



































Table of Contents
그룹별 집계 연산

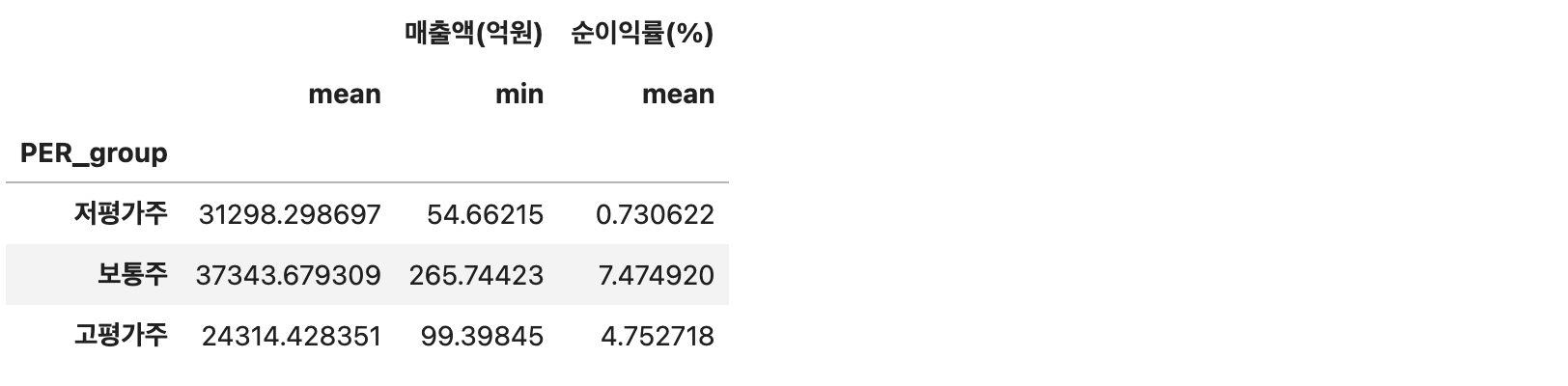
df.groupby('PER_group').agg(
{
'매출액(억원)': ['mean', 'min'],
'순이익률(%)': 'mean'
}
)
- 아래와 같은 방법도 가능하지만, 위 방식이 가장 자유도가 높다
# df.groupby('PER_group')[['매출액(억원)', '순이익률(%)']].mean()
# df.groupby('PER_group')[['매출액(억원)', '순이익률(%)']].agg(['mean', 'min'])
그룹 만들기
그룹간 범위 직접 정하기
pd.cut(x=df['PER(배)'],
bins=[-np.inf, 10, 20, np.inf],
labels=['저평가주', '보통주', '고평가주'])

df['PER_group'] = pd.cut(x=df['PER(배)'],
bins=[-np.inf, 10, 20, np.inf],
labels=['저평가주', '보통주', '고평가주'])

그룹 균등하게 정하기
df['PER_group_2'] = pd.qcut(x=df['PER(배)'],
q=5,
labels=['유망', '추천', '안전', '위험', '고위험'])

df['PER_group_2'].value_counts()

그룹 정보
df.groupby(['PER_group', 'PER_group_2']).groups.keys()
------------------------------------------------------------------------------------------------------------
dict_keys([('고평가주', '고위험'), ('고평가주', '위험'), ('보통주', '안전'), ('보통주', '위험'), ('저평가주', '안전'), ('저평가주', '유망'), ('저평가주', '추천'), (nan, nan)])
df.groupby(['PER_group', 'PER_group_2']).size().to_frame()
