, mongoDB Story 1: mongoDB 정의와 NoSQL
- BYTESCOUT, MONGODB HISTORY AND ADVANTAGES
- Guru99, What is MongoDB? Introduction, Architecture, Features & Example
- MongoDB 공식문서, Replication
- 프리킴: [MongoDB] 몽고DB 기본 명령어
- Confluent hub: Debezium MongoDB CDC Source Connector