



































Table of Contents
np.nan == np.nan은 False다
np.nan이 포함된 값을== np.nan으로 잡아내려 하면 안된다- (참고로
None==None은True다)
np.nan == np.nan
-------------------
False
NaN은 논리적 오류를 발생시킨다
- 다음과 같은 데이터가 있다고 해보자.

condition_A = df['col2'] > 5
not_condition_A = df['col2'] <= 5
df[condition_A]
df[not_condition_A]
NaN은 5보다 크지도 작지도 않다. 그래서condition_A에도,not_condition_A에도 속하지 않는다- 당연해 보이지만, 나중에 데이터가 커지면 ‘A에 안속하니 당연히 not A에 속하겠지?’라고 생각하지만 어디에도 속하지 않는 결과를 초래한다

condition_A의 여집합은 그러면 어떻게 얻을 수 있을까
df[condition_A.eq(False)]

NaN 여부 체크하기
- 다음과 같은 데이터가 있다고 해보자

NaN 인지 확인하기
df.isna()
# isna() 의 반대는 notna()
# df.notna()

전체 데이터프레임에 NaN 값 여부
df.isna().any().any()
----------------------
True
각 컬럼별 NaN 개수
df.isna().sum()
----------------------
A 1
B 1
C 1
D 1
E 2
# 각 행별 NaN 개수
# df.isna().sum(axis=1)
NaN 값이 하나라도 있는 컬럼
df.isna().any().index
------------------------
Index(['A', 'B', 'C', 'D', 'E'], dtype='object')
NaN 값이 하나라도 있는 행
df[df.isna().any(axis=1)]

NaN 값이 하나도 없는 컬럼
df.dropna(axis=1)
NaN 값이 하나도 없는 행
df.dropna(axis=0)
NaN 값 가지는 데이터프레임간의 동등 비교
- 정답은
equals() equals()는 NaN을 고려해서 동등 비교한다
df.equals(df)
------------------
True
- (
(df == df).all().all()이렇게 같은 것끼리 비교해도np.nan == np.nan은False여서False가 된다)
df == df
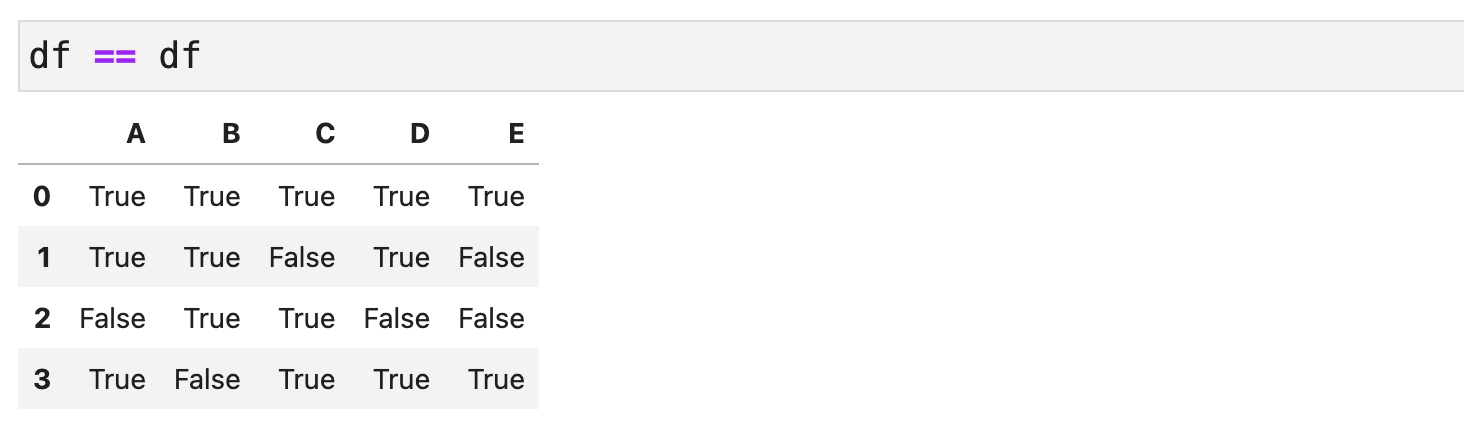
(df == df).all().all()
--------------------------
False
NaN 값 처리하기
NaN 값 가지는 행 날리기
df.dropna(axis=0)

NaN 값 가지는 컬럼 날리기
df.dropna(axis=1)

NaN 값 채우기

# 0으로 채우기
df.fillna(0)

# 앞에 있는 값으로 채우기
df.fillna(method='ffill')
