



































Table of Contents
- Optimization Overview
- Things to Consider for Optimization
- Optimizer
- Query Optimization
- WHERE, GROUP BY, ORDER BY의 인덱스 사용
- INSERT, UPDATE, DELETE문
- 실행 계획
- 참고
Optimization Overview
- 데이터베이스의 성능은 테이블, 쿼리, 서버 설정과 같은 몇 가지 요소에 따라 달라짐
- 데이터베이스를 잘 설계함으로써 CPU, I/O 작업과 같은 하드웨어적인 요소들을 최적화 할 수 있음
Things to Consider for Optimization
테이블
- 컬럼의 타입
- 컬럼 개수
- 제약조건
-
인덱스
- applications that perform frequent updates often have many tables with few columns,
- while applications that analyze large amounts of data often have few tables with many columns
인덱스 설계
- Are the right indexes in place to make queries efficient?
스토리지 엔진 선택
- In particular, the choice of a transactional storage engine such as InnoDB or a nontransactional one such as MyISAM can be very important for performance and scalability
DB서버 설정
- Does the application use an appropriate locking strategy? For example, by allowing shared access when possible so that database operations can run concurrently, and requesting exclusive access when appropriate so that critical operations get top priority. Again, the choice of storage engine is significant.
-
The InnoDB storage engine handles most locking issues without involvement from you, allowing for better concurrency in the database and reducing the amount of experimentation and tuning for your code
- Are all memory areas used for caching sized correctly? That is, large enough to hold frequently accessed data, but not so large that they overload physical memory and cause paging. The main memory areas to configure are the InnoDB buffer pool and the MyISAM key cache
Optimizer
- 쿼리를 최적으로 실행하기 위해 각 테이블의 데이터가 어떤 분포로 저장돼 있는지 통계 정보를 참조하여 최적의 실행 계획을 수립
쿼리 실행 절차
- MySQL 엔진의 SQL파서에서 SQL을 트리 형태로 파싱한다
- MySQL 엔진의 옵티마이저에서 파싱 정보를 확인하면서 통계 정보를 활용해 어떤 인덱스를 이용해 테이블을 읽을지 선택한다
- 2 단계가 완료되면 실행 계획이 만들어진다
- 스토리지 엔진에 실행 계획대로 레코드를 읽어오도록 요청한다
- MySQL 엔진의 SQL 실행기가 스토리지 엔진으로부터 받아온 레코드를 조인하거나 정렬하는 작업을 수행한다
Query Optimization
SELECT
- 컬럼을 선택할 때 * 사용을 피해라
- DISTINCT 사용을 피해라 -> 중복 데이터 제거를 위해 테이블 풀 스캔 해야함
WHERE
- 인덱스를 잘 활용해라
- % 를 맨 앞에 쓰지마라
- 함수 사용을 피해라
- BETWEEN, IN, <, > 사용을 피해라
IN vs EXISTS
- IN
- IN은 다수의 OR 조건을 사용한 것과 같다
- IN 안에 포함된 값들을 모두 비교한다
- The IN operator cannot compare anything with NULL values
- IN 뒤에 서브 쿼리가 사용되면 서브 쿼리의 SELECT 절 결과를 조건에 사용한다
- 서브쿼리 결과의 크기가 작으면
IN이EXISTS보다 더 빠르다
- EXISTS
- 서브 쿼리가 반환하는 행이 있는지를 확인한다
- EXISTS 조건절에 하나라도 True로 평가되는 경우에는 더 이상 매칭 여부를 확인하지 않는다 (지연 평가)
- EXISTS 다음에 직접적으로 값을 명시할 수 없다. 서브쿼리가 주어져야 한다
- (내 생각: EXISTS를 의미있게 사용하려면 서브 쿼리에서 메인 쿼리 테이블의 컬럼을 외래키로 사용하고 있어야할 것 같다)
- (그렇지 않으면 EXISTS를 쓰는게 아무 의미가 없어 보인다)
- 서브쿼리 결과의 크기가 크면
EXISTS가 더 빠르다 - For checking against more than one single column, you can use the EXISTS Operator
- The EXISTS clause can compare everything with NULLs
GROUP BY
- HAVING절은 인덱스를 사용해서 처리될 수 없으므로 굳이 튜닝하려고 할 필요 없다
- GROUP BY 작업은 크게 인덱스를 사용하는 경우와 사용할 수 없는 경우(임시 테이블을 사용)
- 인덱스를 사용할 수 없는 경우, 전체 테이블을 스캔하여 각 그룹마다 새 임시 테이블을 만든 다음 이 임시 테이블을 사용하여 그룹을 검색하고 집계 함수를 적용하는 것
- 이렇게 인덱스를 사용할 수 없을 때 할 수 있는 최선의 방법은 WHERE절을 이용해 GROUP BY 하기 전에 데이터량을 줄이는 것
- 인덱스를 잘 설정한다면 임시 테이블을 생성하지 않고 빠르게 데이터를 가져올 수 있다
- 인덱스를 최대로 활용하기 위해서는 GROUP BY 컬럼과, 인덱스되어 있는 컬럼간의 순서가 중요함
- SELECT절에 사용되는 집계함수의 경우 MIN(), MAX()는 인덱스의 성능을 최대로 활용할 수 있도록 함
-
참고로 MySQL 8.0부터는 GROUP BY를 한다고 해서 암묵적으로 정렬이 이루어지지 않음 -> 정렬 필요하면 명시적으로 ORDER BY 써야함
- 루스 인덱스 스캔을 사용할 수 있는 경우
- 루스 인덱스 스캔은 레코드를 건너뛰면서 필요한 부분만 가져오는 스캔 방식
- EXPLAIN을 통해 실행 계획을 확인해보면 Extra 컬럼에 ‘Using index for group-by’ 라고 표기됨
- MIN(), MAX() 이외의 함수가 SELECT 절에 사용되면 루스 인덱스 스캔을 사용할 수 없음
- 인덱스와 GROUP BY의 컬럼 순서가 처음부터 일치해야함
- ex. 인덱스가 (col1 col2, col3) 일 때 , GROUP BY col1, col2 과 같아야 함 (GROUP BY col2, col3은 안됨)
- SELECT 절과 GROUP BY 절의 컬럼이 일치해야 함
- ex. SELECT col1, col2, MAX(col3) GROUP BY col1, col2
- 타이트 인덱스 스캔을 사용하는 경우
- SELECT 절과 GROUP BY 절의 컬럼이 일치하지 않지만, 조건절을 이용해 범위 스캔이 가능한 경우
- ex. SELECT c1, c2, c3 FROM t1 WHERE c2 = ‘a’ GROUP BY c1, c3;
- ex. SELECT c1, c2, c3 FROM t1 WHERE c1 = ‘a’ GROUP BY c2, c3;
- SELECT 절과 GROUP BY 절의 컬럼이 일치하지 않지만, 조건절을 이용해 범위 스캔이 가능한 경우
JOIN
- OUTER JOIN보다는 INNER JOIN이 낫다
- 드라이빙 테이블(Driving Table)은 레코드 수가 적은 것이 낫다
- 드리븐 테이블은 인덱스를 가지는 것이 중요하다
- JOIN의 조건절로 자주 사용하는 칼럼은 인덱스로 등록한다
- INNER JOIN은 순서를 신경쓰지 않고 편하게 사용 가능하다
- OUTER JOIN은 결과가 상관 없다면, 인덱스를 가지는 테이블이 드리븐 테이블로 오도록 하는 것이 중요하다
ORDER BY
- 대부분의 SELECT 쿼리에서 정렬은 필수적
- 정렬을 처리하는 방법은 인덱스를 이용하는 방법과 Filesort라는 별도의 처리를 이용하는 방법
정렬 처리 방법
- 인덱스를 사용한 정렬
- 인덱스를 이용해 정렬을 하기 위해서는 반드시 ORDER BY의 순서대로 생성된 인덱스가 있어야 함
- 인덱스를 이용해 정렬이 가능한 이유는 B-Tree 인덱스가 키 값으로 정렬되어 있기 때문
- Filesort를 사용한 정렬
- 인덱스를 사용할 수 없는 경우, WHERE 조건에 일치하는 레코드를 검색해 정렬 버퍼에 저장하면서 정렬을 처리(FIlesort)함
| 방법 | 장점 | 단점 |
|---|---|---|
| 인덱스 이용 | SELECT 문을 실행할 때 이미 인덱스가 정렬돼 있어 순서대로 읽기만 하면 되므로 매우 빠르다 | INSERT, UPDATE, DELETE 작업시 부가적인 인덱스 추가/삭제 작업이 필요하므로 느리다 |
| Filesort 이용 | 인덱스 이용과 반대로 INSERT, UPDATE, DELETE 작업이 빠르다 | 정렬 작업이 쿼리 실행 시 처리되어 쿼리의 응답 속도가 느려진다 |
Filesort를 사용해야 하는 경우
- 정렬 기준이 너무 많아서 모든 인덱스를 생성하는 것이 불가능한 경우
- 어떤 처리의 결과를 정렬해야 하는 경우
- 랜덤하게 결과 레코드를 가져와야 하는 경우
소트 버퍼
- MySQL은 정렬을 수행하기 위해 별도의 메모리 공간을 할당받아서 사용하는데 이 메모리 공간을 소트 버퍼라고 한다
- 정렬해야 할 레코드의 건수가 소트 버퍼의 크기보다 크다면 어떻게 해야 할까?
- 정렬해야 할 레코드를 여러 조각으로 나눠서 처리하게 됨. 이 과정에서 임시 저장을 위해 디스크를 사용
- 일부를 처리하고 디스크에 저장하기를 반복 수행함
정렬 알고리즘
- 정렬 대상 컬럼과 프라이머리 키만 가져와서 정렬하는 방식
- 정렬 대상 컬럼과 프라이머리 키 값만 소트 버퍼에 담아 정렬을 수행
- 그리고 다시 정렬 순서대로 프라이머리 키로 테이블을 읽어서 SELECT할 컬럼을 가져옴
- 가져오는 컬럼이 두 개 뿐이라 소트 버퍼에 많은 레코드를 한 번에 읽어올 수 있음
- 단점은 테이블을 두 번 읽어야 함
- 정렬 대상 컬럼과 SELECT문으로 요청한 컬럼을 모두 가져와서 정렬하는 방식
- 최신 버전의 MySQL에서 일반적으로 사용하는 방식
- SELECT 문에서 요청한 컬럼의 개수가 많아지면 계속 분할해서 소트 버퍼에 읽어와야함
- 레코드의 크기나 건수가 작은 경우 성능이 좋음
DISTINCT 처리
- DISTINCT는 SELECT하는 레코드를 유니크하게 SELECT 하는 것이지, 특정 컬럼만 유니크하게 조회하는 것이 아님
SELECT DISTINCT(first_name), last_name FROM employees;- DISTINCT는 함수가 아니라서 위처럼 괄호를 해놓아도 그냥 무시함
- 그래서 결론적으로 first_name과 last_name의 조합이 유니크한 레코드를 가져오게 됨
- 집합 함수(COUNT(), MIN(), MAX()) 같은 집합 함수 내에서 DISTINCT 키워드가 사용된 경우는 함수의 인자로 전달된 컬럼값이 유니크한 것들을 가져온다
Subquery
- JOIN으로 해결되면 서브쿼리 대신 JOIN을 사용하자
- 서브쿼리 안에 where절과 group by를 통해 불러오는 데이터양을 감소시킬 수 있습니다
- 서브쿼리는 인덱스 또는 제약 정보를 가지지 않기 때문에 최적화되지 못한다
- 윈도우 함수를 고려해보자
Temporary Table
- Use a temporary table to handle bulk data
- Temporary table vs Using index access
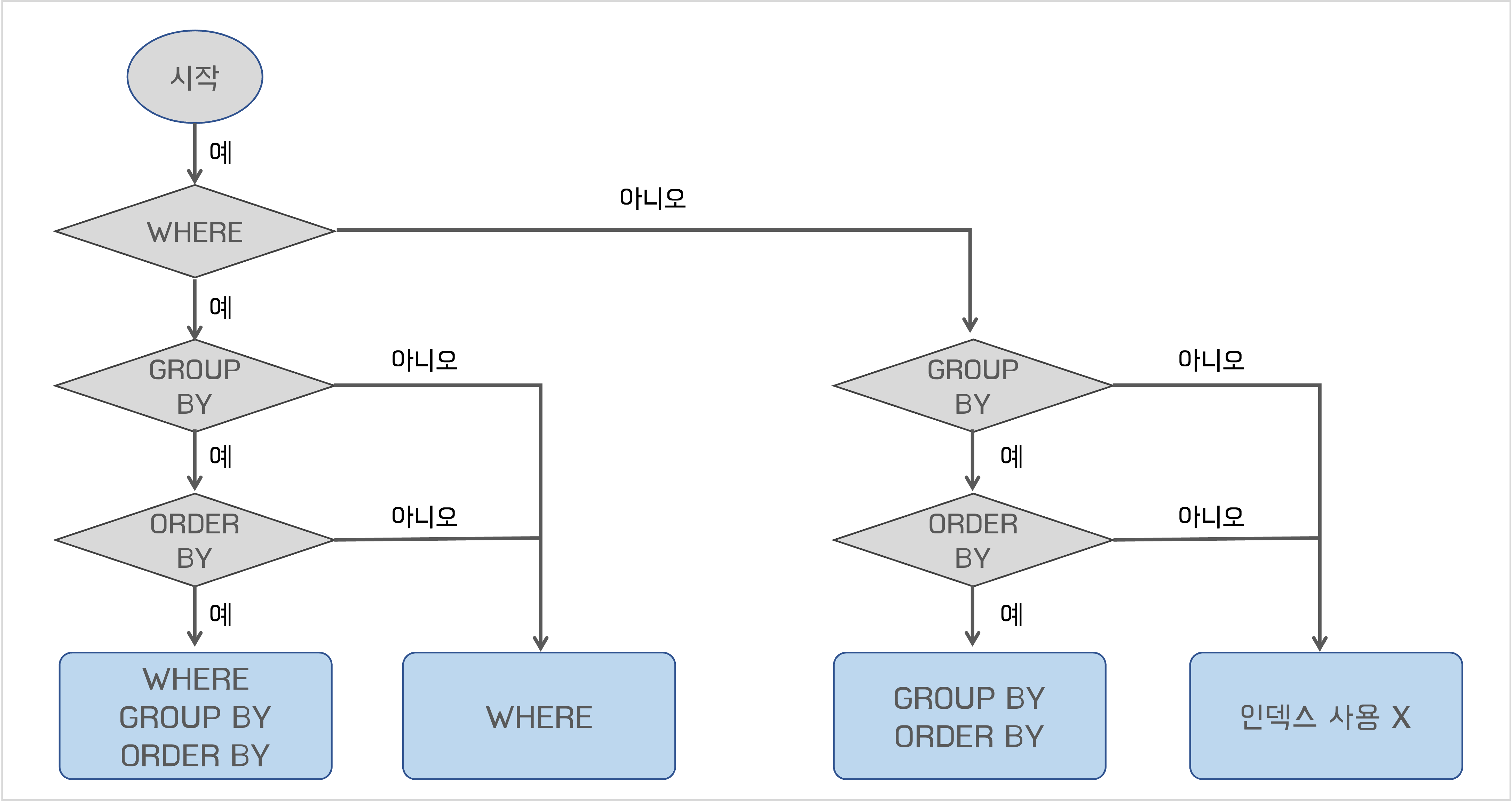
WHERE, GROUP BY, ORDER BY의 인덱스 사용
WHERE, GROUP BY, ORDER BY 모두 인덱스를 사용하려면 컬럼의 값을 변환하지 않고 사용해야함
WHERE 절의 인덱스 사용
- 작업 범위를 결정하기 위해 인덱스 사용
- 조건절에 사용된 컬럼과, 인덱스의 컬럼 구성이 왼쪽부터 비교해 얼마나 일치하는가에 따라 달라짐
- 순서가 다르더라도 MySQL 서버 옵티마이저는 인덱스를 사용할 수 있는 조건들을 뽑아서 최적화를 수행
- WHERE 조건절에 사용된 컬럼의 순서는 중요하지 않다 -> WHERE절의 조건 순서는 편하게 나열해도 된다
- 인덱스의 컬럼 순서는 중요하다
- WHERE 조건절에 사용된 컬럼의 구성은 중요하다
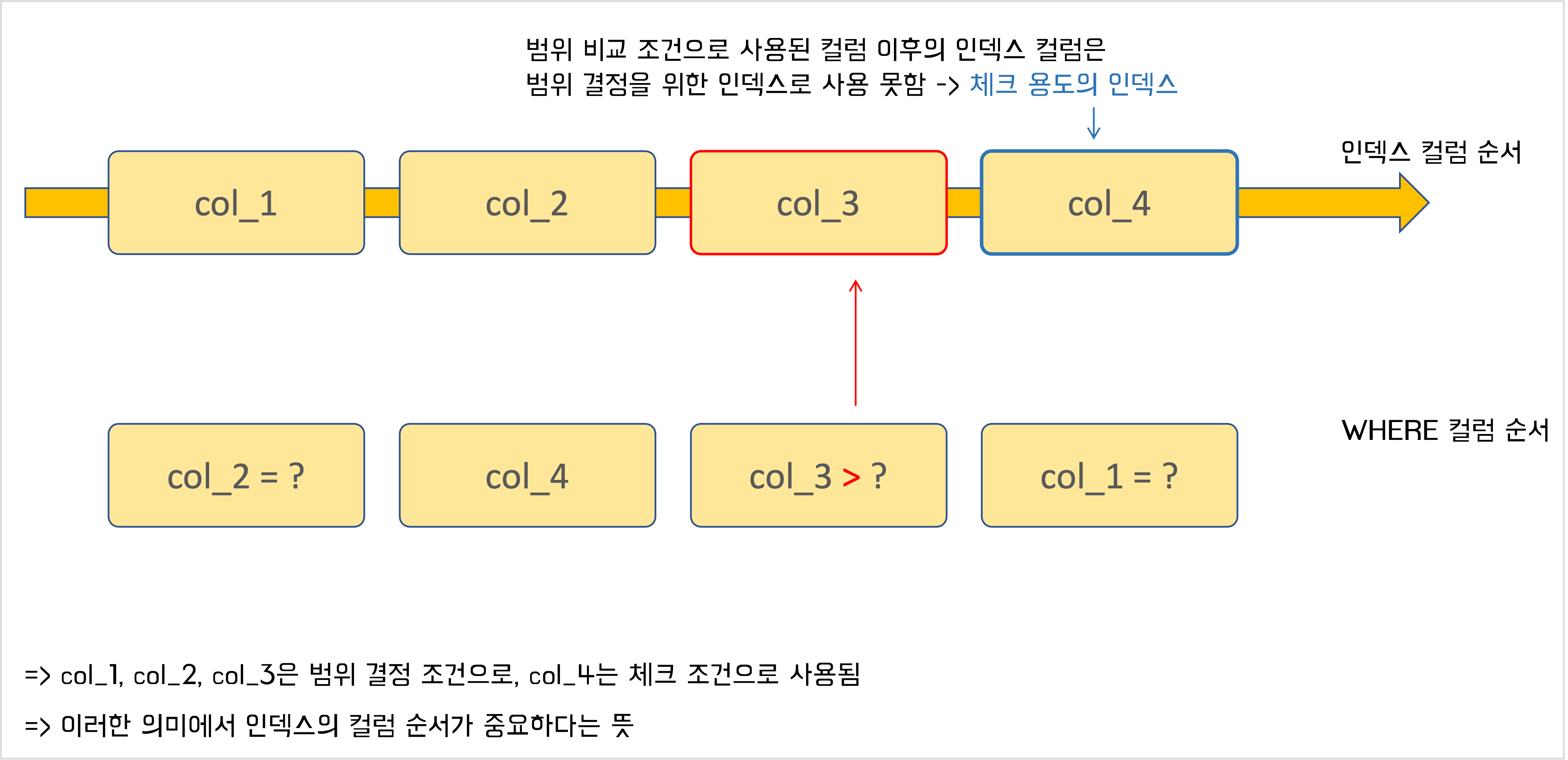
- 지금까지 설명은 WHERE 조건들이 서로 AND 관계일 때를 얘기한 것이다
- OR로 연결될 경우
- OR에 연결된 모든 컬럼들이 인덱스를 가지는 경우: 인덱스 머지 후 스캔
- (풀 테이블 스캔보단 빠르지만 인덱스 레인지 스캔보다는 느림)
- OR에 연결된 컬럼중 하나라도 인덱스가 없는 경우: 풀 테이블 스캔
- (풀 테이블 스캔 + 인덱스 레인지 스캔보다는 풀 테이블 스캔 1번이 더 빠르므로)
- OR에 연결된 모든 컬럼들이 인덱스를 가지는 경우: 인덱스 머지 후 스캔
GROUP BY 절의 인덱스 사용
- WHERE절과는 달리 인덱스의 컬럼 순서와 GROUP BY 절의 컬럼 순서, 위치가 같아야 함
- 인덱스의 컬럼과 GROUP BY 절의 컬럼은 왼쪽부터 일치해야함
- GROUP BY 에서 인덱스에 없는 컬럼을 하나라도 사용하면 인덱스 사용 못함
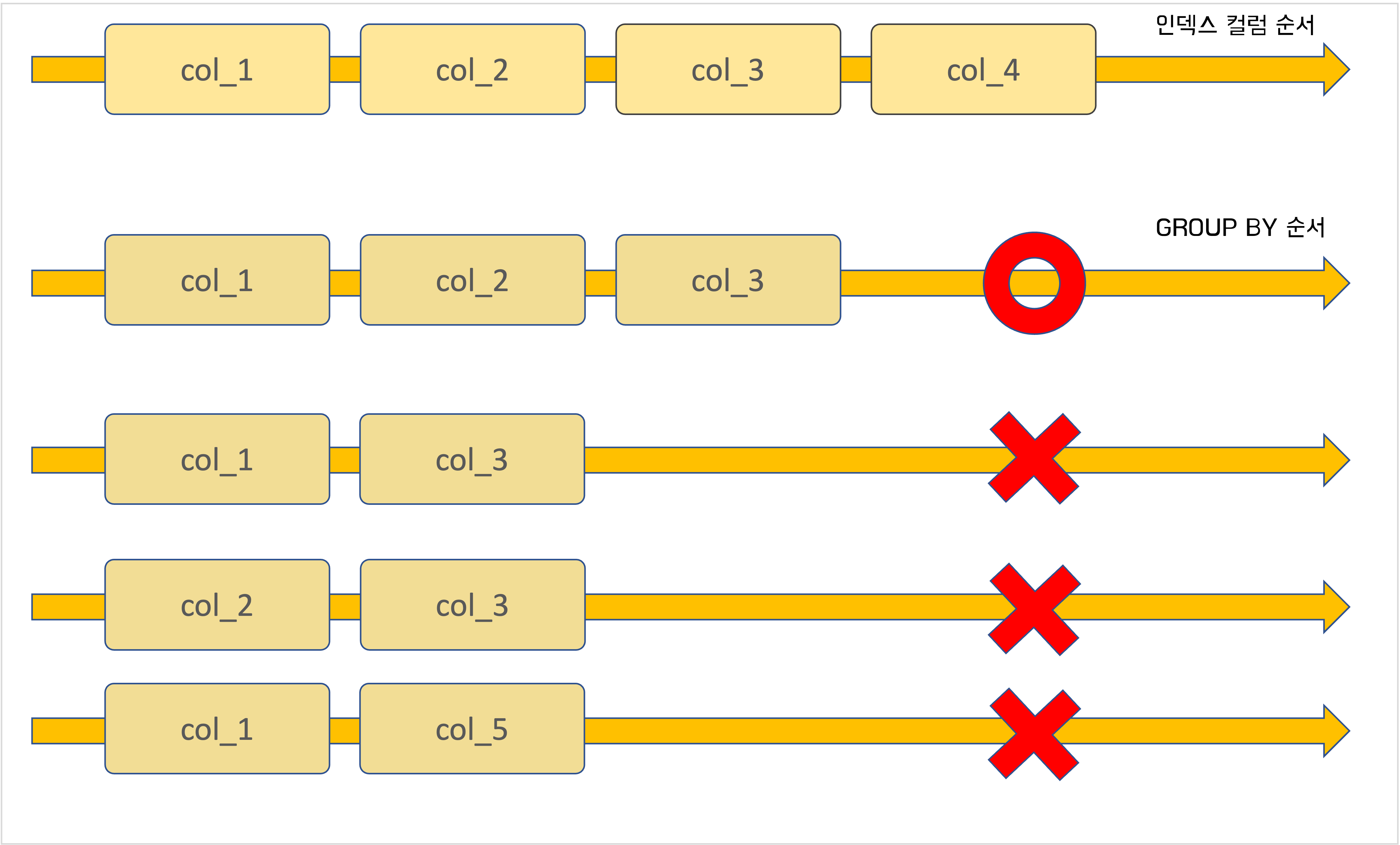
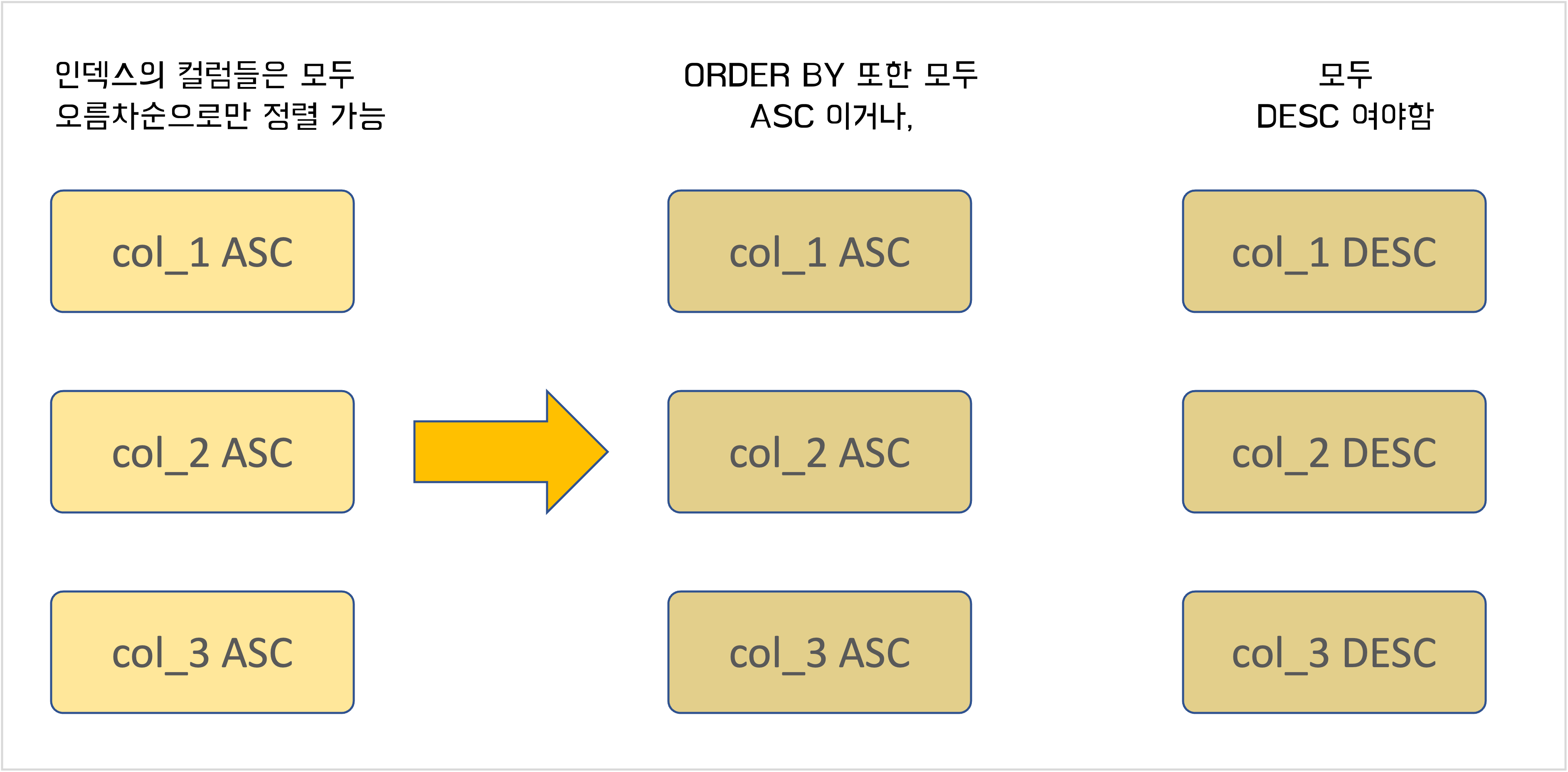
ORDER BY 절의 인덱스 사용
- GROUP BY와 거의 유사하다
- 한 가지 추가되는 조건은 인덱스의 각 컬럼의 ASC/DESC 이,
- ORDER BY의 각 컬럼의 ASC/DESC 과 모두 같거나 모두 반대인 경우에만 인덱스를 사용할 수 있다
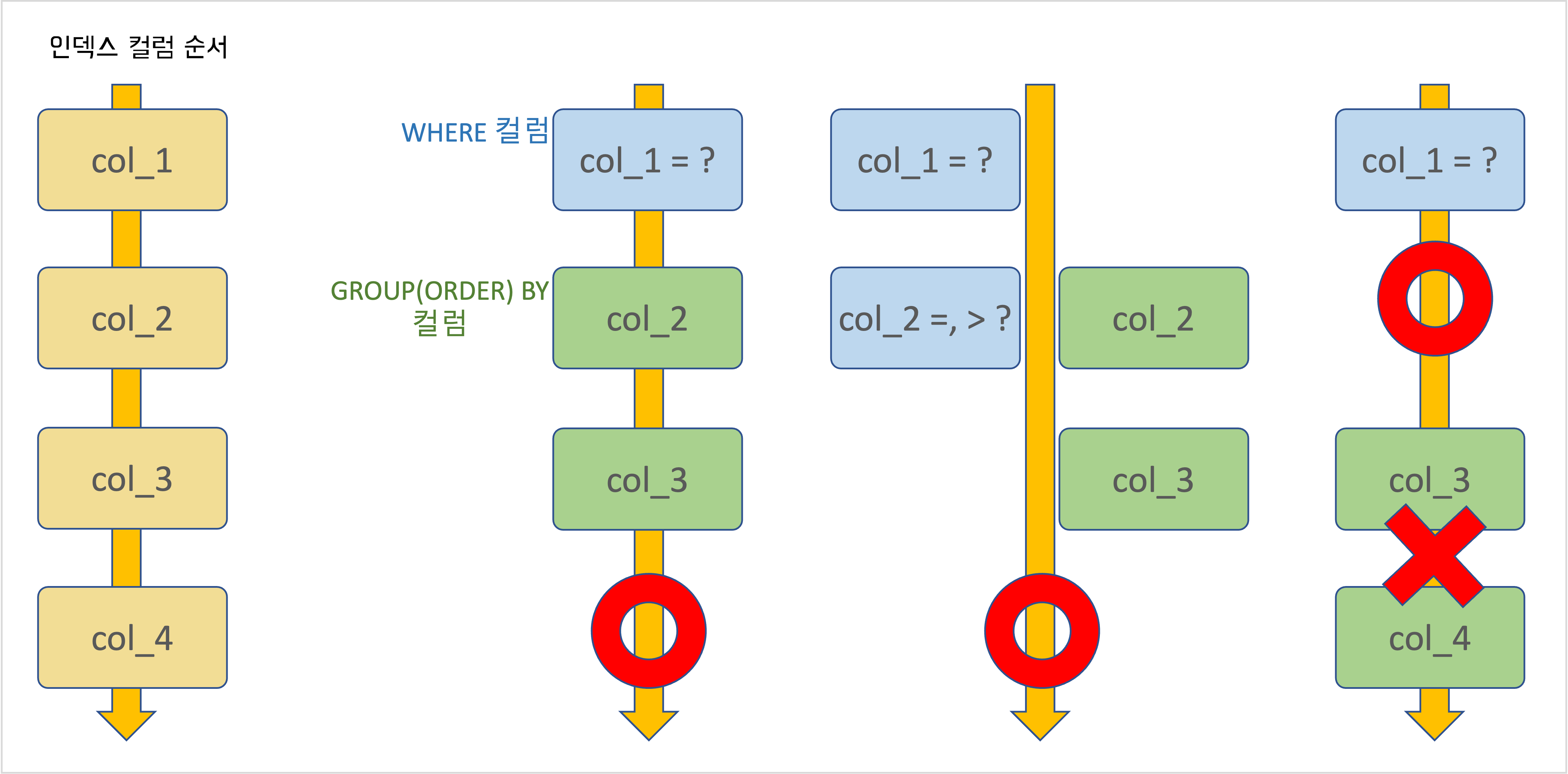
WHERE + (GROUP BY | ORDER BY) 의 인덱스 사용
- WHERE 절의 컬럼과 GROUP(ORDER) BY 절의 컬럼을 순서대로 나열했을 때 연속하면 둘 다 인덱스 사용 가능
- 중간에 빠지는 컬럼이 있으면 WHERE 절만 인덱스 사용 (가장 오른쪽 그림 참고)
GROUP BY + ORDER BY 의 인덱스 사용
- 두 절 모두 컬럼의 구성과 순서가 서로 같아야함
- 둘중 하나라도 인덱스를 사용할 수 없으면 둘 다 인덱스 사용 못함
WHERE + GROUP BY + ORDER BY 의 인덱스 사용
INSERT, UPDATE, DELETE문
- INSERT, UPDATE, DELETE 문은 크게 성능에 대해 고려할 부분이 많지 않음
- 테이블의 구조가 더 큰 영향을 미침
- 인덱스를 잘 설계하는 것이 중요
- 단조 증가하는 컬럼을 프라이머리 키로 선택하는 것이 좋음
- (SELECT문은 쿼리의 조건을 기준으로 프라이머리 키를 선택하는 것이 좋음)
- 보통 INSERT를 위한 프라이머리 키와 SELECT를 위한 프라이머리 키는 성능적인 측면에서 둘 중 하나를 선택해야함
- INSERT를 위해서는 보조인덱스가 적을수록 좋음
- (SELECT를 위해서는 쿼리에 이용되는 인덱스면 있는게 좋음)
실행 계획
- 실행 계획을 통해 쿼리의 불합리한 부분을 찾아내고, 더 최적화된 방법을 모색해보자
- 옵티마이저가 마법처럼 가장 최적의 방법을 찾아내진 못한다 -> 개발자의 역량이 중요
- EXPLAIN 명령을 통해 실행 계획 확인
-- 실행 계획 출력
EXPLAIN
SELECT
...
-- 쿼리의 실행 계획과 단계별 소요된 시간 정보 출력
EXPLAIN ANALYZE
SELECT
...
통계정보
- 옵티마이저는 실행 계획을 세울 때 통계 정보를 가장 많이 활용
- 통계 정보는 다음과 같은 것들을 의미
- 테이블의 전체 레코드 수
- 인덱스된 컬럼이 가지는 유니크한 값의 개수
- 각 컬럼의 데이터 분포도(히스토그램)
실행 계획 분석
EXPLAIN
SELECT *
FROM employees AS e
INNER JOIN salaries AS s
ON s.emp_no=e.emp_no
WHERE first_name='ABC';
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | e | NULL | ref | PRIMARY,ix_firstname | ix_firstname | 58 | const | 1 | 100.00 | NULL |
| 1 | SIMPLE | s | NULL | ref | PRIMARY | PRIMARY | 4 | employees.e.emp_no | 10 | 100.00 | NULL |
표의 각 라인은 쿼리 문장에서 사용된 테이블의 개수만큼 출력된다. 실행 순서는 위에서 아래로 순서대로 표시된다
| 구분 | 설명 |
|---|---|
| id | select 아이디로 SELECT를 구분하는 번호 |
| select_type | select에 대한 타입 |
| table | 참조하는 테이블 |
| type | 조인 혹은 조회 타입 |
| possible_keys | 데이터를 조회할 때 DB에서 사용할 수 있는 인덱스 리스트 |
| key | 실제로 사용할 인덱스 |
| key_len | 실제로 사용할 인덱스의 길이 |
| ref | Key 안의 인덱스와 비교하는 컬럼(상수) |
| rows | 쿼리 실행 시 조회하는 행 (통계에 기반한 추정) |
| filtered | 조회되지 않은 행 (통계에 기반한 추정) |
| extra | 추가 정보 |
id
- 행이 어떤 SELECT 구문을 나타내는 지를 알려주는 것으로 구문에 서브 쿼리나 UNION이 없다면 SELECT는 하나밖에 없기 때문에 모든 행에 대해 1이란 값이 부여되지만 이외의 경우에는 원 구문에서 순서에 따라 각 SELECT 구문들에 순차적으로 번호가 부여된다.
- (SELECT 문장은 하나인데, 여러 개의 테이블이 조인되는 경우에는 id값이 증가하지 않고 같은 id 값이 부여된다).
- 테이블 접근 순서와는 무관하다
select_type
- select에 대한 타입
| 구분 | 설명 |
|---|---|
| SIMPLE | 단순 SELECT (Union 이나 Sub Query 가 없는 SELECT 문) |
| PRIMARY | 메인 쿼리 (첫 번째 쿼리) |
| UNION | UNION 쿼리에서 Primary를 제외한 나머지 SELECT |
| DEPENDENT_UNION | UNION 과 동일하나, 외부쿼리에 의존적임 (값을 공급 받음) |
| UNION_RESULT | UNION 쿼리의 결과물 |
| SUBQUERY | Sub Query 또는 Sub Query를 구성하는 여러 쿼리 중 첫 번째 SELECT문 |
| DEPENDENT_SUBQUERY | Sub Query 와 동일하나, 외곽쿼리에 의존적임 (값을 공급 받음) |
| DERIVED | SELECT로 추출된 테이블 (FROM 절 에서의 서브쿼리 또는 Inline View) |
| UNCACHEABLE SUBQUERY | Sub Query와 동일하지만 공급되는 모든 값에 대해 Sub Query를 재처리. 외부쿼리에서 공급되는 값이 동이라더라도 Cache된 결과를 사용할 수 없음 |
| UNCACHEABLE UNION | UNION 과 동일하지만 공급되는 모든 값에 대하여 UNION 쿼리를 재처리 |
table
- 행이 어떤 테이블에 접근하는 지를 보여주는 것으로 대부분의 경우 테이블 이름이나 SQL에서 지정된 별명 같은 값을 나타낸다.
type
- 쿼리 실행 계획에서 type 이후의 컬럼은 MySQL서버가 각 테이블의 레코드를 어떤 방식으로 읽었는지를 나타냄
- (type, possible_keys, key, ..)
- 여기서 말하는 방식은 인덱스 레인지 스캔, 인덱스 풀 스캔, 테이블 풀 스캔 등을 의미
- 보통
WHERE,ON과 같은 조건절에 어떤 컬럼, 어떤 연산자를 사용했는지에 따라 달라짐 - 만약 type의 결과가
system,const,eq_ref,ref인 경우에는 쿼리문을 튜닝하지 않아도 됨 - 아래의 접근 방식은 성능이 빠른 순서대로 나열된 것
| 구분 | 설명 |
|---|---|
| system | 1개 이하의 레코드를 가지는 테이블을 참조하는 경우 |
| const | 쿼리의 WHERE 조건절에 프라이머리 키 또는 유니크 키 컬럼을 이용해 1건의 레코드를 반환하는 경우 |
| eq_ref | 조인이 포함된 쿼리에서 조인할 때 이용한 컬럼이 프라이머리 키인 경우 -> 1건의 레코드만 존재 -> const만큼 빠름 |
| ref | 조인을 할 때 프라이머리 키 또는 유니크 키가 아닌 키로 매칭하는 경우 |
| fulltext | 전문 검색 인덱스를 사용해 레코드를 읽는 접근 방법 |
| ref_or_null | ref 와 같지만 null 이 추가되어 검색되는 경우 |
| unique_subquery | WHERE col1 IN (subquery) 에서 subquery의 결과가 col1에 대해 유니크한 경우 |
| index_subquery | WHERE col1 IN (subquery) 에서 subquery의 결과가 col1에 대해 유니크하지 않은 경우 |
| range | 인덱스 레인지 스캔. 인덱스를 <, >, IS NULL, BETWEEN, IN, LIKE와 같은 연산자를 이용해 검색할 때 |
| index_merge | 두 개의 인덱스가 병합되어 검색이 이루어지는 경우 |
| index | 인덱스 풀 스캔. 주어진 조건절로 인덱스 레인지 스캔을 할 수 없는 경우. 인덱스 컬럼만으로 결과를 반환할 수 있는 경우. 테이블 풀 스캔보다는 빠름 |
| ALL | 테이블 풀 스캔. 위에서 하나도 해당되는 경우가 없을 때, 테이블 크기가 그렇게 크지 않을 때 사용 |
possible_keys
- 쿼리에서 접근하는 컬럼들과 사용된 비교 연산자들을 바탕으로 어떤 인덱스를 사용할 수 있는지를 표시해준다.
key
- 테이블에 접근하는 방법을 최적화 하기 위해 어떤 인덱스를 사용하기로 결정했는지를 나타낸다.
- 표시된 값이 PRIMARY인 경우에는 프라이머리 키를 사용한다는 의미. 나머지는 인덱스에 부여한 이름
key_len
- MySQL이 인덱스에 얼마나 많은 바이트를 사용하고 있는 지를 보여준다. MySQL에서 인덱스에 있는 컬럼들 중 일부만 사용한다면 이 값을 통해 어떤 컬럼들이 사용되는지를 계산할 수 있다.
ref
- 동등 비교 조건으로 어떤 값을 참조했는지를 나타낸다
- 상수값이면 const, 다른 테이블의 컬럼을 참조한 경우 컬럼명으로 표시된다
rows
- 원하는 행을 찾기 위해 얼마나 많은 행을 읽어야 할 지에 대한 예측값을 의미한다.
extra
- 추가 정보
| 구분 | 설명 |
|---|---|
| using index | 커버링 인덱스라고 하며 인덱스 자료 구조를 이용해서 데이터를 추출 |
| using where | where 조건으로 데이터를 추출. type이 ALL 혹은 Indx 타입과 함께 표현되면 성능이 좋지 않다는 의미 |
| using filesort | 데이터 정렬이 필요한 경우로 메모리 혹은 디스크상에서의 정렬을 모두 포함. 결과 데이터가 많은 경우 성능에 직접적인 영향을 줌 |
| using temporary | 쿼리 처리 시 내부적으로 temporary table이 사용되는 경우를 의미함 |
MySQL Explain 상 일반적으로 데이터가 많은 경우 Using Filesort 와 Using Temporary 상태는 좋지 않으며 쿼리 튜닝 후 모니터링이 필요하다.
참고
- MySQL 공식문서: Optimizing SELECT Statements
- MySQL Performance Tuning and Optimization Tips
- nomadlee, MySQL Explain 실행계획 사용법 및 분석
- ETL 성능 향상을 위한 몇 가지 팁들
- 전지적 송윤섭시점 TIL, GROUP BY 최적화
- SQL 성능을 위한 25가지 규칙
- 패스트캠퍼스 SQL튜닝캠프 4일차 - 조인의 기본 원리와 활용
- 취미는 공부 특기는 기록, Nested Loop Join, Driving Table
- stackoverflow, Does the join order matter in SQL?
- 코딩팩토리, [DB] 데이터베이스 NESTED LOOPS JOIN (중첩 루프 조인)에 대하여
- 고동의 데이터 분석, [SQL] “성능 관점”에서 보는 결합(Join)
- 고동의 데이터 분석, [SQL] 성능 관점에서의 서브쿼리(Subquery)
- GeeksforGeeks, IN vs EXISTS in SQL
- 인파, [MYSQL] 📚 서브쿼리 연산자 EXISTS 총정리 (성능 비교)