Table of Contents
인덱스 확인
SHOW INDEX
FROM <테이블>
- Table: 테이블의 이름을 표시함.
- Non_unique: 인덱스가 중복된 값을 저장할 수 있으면 1, 저장할 수 없으면 0을 표시함.
- Key_name: 인덱스의 이름을 표시하며, 인덱스가 해당 테이블의 기본 키라면 PRIMARY로 표시함.
- Seq_in_index: 인덱스에서의 해당 필드의 순서를 표시함.
- Column_name: 해당 필드의 이름을 표시함.
- Collation: 인덱스에서 해당 필드가 정렬되는 방법을 표시함.
- Cardinality: 인덱스에 저장된 유일한 값들의 수를 표시함.
- Sub_part: 인덱스 접두어를 표시함.
- Packed: 키가 압축되는(packed) 방법을 표시함.
- Null: 해당 필드가 NULL을 저장할 수 있으면 YES를 표시하고, 저장할 수 없으면 ‘‘를 표시함.
- Index_type: 인덱스에 사용되는 메소드(method)를 표시함.
- Comment: 해당 필드를 설명하는 것이 아닌 인덱스에 관한 기타 정보를 표시함.
- Index_comment: 인덱스에 관한 모든 기타 정보를 표시함.
인덱스 통계 정보 확인
SHOW TABLE STATUS LIKE <테이블>
인덱스 생성
Create Table 내
CREATE TABLE books (
-- 같이 지정
id varchar(5) primary key, -- 기본키 지정 (클러스터 인덱스)
name varchar(20) unique, -- 인덱스 생성 (유니크 보조 인덱스)
writer varchar(20) NOT NULL,
INDEX idx_test (writer asc) -- 인덱스 생성 (보조 인덱스)
);

Create Index 문
CREATE INDEX 인덱스명 ON 테이블명 (컬럼명); -- 보조 인덱스 생성 (중복 허용)
CREATE UNIQUE INDEX 인덱스명 ON 테이블명 (컬럼명); -- 유니크 보조 인덱스 생성 (중복 비허용)
CREATE FULLTEXT INDEX 인덱스명 ON 테이블명 (컬럼명); -- 클러스터 인덱스 생성
CREATE UNIQUE INDEX 인덱스명 ON 테이블명 (컬럼명1, 컬러명2); -- 다중 컬럼 인덱스 생성
ANALYZE TABLE 테이블명; -- !! 생성한 인덱스 적용 !!
ALTER TABLE ADD INDEX 문
ALTER TABLE 테이블이름
ADD INDEX 인덱스이름 (필드이름)
-- 중복을 허용하는 인덱스.
-- 보조 인덱스.
-- 가장 느리지만 인덱스 안한 컬럼 조회하는 것보다 인덱스 붙인 컬럼 조회하는게 더 빠르다. 여러개 노멀키 를 지정할수 있다.
ALTER TABLE 테이블이름
ADD UNIQUE INDEX 인덱스이름 (필드이름)
-- 중복을 허용하지 않는 유일한 키. null 허용.
-- 보조 인덱스.
-- 고속으로 조회 가능
ALTER TABLE 테이블이름
ADD PRIMARY KEY INDEX 인덱스이름 (필드이름)
-- 중복되지 않은 유일한 키. null 비허용.
-- 클러스터 인덱스
-- where로 데이터를 조회할때 가장 고속으로 조회
ALTER TABLE 테이블이름
ADD FULLTEXT INDEX 인덱스이름 (필드이름)
-- 풀텍스트 인덱스
-- 긴 문자열 데이터를 인덱스로 검색할 때 사용.
인덱스 삭제
보조인덱스 삭제
ALTER TABLE 테이블이름
DROP INDEX 인덱스이름
클러스터 인덱스 삭제
ALTER TABLE 테이블이름
DROP PRIMARY KEY; -- 만일 외래키와 연결이 되어있을 경우 제약조건에 의해 삭제가 안될수 있음
Execution Plan
EXPLAIN SELECT ...
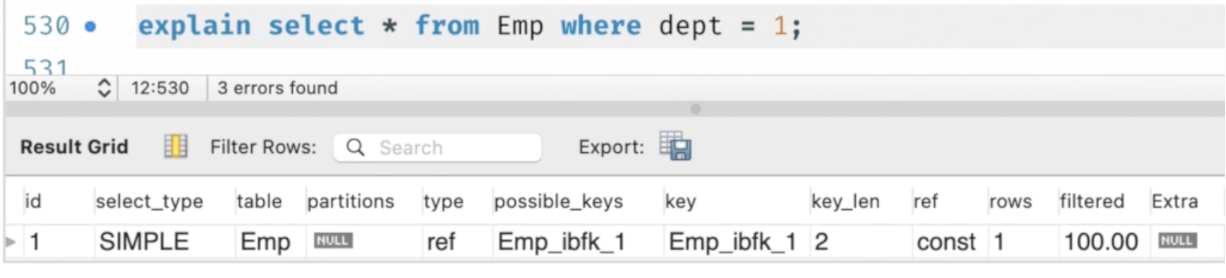
| 구분 | 설명 |
| id | select 아이디로 SELECT를 구분하는 번호 |
| select_type | select에 대한 타입 |
| table | 참조하는 테이블 |
| type | 조인 혹은 조회 타입 |
| possible_keys | 데이터를 조회할 때 DB에서 사용할 수 있는 인덱스 리스트 |
| key | 실제로 사용할 인덱스 |
| key_len | 실제로 사용할 인덱스의 길이 |
| ref | Key 안의 인덱스와 비교하는 컬럼(상수) |
| rows | 쿼리 실행 시 조회하는 행 (통계에 기반한 추정) |
| filtered | 조회되지 않은 행 (통계에 기반한 추정) |
| extra | 추가 정보 |
Sargable Query
- 인덱스를 효율적으로 사용할 수 없는 경우: 인덱스 풀 스캔하는 경우
-
인덱스를 효율적으로 사용하는 경우: 인덱스 레인지 스캔, 루스 인덱스 스캔을 사용 -> 사거블(Sargable) 하다고 함
- where, order by, group by 등에는 가능한 index가 걸린 컬럼 사용.
- where 절에 함수, 연산, Like(시작 부분 %)문은 사거블하지 않다!
- between, like, 대소비교(>, < 등)는 범위가 크면 사거블하지 않다.
- or 연산자는 필터링의 반대 개념(로우수를 늘려가는)이므로 사거블이 아니다.
- offset이 길어지면 사거블하지 않는다.
- 범위 보다는 in 절을 사용하는 게 좋고, in 보다는 exists가 더 좋다.
- 꼭 필요한 경우가 아니라면 서브 쿼리보다는 조인(Join)을 사용하자.
Full-Text Index
- contents 컬럼에서 ‘무궁화’라는 단어를 가지는 레코드를 찾고 싶을 때
SELECT * FROM table WHERE contents LIKE '%무궁화%';라고 하면 인덱스 없이 풀 테이블 스캔 하게된다- Full-Text 인덱스를 만들면 contents 컬럼의 문자열을 파싱해서 인덱스로 저장하고, 그 인덱스를 이용해 찾아준다
- 여러 컬럼을 이용해 인덱스를 만들 수도 있다
- 인덱스를 이용해 SELECT 할 때는
MATCH와AGAINST를 사용하면 된다
SHOW INDEX FROM Product;

풀 텍스트 인덱스를 하나 만들어보자.
CREATE FULLTEXT INDEX <index-name>
ON <table>(col1, col2, ..)
CREATE FULLTEXT INDEX ft_idx_Product_name_category
ON Product(name, category);

SELECT * FROM Product WHERE MATCH(name, category) AGAINST('아이폰');

IN BOOLEAN MODE를 사용하면 조건을 더 디테일하게 걸 수 있다.
*: partial search ex. 아이폰* -> 아이폰, 아이폰은, 아이폰을, .. 다 매치해준다
+: required search ex. +스페이스 -> 아이폰 13 스페이스 그레이와 같이 스페이스가 무조건 포함되는 레코드만 매치해준다
-: excluded search ex. -스페이스 -> 아이폰 13 그린라이트와 같이 스페이스가 포함된 레코드를 제외시켜준다
SELECT * FROM Product WHERE MATCH(name, category) AGAINST('아이폰 -스페이스' IN BOOLEAN MODE);

단어가 어떤식으로 인덱싱되어 있는지 보기 위해 테이블을 하나 만들 수도 있다.
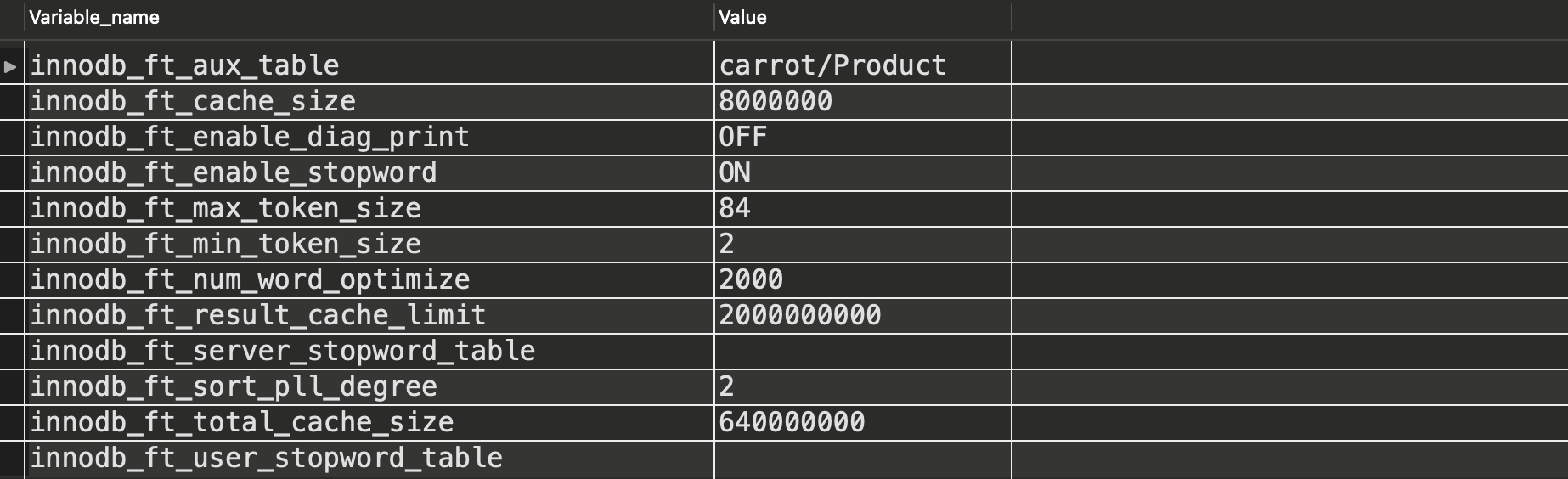
SET GLOBAL innodb_ft_aux_table = 'carrot/Product'; -- 스키마/테이블
SET GLOBAL innodb_optimize_fulltext_only = ON;
OPTIMIZE TABLE Product;
SET GLOBAL innodb_optimize_fulltext_only = OFF;
SELECT * FROM information_schema.innodb_ft_index_table;
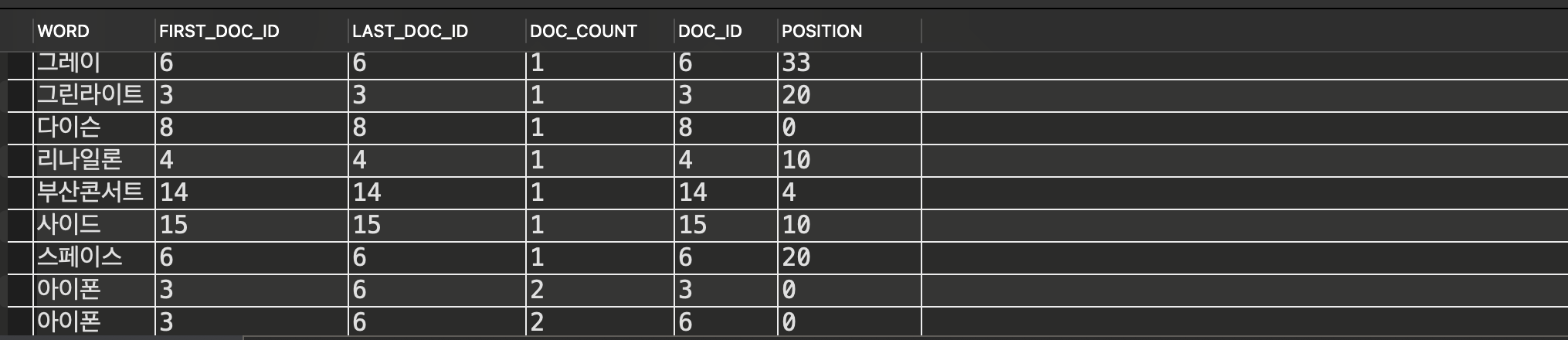
풀텍스트 관련 서버 설정값은 다음으로 확인할 수 있다.
SHOW VARIABLES LIKE 'innodb_ft%';