



































Table of Contents
MySQL의 전체 구조
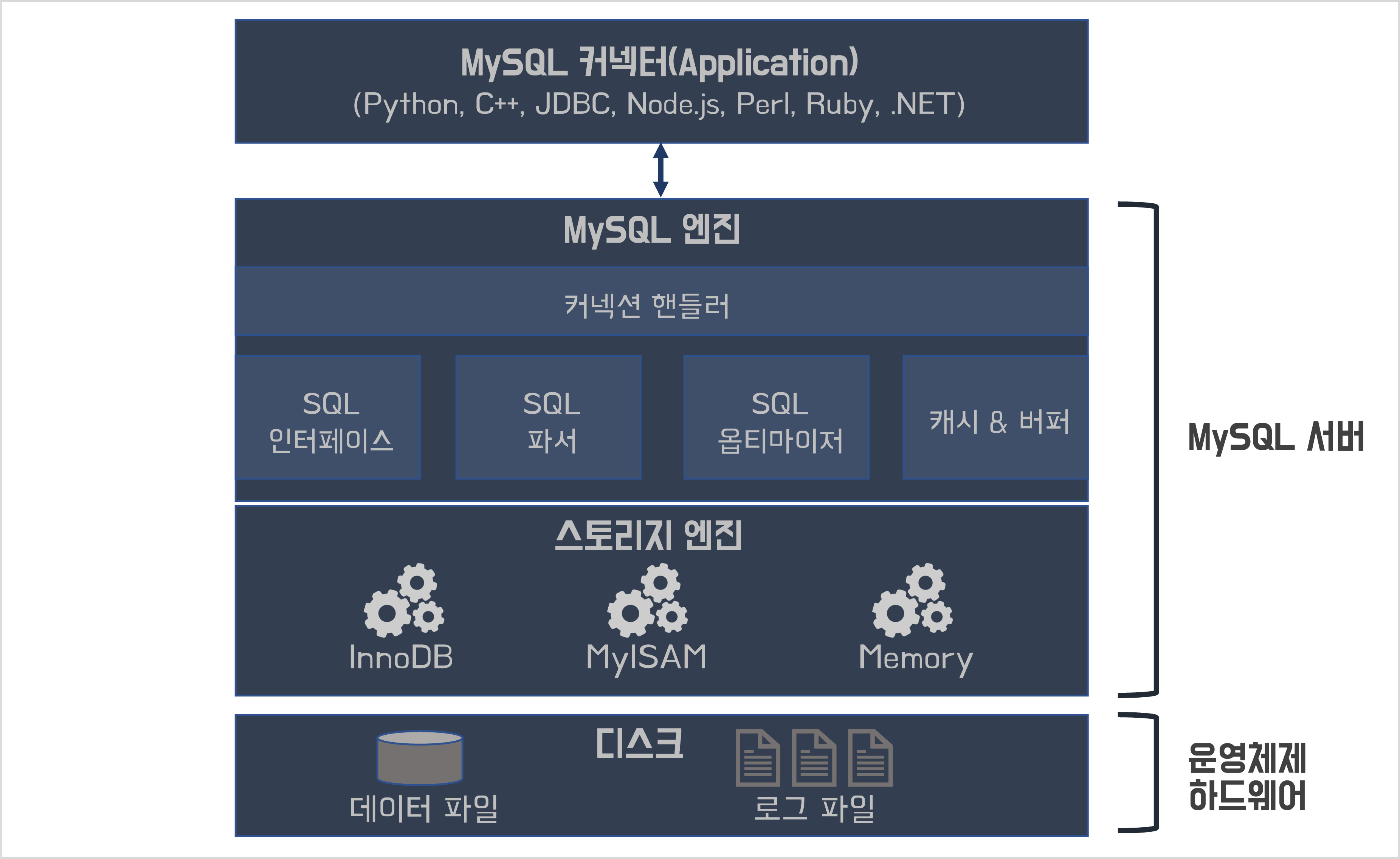
- MySQL 엔진: 요청된 SQL문장을 분석하거나 최적화하는 등 DBMS의 두뇌 역할
- 스토리지 엔진: 데이터를 디스크에 저장하거나 디스크로부터 읽어오는 역할
MySQL 엔진 아키텍처
- 커넥션 핸들러: 클라이언트의 접속, 쿼리 요청을 처리
- SQL 파서: 실행 이전에 문법성 오류 체크
- SQL 옵티마이저: 쿼리의 최적화
InnoDB 스토리지 엔진 아키텍처
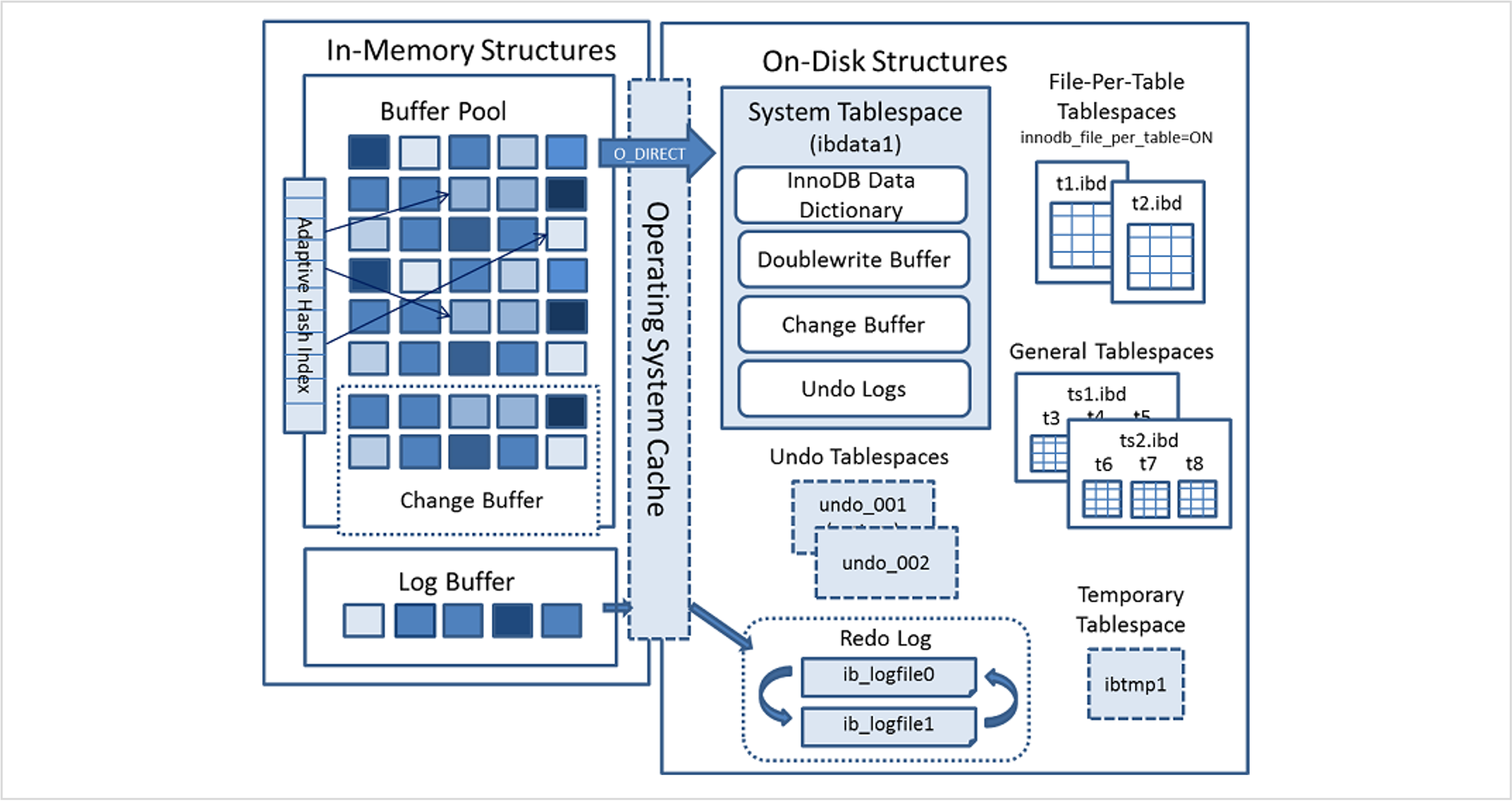
There is a metadata file (ibdata1, which holds, by default, data pages, index pages, table metadata and MVCC information), also known as the InnoDB tablespace file.
- You can have more than one ibdata file (see innodb_data_file_path)
- There are redo logs (ib_logfile0 and ib_logfile1)
- You can have more than two redo logs (see innodb_log_files_in_group)
- You can spread data and indexes across multiple ibdata files if innodb_file_per_table is disabled
- You can separate data and index pages from ibdata into separate tablespace files (see innodb_file_per_table and StackOverflow Post on how to set this up)
InnoDB 버퍼 풀
- 스토리지 엔진에서 가장 핵심적인 부분
- 데이터 캐시: 디스크의 데이터 파일이나 인덱스 정보를 메모리에 캐시해 두는 공간
- 쓰기 버퍼링: 쓰기 작업을 지연시켜 일괄 작업으로 처리할 수 있게 해주는 버퍼 역할
- 페이지 크기의 조각으로 쪼개어 디스크로부터 읽어온 페이지를 저장
- 메모리 공간을 관리하기 위해 LRU리스트, 플러시 리스트, 프리 리스트라는 자료구조를 관리
LRU 알고리즘
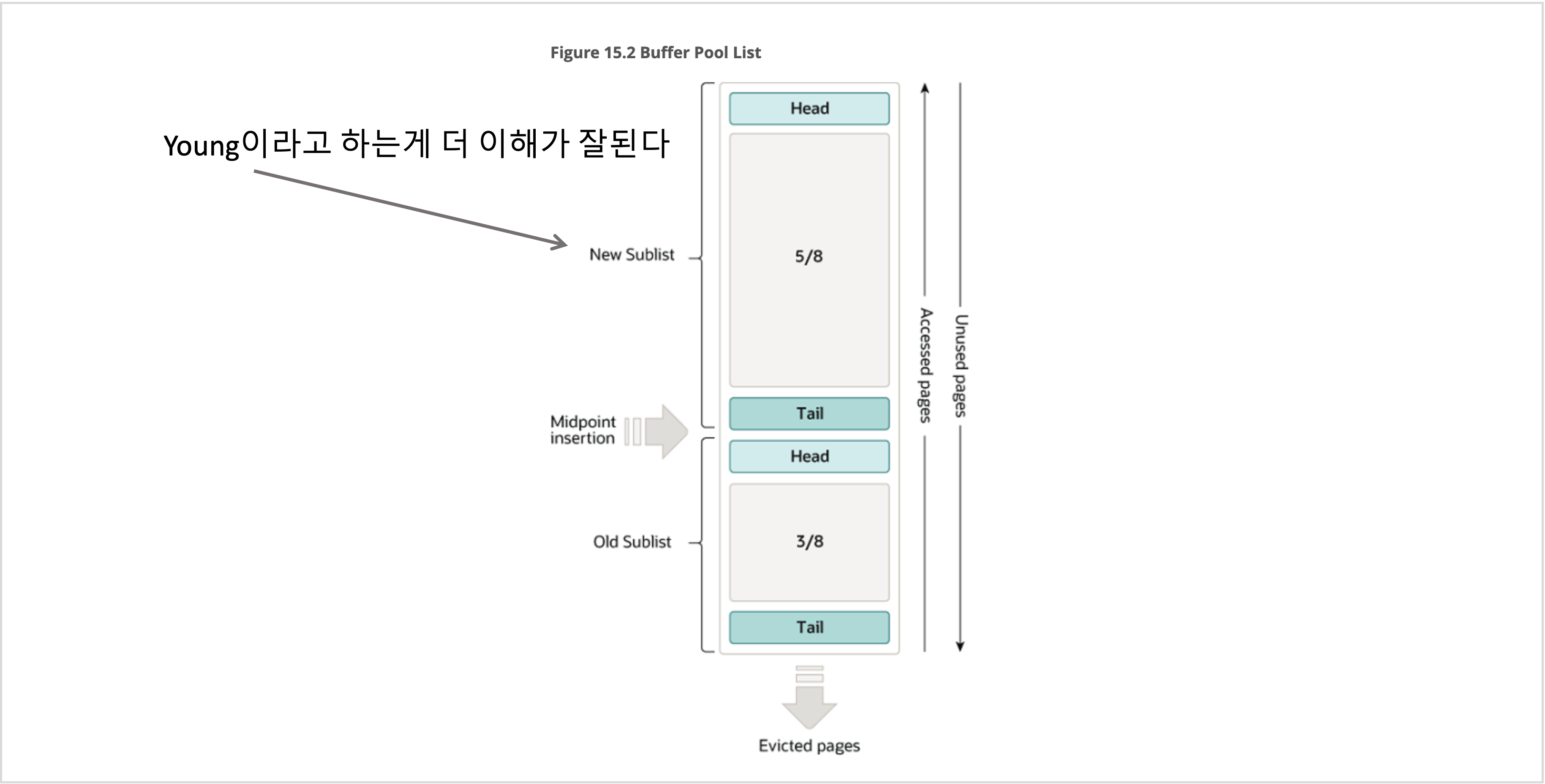
1. 테이블 데이터와 인덱스 데이터를 버퍼 풀에 캐시한다
2. 새로운 위치의 테이블 데이터 또는 인덱스 데이터를 버퍼 풀에 캐시하려는데 메모리에 더 이상 자리가 없다
3. 버퍼 풀에서 한동안 사용되지 않았던 페이지를 버퍼 풀에서 제거한다(만약 더티 페이지라면 플러시 후 제거)
4. 버퍼 풀에 있는 페이지들은 링크드 리스트 구조로 되어 있음
5. 이 링크드 리스트는 크게 두 개의 서브리스트로 구분됨 (New Sublist와 Old Sublist)
6. (저는 New대신 Young이라고 하겠습니다. 공식 문서에서도 Young이라고도 하는데, 저는 Young이 더 와닿기 때문에)
7. Young 서브리스트는 링크드 리스트의 HEAD에 가까운 5/8, Old 서브리스트는 링크드 리스트의 TAIL에 가까운 3/8
8. 이 Old 서브리스트가 삭제되는 페이지의 후보들이다(무조건 3/8이 다 삭제되는게 아니라, 필요한만큼 삭제됨)
9. 새로운 페이지는 Old 서브리스트의 HEAD로 감. 이 부분을 Midpoint라고도 함
-
페이지들은 어떤 작업에 의해 젊어지고 늙어갈까?
1. 유저의 SELECT 연산에 의해 데이터가 읽어지면 young해지고 Young 서브리스트의 제일 머리로 올라간다 2. InnoDB에 의해 자동적으로 수행되는 Read-ahead 작업으로 데이터가 young해질 수도 있음 3. SELECT 연산이 WHERE 조건문이 없으면 테이블 풀 스캔 -> young해질 수도 있음 자동적으로 위와 같은 작업에 해당되지 않는 데이터들은 old해짐 - 하지만 2번과 3번은 정말 의미있는 데이터를 young해지도록 하는 것은 아님 -> 이로 인해 오히려 중요한 데이터가 old해지는 악영향을 초래할 수도 있음
- MySQL 공식문서: Making the Buffer Pool Scan Resistant
- MySQL 공식문서: Configuring InnoDB Buffer Pool Prefetching (Read-Ahead)
- 위의 문서를 참고하면, 중요한 데이터를 버퍼 풀에 고정시키는 방법과 같은 것들을 알 수 있음
- (Read ahead는 읽기 패턴에 기반해 이 후 사용될 데이터가 포함된 특정 페이지들을 미리 버퍼 풀에 비동기적으로 프리패치하는 작업을 말한다)
체인지 버퍼
INSERT,UPDATE,DELETE와 같은 작업으로 인해 세컨더리 인덱스 페이지에 변경 사항이 생겼으나, 해당 페이지가 버퍼 풀에 없는 경우, 해당 변경 사항을 체인지 버퍼에 캐시해 둔다- 이 후 읽기 작업으로 세컨더리 인덱스 페이지가 버퍼 풀에 생기게 되면, 체인지 버퍼에 저장된 변경 사항을 버퍼 풀의 페이지로 병합시킨다
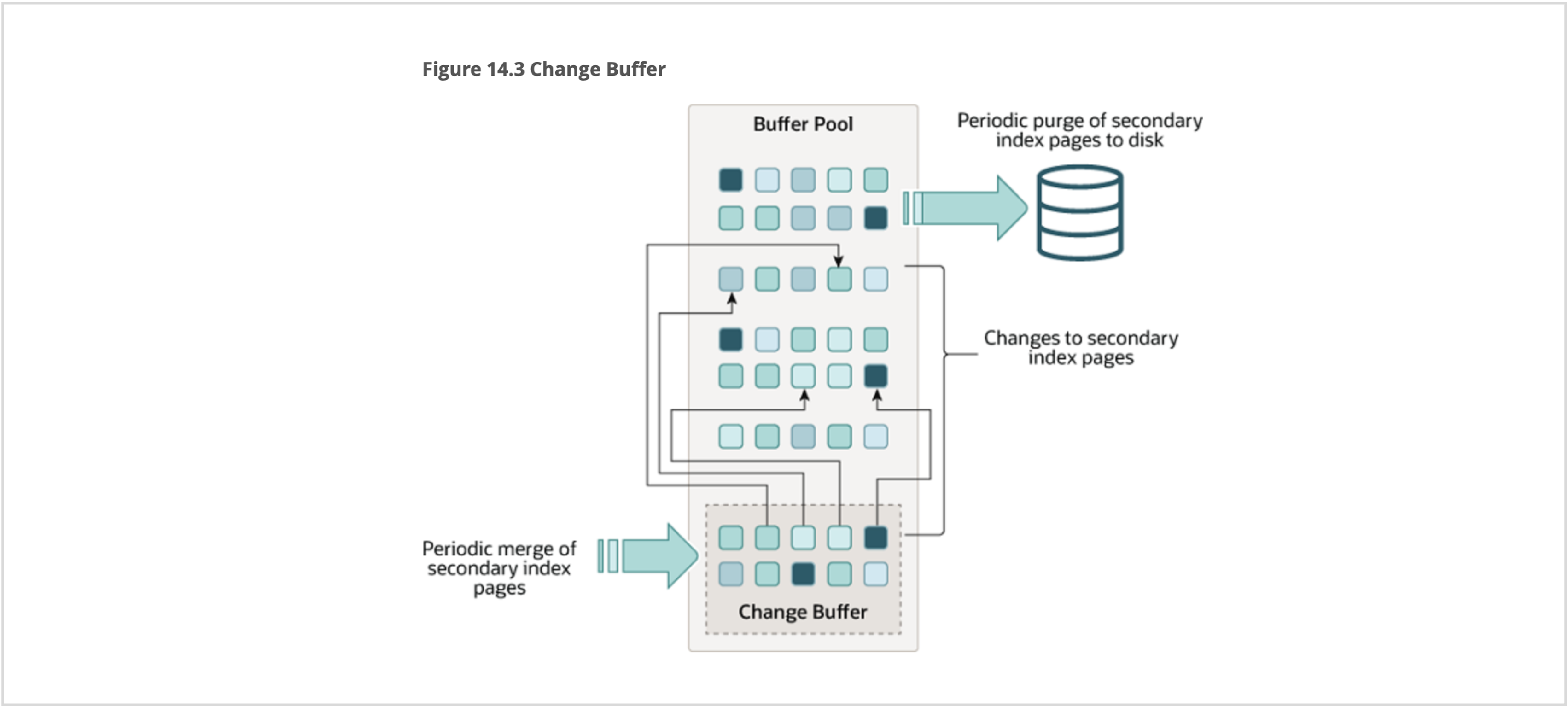
- 세컨더리 인덱스는 보통 유니크하지 않은 경우가 많다
- 그리고 세컨더리 인덱스에 삽입하는 데이터는 보통 한 곳에서 순차적으로 발생하지 않고, 랜덤한 곳에서 발생한다
INSERT,UPDATE,DELETE와 같은 DML작업이 세컨더리 인덱스(secondary index)를 가지는 컬럼에 발생했을 때,- 해당 변경사항을 반영하기 위해 세컨더리 인덱스를 업데이트 해야한다.
- 이 때 만약 세컨더리 인덱스 페이지가 버퍼 풀에 없다면,
- 세컨더리 인덱스 페이지를 업데이트 하기 위해 디스크에 접근하게 되면 디스크 I/O로 인해 성능 저하
- -> 세컨더리 인덱스 페이지의 변경사항을 체인지 버퍼에 캐시해둔다
- 나중에
SELECT연산에 의해 버퍼 풀에 인덱스 페이지가 로드되면, 그 때 체인지 버퍼에 캐시된 변경사항을 버퍼 풀로 병합시킨다 - 그래서 대량의 DML 작업이 발생할 때, 체인지 버퍼는 많은 도움이 된다
- 하지만 체인지 버퍼는 버퍼 풀 메모리의 일부를 차지하고 있다
- 그래서 만약 주로 읽기 작업이 발생하는 OLAP를 위해 사용하고 있거나, 세컨더리 인덱스가 별로 없는 경우에는 체인지 버퍼의 기능을 꺼두는 것이 좋다
- MySQL 공식문서 참고. 내용 좋음
기본적으로 데이터/인덱스 변경사항은 버퍼 풀에 반영된다
근데 그중에서 세컨더리 인덱스에 한해,
버퍼 풀에 세컨더리 인덱스 페이지가 없을 때 변경 사항을 체인지 버퍼에 캐시해둔다
읽기 작업으로 버퍼 풀에 세컨더리 인덱스 페이지가 생겼으면 버퍼 풀에 있는 세컨더리 인덱스 페이지로 변경 사항을 병합한다
-> 체인지 버퍼는 세컨더리 인덱스 페이지가 버퍼 풀에 없는 경우에만 유용하다
-> 세컨더리 인덱스 페이지가 버퍼 풀에 있으면 변경 사항은 바로 버퍼 풀에 반영된다
로그 버퍼
The log buffer is the memory area that holds data to be written to the log files on disk. Log buffer size is defined by the innodb_log_buffer_size variable. The default size is 16MB. The contents of the log buffer are periodically flushed to disk. A large log buffer enables large transactions to run without the need to write redo log data to disk before the transactions commit. Thus, if you have transactions that update, insert, or delete many rows, increasing the size of the log buffer saves disk I/O.
- 디스크의 로그 파일에 쓸 데이터를 버퍼링하는 메모리 영역
- 기본 크기는
innodb_log_buffer_size=16MB - 로그 버퍼의 내용은 주기적으로 디스크로 플러시
- 로그 버퍼 사이즈를 크게하면 대량의 트랜잭션에 필요한 리두 로그를 디스크에 매번 쓰지 않아도 된다
-
만약 많은 레코드에 변경사항이 생기는 트랜잭션을 수행해야 한다면 로그 퍼버 사이즈를 키우는 것이 성능 향상에 도움이 된다
- 로그 버퍼와 관련한 몇가지 설정
innodb_log_buffer_size: 로그 버퍼의 크기. 기본값은 16MBinnodb_flush_log_at_trx_commit: 트랜잭션을 얼마나 엄격하게 지킬 것인지1(default): 트랜잭션의 ACID 특성을 완전히 준수 -> 트랜잭션이 커밋될 때마다 로그 버퍼상의 로그를 디스크의 로그 파일로 바로 플러시0: 1초마다 로그 버퍼에 로그가 쓰여지고 플러시 된다. 트랜잭션을 수행했지만 그 사이에 충돌이 나서 로그를 쓰지 못하게 될 경우 데이터 손실이 발생할 수 있다2: 로그 버퍼에 로그를 쓰는 시점은 각 트랜잭션이 커밋된 후다. 버퍼에 쓰인 로그가 플러시 되는 주기는 0과 같이 1초다.- 어떤 모드를 선택하는가에 따라 안전한 트랜잭션 처리 vs 성능 간의 트레이드 오프가 있다
innodb_flush_log_at_timeout: 메모리 상의 로그 버퍼를 디스크에 있는 로그 파일로 플러시하는 주기
리두 로그
- 데이터의 변경 내용을 기록하는 디스크 기반 자료구조
- SQL문 또는 low-level API 호출과 같이 테이블 데이터에 변경을 발생시키는 요청을 인코딩하여 리두 로그 파일에 저장한다
- ACID의 D(Durable)에 해당하는 영속성과 가장 밀접하게 연관
- 장애로 데이터 파일에 기록되지 못한 데이터를 잃지 않게 해주는 역할
- 상대적으로 비용이 높은 쓰기 작업의 성능 향상을 위해 로그 버퍼에 리두 로그를 버퍼링한 후 디스크 영역에 저장
- 데이터가 데이터 파일에 저장되는 시점보다 리두 로그가 로그 파일에 먼저 저장 -> 리두 로그를 WAL 로그라고도 함
-
(참고로 트랜잭션 커밋이 플러시를 포함하지는 않음. 커밋은 트랜잭션에서 요구한 데이터 변경사항대로 버퍼 풀에서 데이터에 변경이 이루어졌다는 것을 의미. 만약
autoflush=True라면, 트랜잭션 커밋마다 디스크에 플러시를 수반할 것이다) - 리두 로그와 관련된 몇 가지 옵션
innodb_redo_log_capacity: 리두 로그가 차지하는 디스크의 용량innodb_log_file_size: 디스크에 있는 로그 파일의 크기innodb_log_files_in_group: 디스크에 있는 로그 파일의 개수
버퍼 풀과 리두 로그의 관계
- 버퍼 풀과 리두 로그의 관계를 이해하면 버퍼 풀 성능 향상에 도움이 되는 요소를 알 수 있음
- 데이터 변경이 발생하면 버퍼 풀에는 더티 페이지가 생기고, 로그 버퍼에는 리두 로그 레코드가 버퍼링
- 이 두가지 요소는 체크포인트마다 디스크로 동기화되어야 함
- 체크포인트는 장애 발생시 리두 로그의 어느 부분부터 복구를 실행해야 할지 판단하는 기준점
버퍼 풀 플러시
- 버퍼 풀을 플러시하면 버퍼 풀 메모리 공간과 리두 로그 공간을 모두 얻을 수 있음
- 버퍼 풀을 플러시(더티 페이지들을 디스크에 동기화)하면 오래된 리두 로그 공간을 지울 수 있음
- 이를 위해 InnoDB 스토리지 엔진은 주기적으로 플러시 리스트 플러시 함수를 호출
- 플러시 리스트에서 오래 전에 변경된 데이터 페이지 순서대로 디스크에 동기화
- 또한 사용 빈도가 낮은 데이터 페이지를 제거하기 위해 LRU 리스트 플러시 함수를 호출
- 이 때 InnoDB 스토리지 엔진은 버퍼 풀을 스캔하며 더티 페이지는 동기화, 클린 페이지는 프리 리스트로 옮김
언두 로그
- DML(INSERT, UPDATE, DELETE)로 변경되기 이전 버전의 백업된 데이터를 기록해두는 디스크 기반 자료구조
- 트랜잭션 보장: 트랜잭션이 롤백될 경우 원래 데이터로 복구하기 위해 언두 로그에 백업해둔 데이터를 이용
- 격리수준 보장: 특정 커넥션이 변경 중인 레코드에 다른 커넥션이 접근할 경우 격리수준에 맞게 언두 로그의 이전 데이터 제공
- 대용량 데이터를 변경하거나, 오랜 시간 유지되는 트랜잭션이 증가할 경우 언두 로그의 크기 급격히 증가
- 언두 로그의 사이즈가 커지면 쿼리 실행시 스토리지 엔진은 언두 로그를 필요한 만큼 스캔해야해서 쿼리의 성능이 감소
테이블 스페이스
The System Tablespace
The system tablespace is the storage area for the change buffer. It may also contain table and index data if tables are created in the system tablespace rather than file-per-table or general tablespaces. In previous MySQL versions, the system tablespace contained the InnoDB data dictionary. In MySQL 8.0, InnoDB stores metadata in the MySQL data dictionary. See Chapter 14, MySQL Data Dictionary. In previous MySQL releases, the system tablespace also contained the doublewrite buffer storage area. This storage area resides in separate doublewrite files as of MySQL 8.0.20. See Section 15.6.4, “Doublewrite Buffer”.
The system tablespace can have one or more data files. By default, a single system tablespace data file, named ibdata1, is created in the data directory. The size and number of system tablespace data files is defined by the innodb_data_file_path startup option. For configuration information, see System Tablespace Data File Configuration.
File-Per-Table Tablespaces
A file-per-table tablespace contains data and indexes for a single InnoDB table, and is stored on the file system in a single data file.
A file-per-table tablespace is created in an .ibd data file in a schema directory under the MySQL data directory. The .ibd file is named for the table (table_name.ibd).
General Tablespaces
A general tablespace is a shared InnoDB tablespace that is created using CREATE TABLESPACE syntax.
Undo Tablespaces
Undo tablespaces contain undo logs, which are collections of records containing information about how to undo the latest change by a transaction to a clustered index record.
Temporary Tablespaces
InnoDB uses session temporary tablespaces and a global temporary tablespace.
Session temporary tablespaces store user-created temporary tables and internal temporary tables created by the optimizer when InnoDB is configured as the storage engine for on-disk internal temporary tables. Beginning with MySQL 8.0.16, the storage engine used for on-disk internal temporary tables is InnoDB. (Previously, the storage engine was determined by the value of internal_tmp_disk_storage_engine.)
`
Session temporary tablespaces are allocated to a session from a pool of temporary tablespaces on the first request to create an on-disk temporary table. A maximum of two tablespaces is allocated to a session, one for user-created temporary tables and the other for internal temporary tables created by the optimizer. The temporary tablespaces allocated to a session are used for all on-disk temporary tables created by the session. When a session disconnects, its temporary tablespaces are truncated and released back to the pool. A pool of 10 temporary tablespaces is created when the server is started. The size of the pool never shrinks and tablespaces are added to the pool automatically as necessary. The pool of temporary tablespaces is removed on normal shutdown or on an aborted initialization. Session temporary tablespace files are five pages in size when created and have an .ibt file name extension.
어댑티브 해시 인덱스
MySQL과 같은 RDBMS에서 대표적으로 가장 많이 사용되는 자료 구조는 B-Tree입니다. 데이터 사이즈가 아무리 커져도 특정 데이터 접근에 소요되는 비용이 크게 증가되지 않기 때문에 어느정도 예상할 수 있는 퍼포먼스를 제공할 수 있기 때문이죠. 그치만 상황에 따라서, B-Tree 사용에 따른 잠금 현상으로 최대의 퍼포먼스를 발휘하지 못하는 경우도 있습니다.
B-Tree를 통하여 굉장히 빈도있게 데이터로 접근한다면, 어떻게 될까요? DB 자체적으로는 꽤 좋은 쿼리 처리량을 보일지는 몰라도, 특정 데이터 노드에 접근하기 위해서 매번 트리의 경로를 쫓아가야하기 때문에, “공유 자원에 대한 잠금”이 발생할 수 밖에 없습니다. 즉, Mutex Lock이 과도하게 잡힐 수 있는데, 이 경우 비록 데이터 셋이 메모리보다 적음에도 불구하고 DB 효율이 굉장히 떨어지게 됩니다.
이에 대한 해결책으로 InnoDB에는 Adaptive Hash Index 기능이 있다.
“Adpative”라는 말에서 느껴지듯이, 이 특별한 자료구조는 명쾌하게 동작하지는 않고, “자주” 사용되는 데이터 값을 InnoDB 내부적으로 판단하여 상황에 맞게 해시를 생성” 합니다.
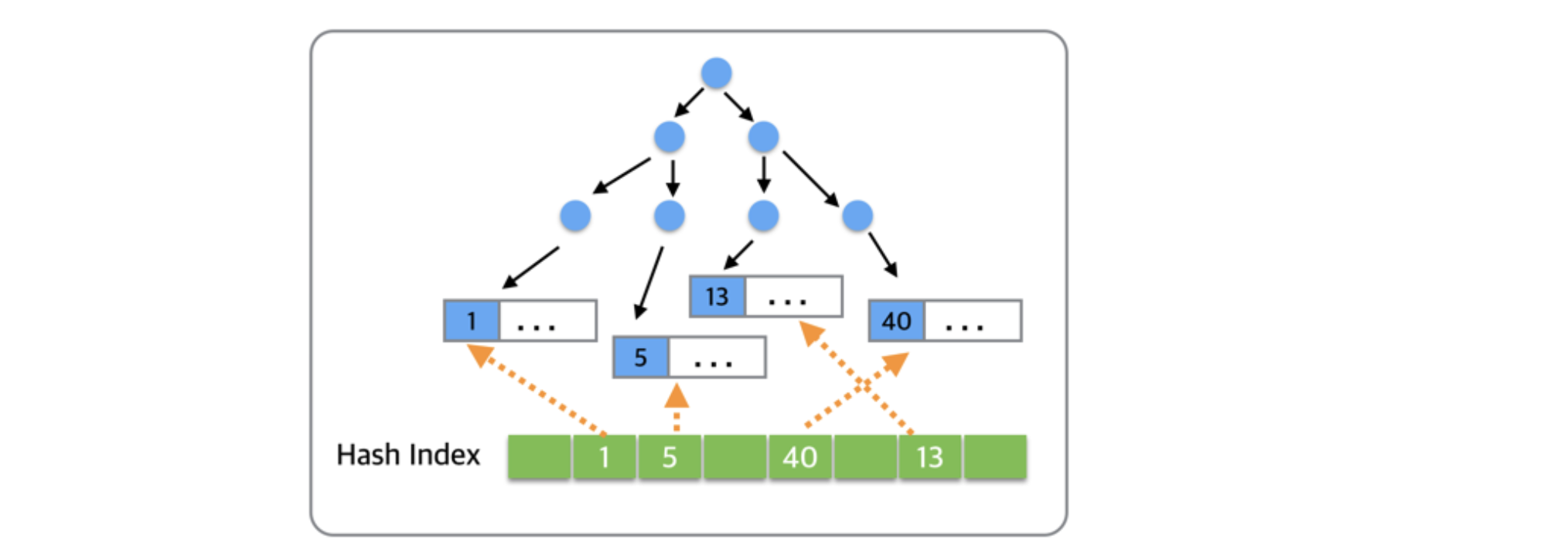
위 그림에서 자주 사용되는 데이터들이 1,5,13,40이라고 가정할 때 위와 같이 내부적으로 판단하여 트리를 통하지 않고 “직접 원하는 데이터로 접근할 수 있는 해시 인덱스”를 통해 직접 데이터에 접근합니다.
참고로, Adative Hash Index에 할당되는 메모리는 전체 Innodb_Buffer_Pool_Size의 1/64만큼으로 초기화됩니다. 단, 최소 메모리 할당은 저렇게 할당되나, 최대 사용되는 메모리 양은 알 수는 없습니다. (경우에 따라 다르지만, Adaptive Hash Index가 사용하는 인덱스 사이즈를 반드시 모니터링해야 합니다.)
자주 사용되는 데이터는 해시를 통해서 직접 접근할 수 있기에, Mutex Lock으로 인한 지연은 확연하게 줄어듭니다. 게다가 B-Tree의 데이터 접근 비용(O(LogN))에 비해, 해시 데이터 접근 비용인 O(1)으로 굉장히 빠른 속도로 데이터 처리할 수 있습니다.
단, “자주” 사용되는 자원만을 해시로 생성하기 때문에, 단 건 SELECT로 인하여 반드시 해당 자원을 향한 직접적인 해시 값이 만들어지지 않습니다.
InnoDB는 Primary Key를 통한 데이터 접근을 제일 선호하기는 하지만, 만약 PK접근일지라도 정말 빈도있게 사용되는 데이터라면 이 역시 Hash Index를 생성합니다.
InnoDB Adaptive Hash Index는 B-Tree의 한계를 보완할 수 있는 굉장히 좋은 기능임에는 틀림 없습니다. 특히나 Mutex와 같은 내부적인 잠금으로 인한 퍼포먼스 저하 상황에서는 좋은 튜닝요소가 될 수 있습니다.
그러나, “자주” 사용되는 데이터를 옵티마이저가 판단하여 해시 키로 만들기 때문에 제어가 어려우며, 테이블 Drop 시 영향을 줄 수 있습니다. Hash Index 구조가 단일 Mutex로 관리되기 때문에, 수개월간 테이블이 사용되지 않던 상황에서도 문제가 발생할 수 있는 것입니다.
굉장한 SELECT를 Adaptive Hash Index로 멋지게 해결하고 있다면, 이에 따른 Side Effect도 반드시 인지하고 잠재적인 장애에 대해서 미리 대비하시기 바래요. ^^
gywndi’s database, InnoDB의 Adaptive Hash Index로 쿼리 성능에 날개를 달아보자!! 포스트 참고