



































Table of Contents
- View
- CTE(Common Table Expression)
- Trigger
- Variables
- Stored Function
- Stored Procedure
- Cursor
- Script
- 참고
View
- 뷰(view)는 데이터베이스에 존재하는 일종의 가상 테이블로, 실제로 데이터를 저장하고 있지는 않음
- 테이블은 실제 데이터를 저장, 뷰는 그저 SELECT문이 실행되고 난 후의 이미지 같은 느낌
- 때에 따라 서브쿼리가 이중 중첩, 삼중 중첩되는 경우, 이 때 생기는 SELECT문의 복잡성을 줄이고자 뷰를 사용
- 특정 역할을 하는 SELECT문들을 뷰로 저장해서, 코드 스니펫처럼 필요할 때마다 가져와서 사용
- 뷰는 백엔드 개발자들의 자산
장점
- 특정 사용자에게 테이블 전체가 아닌 필요한 필드만을 보여줄 수 있음
- 쿼리의 재사용성
- 이미 실행된 서브쿼리라는 점에서 더 빠르다고 할 수 있음
단점
- 뷰는 수정할 수 없는 경우가 많음
- SUM, AVG와 같은 집계 함수가 있는 경우, UNION ALL, DISTINCT, GROUP BY가 포함된 경우
- 삽입, 삭제, 갱신 작업에 제한 사항이 많음
생성
CREATE VIEW <뷰 이름> AS
SELECT 필드1, 필드2, ...
FROM 테이블
WHERE 조건
수정
ALTER VIEW <뷰 이름> AS
SELECT 필드1, 필드2, ...
FROM 테이블
삭제
DROP VIEW <뷰 이름>
정보 확인
SHOW TABLES
SHOW CREATE VIEW <뷰 이름>
DESC <뷰 이름>
SELECT * FROM information_schema.views
WHERE table_schema = <DB>
CTE(Common Table Expression)
- 메모리에 임시 결과로 올려놓고 재사용
- 쿼리가 실행중인 동안에만 데이터가 메모리에 올라와 있음
- 순차적으로 쿼리 작성 가능
-- CTE 한 개 생성
WITH <CTE 테이블명> AS
(SELECT ...)
-- CTE 여러 개 생성
WITH
<CTE 테이블명1> AS (SELECT ...),
<CTE 테이블명2> AS (SELECT ...),
RECURSIVE CTE
- 스스로 추가적인 Record를 생성할 수 있음
- 그래서 반드시 UNION 사용해야함
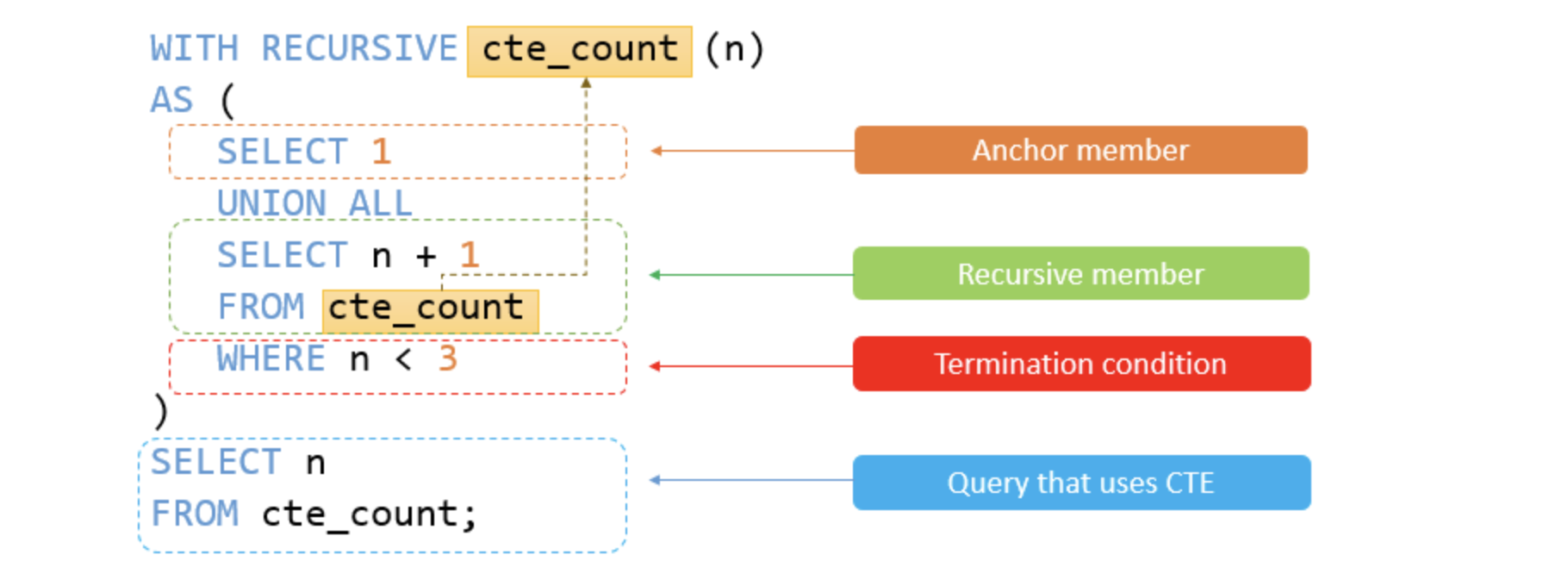
Table vs View
- 테이블은 데이터와 RDBMS에 관한 정보를 영구적으로 저장하는 저장소
- 뷰는 어떤 쿼리에 의해 생성된 가상의 테이블. 인덱싱 해놓지 않으면 데이터베이스에 별도로 저장되지 않음
View vs CTE
- 뷰는 데이터베이스에 존재하는 일종의 오브젝트(Object)
- 다른 곳에서도 쓰일 일이 있는 쿼리라면 뷰
- 다른 사용자들에게 데이터의 일부만 제공하고자 하는 경우 뷰
- CTE는 쿼리가 실행되는 동안에만 존재하는 임시 테이블
- Ad-hoc하게 사용하려는 경우 CTE
CTE vs Subquery
- CTE와 서브쿼리는 성능이나 결과적인 측면에서 다른 점이 없다
- 차이점은 CTE가 가독성이 더 좋다는 것, CTE는 재귀적으로 호출해 완전히 새로운 테이블을 만들 수 있다
Trigger
CREATE Trigger <trigger-name>
{ BEFORE | AFTER } { INSERT | UPDATE | DELETE }
{ PRECEDES | FOLLOWS } <other-trigger-name>
ON <table-name> FOR EACH ROW
BEGIN
OLD.<col> ... -- OLD: UPDATE 이거나 DELETE일 때 적용된 레코드
NEW.<col> ... -- NEW: UPDATE 이거나 INSERT일 때 새로 추가된 레코드
END
DELETE 예시
- Emp 테이블에서 직원 한 명이 나갔을 때
- 해당 직원 부서의 인원을 1 감소시킨다
CREATE Trigger Emp_AFTER_DELETE AFTER DELETE ON Emp FOR EACH ROW
BEGIN
UPDATE Dept SET empcnt = empcnt - 1
WHERE id = OLD.dept;
END
UPDATE 예시
- Emp 테이블에서 개발부서 직원이 마케팅부서로 옮겼을 때
- (직원의 연봉이 업데이트된 경우에는 트리거 되면 안된다 -> IF OLD.dept != NEW.dept THEN 추가)
- 개발 부서의 직원 수는 1 감소, 마케팅 부서의 직원 수는 1 증가
DELIMITER $$
CREATE Trigger Emp_AFTER_UPDATE AFTER UPDATE ON Emp FOR EACH ROW
BEGIN
IF OLD.dept != NEW.dept THEN
UPDATE Dept SET empcnt = empcnt - 1
WHERE id = OLD.dept;
UPDATE Dept SET empcnt = empcnt + 1
WHERE id = NEW.dept;
END IF;
END $$
Variables
- 변수는 기본적으로 세션 단위로 실행
사용자 정의 변수
- 세션 내에 있는 여러 쿼리에서 사용 가능
@접두사 붙여야함- 변수는 크게
SET또는SELECT로 선언 가능
SET @x = 5; -- @x는 5로 초기화
SELECT @x; -- @x는 NULL로 초기화
SELECT @x := 5; -- @x는 5로 초기화
지역 변수
- 사용자 정의 변수보다 더 범위가 좁은 변수
- 지역의 범위는
BEGIN과END사이를 의미 - (
BEGIN과END는 프로시저나 함수 또는 트리거 안에 여러 문(Statement)을 작성하기 위한 용도로 사용된다) DECLARE로 선언
-- 프로시저나, 함수, 트리거와 같은 스토어드 프로그램은 여러 실행문이 ;로 끝나지만 하나로 묶어줘야 한다.
-- 그래서 구분자를 //로 임시 변경
DELIMITER //
CREATE PROCEDURE sp_test()
BEGIN
DECLARE start INT; -- 선언만 할 수도 있다
DECLARE end INT DEFAULT 10; -- 기본값을 설정할 수 있다
-- 변수에 값을 할당하는 두 가지 방법
SET start = 5; -- 선언된 지역 변수에 값을 할당
SELECT num INTO start FROM num_table WHERE id = 1; -- 이런식으로 SELECT문으로 가져온 값을 넣을 수도 있다
END //
서버 시스템 변수
- 서버에 이미 저장된 시스템 변수
@@접두사를 통해 값에 접근 가능SELECT를통해 값을 읽을 수도 있고,SET을 통해 값을 새로 할당할 수도 있다
SELECT @@sort_buffer_size; -- 이미 서버에 저장된 변수기 때문에 할당없이 바로 읽어올 수 있다
SET @@sort_buffer_size=1000000; -- SET을 통해 값을 새로 할당할 수도 있다
Stored Function
- 일련의 문을 실행한 뒤 값을 리턴하고 싶은 경우
- 사용할 때는 내장함수 처럼
SELECT function-name(col1) FROM table-name;이렇게 사용하면 됌
DELIMITER $$
CREATE FUNCTION <function-name>(<param> <type>, ..)
RETURNS <return-type>
BEGIN
...
RETURN <return-value>;
END $$
DELIMITER $$
CREATE FUNCTION ts_to_dt(_ts TIMESTAMP)
RETURNS VARCHAR(31)
BEGIN
RETURN DATE_FORMAT(_ts, '%m/%d %H:%i');
END $$
ts_to_dt(CURRENT_TIMESTAMP);
Stored Procedure
- 프로시저는 함수와 비슷
- 차이점은 함수는 뭔가를 변환하고 리턴하는 것에 초점
- 프로시저는 그냥 실행하는 것에 초점
- 실행 중간에 멈추고 싶으면
LEAVE사용
DROP Procedure IF EXISTS <procedure-name>;
DELIMITER $$
CREATE Procedure <procedure-name>([IN | OUT | INOUT] <param> <type>, ..)
BEGIN
...
END $$
CALL <procedure-name>([IN parameters, OUT variables]);
DELIMITER $$
CREATE Procedure plus_ten_procedure(IN i_1 INT, OUT o_1 INT)
BEGIN
SET o_1 = i_1 + 10
END $$
-- CALL 을 통해 프로시저 호출
CALL plus_ten_procedure(5, @a); -- @a 변수에 값이 저장됨
SET @b = @a; -- 이런식으로 써도 되고,
SELECT @a, @b; -- 이런식으로 써도 되고,
CALL plus_ten_procedure(@a); -- 이런식으로 써도 된다
CREATE Procedure <procedure-name>()
stepA:BEGIN -- BEGIN ~ END 블록을 stepA 이런식으로 명명할 수 있음
...
IF <condition> THEN
LEAVE stepA; -- LEAVE를 통해 stepA 를 종료시킬 수 있음. stepA 안에 포함된 쿼리문의 부하가 굉장히 큰 경우 유용하다
END IF;
...
END
Cursor
- SELECT문으로 뽑아온 테이블의 ROW에 한 개씩 접근하고 싶을 때
Script
IF
IF ... THEN
...
ELSE IF ... THEN
...
ELSE
...
END IF;
CASE
CASE
WHEN ... THEN ...;
WHEN ... THEN ...;
...
ELSE ...
END CASE;
WHILE
WHILE (...) DO
...
END WHILE;
참고
- stackoverflow, Difference between View and table in sql
- stackoverflow, CTE vs View Performance in SQL Server
- LearnSQL, What’s the Difference Between SQL CTEs and Views?
- stackoverflow, Is there any performance difference btw using CTE, view and subquery?
- 인파, [MYSQL] 📚 WITH (임시 테이블 생성)
- inyong_pang, [MySQL] MySQL Variables(변수) 만들기