Table of Contents
트랜잭션
DBMS에서 트랜잭션이란 하나의 논리적 작업 단위를 의미하며, 여러 작업(DB의 읽기, 쓰기)을 한 단계로 표현하는 방법입니다. 트랜잭션은 어플리케이션 개발에서 부분 업데이트 현상으로 인해 데이터의 정합성이 깨지는 문제를 걱정하지 않도록 해줍니다. 트랜잭션을 사용할 때는 가능한 범위를 최소화하는 것이 좋습니다. 특히 네트워크를 통해 발생하는 작업은 트랜잭션 내에서 제거해야 합니다. 네트워크간 데이터 이동은 그 자체로 높은 비용이 발생할 뿐 아니라, 다양한 이유로 장애가 발생할 수 있는 부분이기 때문입니다. 트랜잭션이 종료되지 않고 유지되는 시간이 길어지면 MySQL서버의 전체적인 성능 하락에 주요 이유가 됩니다.
ACID
이러한 트랜잭션을 정의하기 위해서는 다음의 4가지 속성이 보장되어야 합니다.
원자성(Atomicity)
- 트랜잭션으로 묶인 데이터의 변경 사항은 모두 반영되거나 모두 반영되지 않아야 합니다
- All or Nothing
- ex) A에서 B로 계좌이체를 할 때, A가 출금이 되면 B도 반드시 입금이 되어야 한다.
일관성(Consistency)
- 트랜잭션이 일어나더라도 데이터베이스의 제약이나 규칙은 그대로 지켜져야 합니다.
- 사용자가 제어할 수 있는 유일한 속성입니다.
- ex) 고객 정보 DB에서 이름을 반드시 입력하도록 제약을 두었다면 트랜잭션 또한 이러한 제약을 가져야 한다.
격리성(Isolation)
- 하나의 트랜잭션은 다른 트랜잭션으로부터 간섭없이 독립적으로 수행되어야 합니다.
- 동시에 여러 개의 트랜잭션들이 수행될 때, 각 트랜잭션은 순차적으로 실행된 것과 동일한 결과를 나타내야 합니다.
- ex) A가 만원이 있는 계좌에서 B에게 3천원을 송금하던 도중 자신의 잔액을 확인할 때는 여전히 만원이 있어야 한다.
- 많은 데이터베이스는 성능상의 이유로 정의에 비해 약한 격리 수준을 사용합니다. (동시성 제어의 격리 수준 참고)
지속성(Durability)
- 커밋된 데이터는 장애가 발생 하더라도 데이터베이스에 저장되어야 한다.
- ex) A에서 B로 송금이 완료되어 커밋을 했다면 시스템 중단, 정전으로 장애가 발생해도 DB에 데이터가 그대로 유지되어야 한다
페이지 캐시
대부분의 데이터베이스는 상대적으로 속도가 느린 영구 저장소(디스크)에 접근하는 회수를 줄이기 위해 페이지를 메모리에 캐시합니다. 이를 페이지 캐시(page cache)라고 하며 이 때의 메모리 영역을 버퍼 풀(buffer pool)이라고 합니다. 메모리에 있는 페이지에 변경사항이 생겼을 때 아직 디스크로 플러시(flush)되지 않은 페이지를 더티(dirty) 페이지라고 합니다.
정리하면 페이지 캐시의 주요 기능은 다음과 같습니다.
- 페이지를 메모리에 캐시함으로써 빠른 읽기를 지원
- 쓰기 요청이 발생할때마다 디스크로 플러시하지 않고 버퍼링 후 플러시 할 수 있다 -> 디스크 I/O를 줄임
캐싱
스토리지 엔진이 특정 페이지를 요청하면 우선 캐시된 버전이 있는지 확인합니다. 페이지가 있다면 반환하고 없다면 페이지 번호를 물리적 주소로 변환해 해당 페이지를 메모리로 복사하고 반환합니다.
이때 해당 페이지가 저장된 버퍼는 참조상태라고 표현합니다. 작업이 끝나면 스토리지 엔진은 참조 해제해야 합니다.
캐시 만료
일반적으로 버퍼 풀은 데이터셋보다 크기가 작기 때문에 새로운 페이지를 추가하기 위해 기존 페이지를 만료시키는 작업도 필요하게 됩니다. 페이지가 동기화됐고 고정 또는 참조 상태가 아니라면 바로 제거할 수 있습니다. 페이지를 제거할 때에는 페이지와 관련된 로그도 WAL에서 삭제합니다.
페이지 동기화
위에서 버퍼 풀의 메모리 용량을 관리하기 위해서는 캐시가 만료된 페이지는 제거해야 한다고 했습니다. 그리고 이때 페이지를 제거하기 위해서는 우선 페이지가 동기화되어야 한다고 했습니다. 페이지 동기화는 더티페이지를 디스크에 반영(flush)하는 것입니다.
이렇게 플러시하는 것은 언제 얼마나 자주하는 것이 좋을까요? 변경 사항이 생길 때마다 플러시하게 되면 데이터 손실 가능성을 줄일 수 있겠지만 결국 잦은 디스크 접근을 유발하기 때문에 트레이드 오프가 있습니다. 그래서 데이터베이스에서는 이러한 플러시를 주기적으로 하게 되며 이 시점을 체크포인트(checkpoint)라고 합니다.
체크포인트 시점에 플러시가 일어나는데 이 때 플러시는 디스크에 있는 데이터베이스에 데이터가 저장되는 것을 의미하지는 않습니다. 플러시는 메모리에 있는 페이지에 요청된 작업 명령들을 디스크의 WAL(Write Ahead Log)에 남겨두고 페이지와 싱크를 맞추는 것입니다.
정리하면
- 캐시가 만료된 페이지를 삭제하려면 먼저 페이지를 동기화 해야 한다.
- 동기화된 시점을 체크포인트라고 한다.
- 동기화는 플러시하는 것이며 플러시는 페이지의 변경시 요청된 작업 명령을 디스크의 WAL에 기록하는 것이다.
- 로그를 디스크의 로그 파일에 기록해 둠으로써 장애로 인한 데이터 손실을 대비할 수 있음
- 버퍼 풀의 더티 페이지가 디스크에 플러시 되는 시점은 보통 MySQL 서버가 idle 상태일 때 백그라운드로 진행됨
- 로그를 디스크로 동기화 하는 것이 데이터 자체를 디스크로 동기화 하는 것보다 작업이 가볍기 때문에 굳이 로그를 동기화 하는거임
- (로그는 단순히 append-only이기 때문에 랜덤 I/O가 발생하지 않지만, 데이터를 디스크에 반영하는 것은 데이터가 여러 페이지에 위치해 있기 때문에 랜덤 I/O이 많이 발생함)
페이지 고정
가까운 시간 내에 요청될 확률이 높은 페이지는 캐시에 가둬 두는 것이 좋습니다. 이를 페이지 고정(pinning)이라고 합니다. 예를 들어 이진 트리 탐색에서 트리의 상위 노드는 접근될 확률이 높기 때문에 이러한 상위 노드는 고정해두면 성능 향상에 도움이 됩니다.
페이지 교체 알고리즘
저장 공간이 부족한 캐시에 새로운 페이지를 추가하려면 일부 페이지를 만료시켜야 한다고 했습니다. 하지만 빈번하게 요청될 수 있는 페이지를 만료시키면 같은 페이지를 여러 차례 페이징하는 상황이 발생할 수 있습니다. 페이지 교체 알고리즘은 다시 요청될 확률이 가장 낮은 페이지를 만료시키고 해당 위치에 새로운 페이지를 페이징합니다.
하지만 페이지의 요청 순서는 일반적으로 특정 패턴이 없기 때문에 어떤 페이지가 다시 요청될지 정확하게 예측하는 것은 불가능 합니다. 그래서 보통은 그 기준을 최근에 요청되었는지 여부, 요청된 빈도수 등으로 합니다. 관련 알고리즘에는 FIFO(First In First Out), LRU(Least Recently Used), LFU(Least Frequently Used), CLOCK-sweep 알고리즘이 있습니다.
복구
데이터베이스 시스템은 각자 다른 안정성과 신뢰성 문제를 내재한 하드웨어와 소프트웨어 계층으로 구성됩니다. 따라서 여러 지점에서 장애가 발생할 수 있고, 데이터베이스 개발자는 이러한 장애 시나리오를 고려해 데이터를 저장해야 합니다.
WAL(Write Ahead Log)
선행 기록 로그(WAL)는 장애 및 트랜잭션 복구를 위해 디스크에 저장하는 추가 자료 구조입니다. WAL은 페이지에 캐시된 데이터가 디스크로 플러시 될 때 까지 관련 작업 이력의 유일한 디스크 기반 복사본입니다. WAL은 리두 로그의 또 다른 말입니다.
WAL에 있는 각각의 로그에는 단조 증가하는 고유 로그 시퀀스 번호(LSN: Log Sequence Number)가 있습니다.
WAL의 주요 기능은 다음과 같습니다.
- 장애 발생 시 WAL을 기반으로 마지막 메모리 상태를 재구성한다.
- WAL의 로그를 재수행해서 트랜잭션을 커밋한다.
버퍼 풀 관리 정책
스틸(Steal)과 포스(Force) 정책
DBMS는 스틸/노스틸 정책과 포스/노포스 정책을 기반으로 메모리에 캐시된 변경 사항을 디스크로 플러시하는 시점을 결정합니다. 이러한 정책들은 복구 알고리즘 선택에 큰 영향을 미칩니다.
스틸(Steal)
트랜잭션이 완료되지 않은 상태에서 데이터를 디스크에 기록할 것인가?
- STEAL: 기록한다 (수정된 페이지를 언제든지 디스크에 쓸 수 있는 정책) -> Undo 필요
- No-STEAL: 기록하지 않는다 (수정된 페이지들을 최소한 트랜잭션 종료 시점(EOT)까지는 버퍼에 유지하는 정책)
버퍼 관리자가 트랜잭션 종료 전에는 어떤 경우에도 수정된 페이지들을 디스크에 쓰지 않는다면, Undo 오퍼레이션은 메모리 버퍼에 대해서만 이루어지면 되는 식으로 매우 간단해질 수 있다. 이 부분은 매력적이지만 이 정책은 매우 큰 크기의 메모리 버퍼가 필요하다는 문제점을 가지고 있다. 수정된 페이지를 디스크에 쓰는 시점을 기준으로 다음과 같은 두 개의 정책으로 나누어 볼 수 있다.
Steal 정책은 수정된 페이지가 어떠한 시점에도 디스크에 써질 수 있기 때문에 필연적으로 Undo 로깅과 복구를 수반하는데, 거의 모든 DBMS가 채택하는 버퍼 관리 정책이다.
포스(Force)
트랜잭션이 커밋된 후 바로 데이터를 디스크에 기록할 것인가?
- FORCE: 바로 기록한다
- No-FORCE: 바로 기록하지 않는다(Redo 필요)
성능상의 이유로 때로는 트랜잭션이 완료되기도 전에 디스크에 기록하기도 하고 완료되고 나서도 기록하지 않기도 합니다.
정리해보면 DBMS는 버퍼 관리 정책으로 STEAL과 No-FORCE 정책을 채택하고 있어, 이로 인해서 UNDO 복구와 REDO 복구가 모두 필요하게 된다.
동시성 제어
- 잠금과 트랜잭션, 트랜잭션의 격리 수준이 동시성에 영향을 줌
- 잠금은 동시성을 제어하기 위한 기능
- 트랜잭션은 데이터의 정합성을 보장하기 위한 개념
잠금
- 하나의 레코드를 여러 커넥션에서 동시에 변경하려고 할 때 잠금이 없다면 레코드의 값은 예측할 수 없는 상태가 됨
- 잠금은 동시에 여러 요청이 들어와도 순서대로 한 시점에는 하나의 커넥션만 변경할 수 있게 하는 역할
- MySQL 엔진 레벨의 잠금에는 테이블락, 메타데이터락, 네임드락이 있음
- InnoDB 스토리지 엔진 레벨의 잠금은 (테이블 전체가 아닌) 레코드 기반의 잠금 방식 -> 뛰어난 동시성 처리를 제공
- 정확히는 레코드를 잠그는 것이 아니라 인덱스를 잠그는 방식(데이터 접근 기준에 해당하는 인덱스 모두 잠금)
- 만약 테이블에 인덱스가 하나도 없다면 테이블을 모두 스캔하고 모든 레코드에 잠금이 걸림 -> 인덱스 설계가 중요
격리 수준
- 여러 트랜잭션이 동시에 처리될 때 트랜잭션 간의 작업 내용을 어떻게 공유하고 차단할 것인지 결정하는 레벨
- 격리 수준은 크게 READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, SERIALIZABLE
- READ UNCOMMITTED는 DIRTY READ 문제로, SERIALIZABLE은 동시성 처리 성능 저하로 거의 사용하지 않음
- 오라클 DB는 READ COMMITTED, MySQL은 REATABLE READ를 주로 사용
- 격리 수준에 따라 DIRTY READ, NON-REPEATABLE READ, PHANTOM READ와 같은 부정합 문제 발생
READ UNCOMMITTED
- 트랜잭션에서의 변경 내용이 COMMIT이 되었는지 ROLLBACK이 되었는지 관계없이 다른 트랜잭션에서 보임
- 해당 트랜잭션이 COMMIT되면 상관없지만 ROLLBACK된 경우 다른 트랜잭션은 잘못된 데이터를 읽어간 것이 됨
READ COMMITTED
- 오라클 DB를 포함해 많은 온라인 서비스에서 선택하는 격리 수준
- 트랜잭션이 데이터를 변경하고 COMMIT 하지 않았다면 다른 트랜잭션은 언두 영역에 백업된 레코드를 읽어감
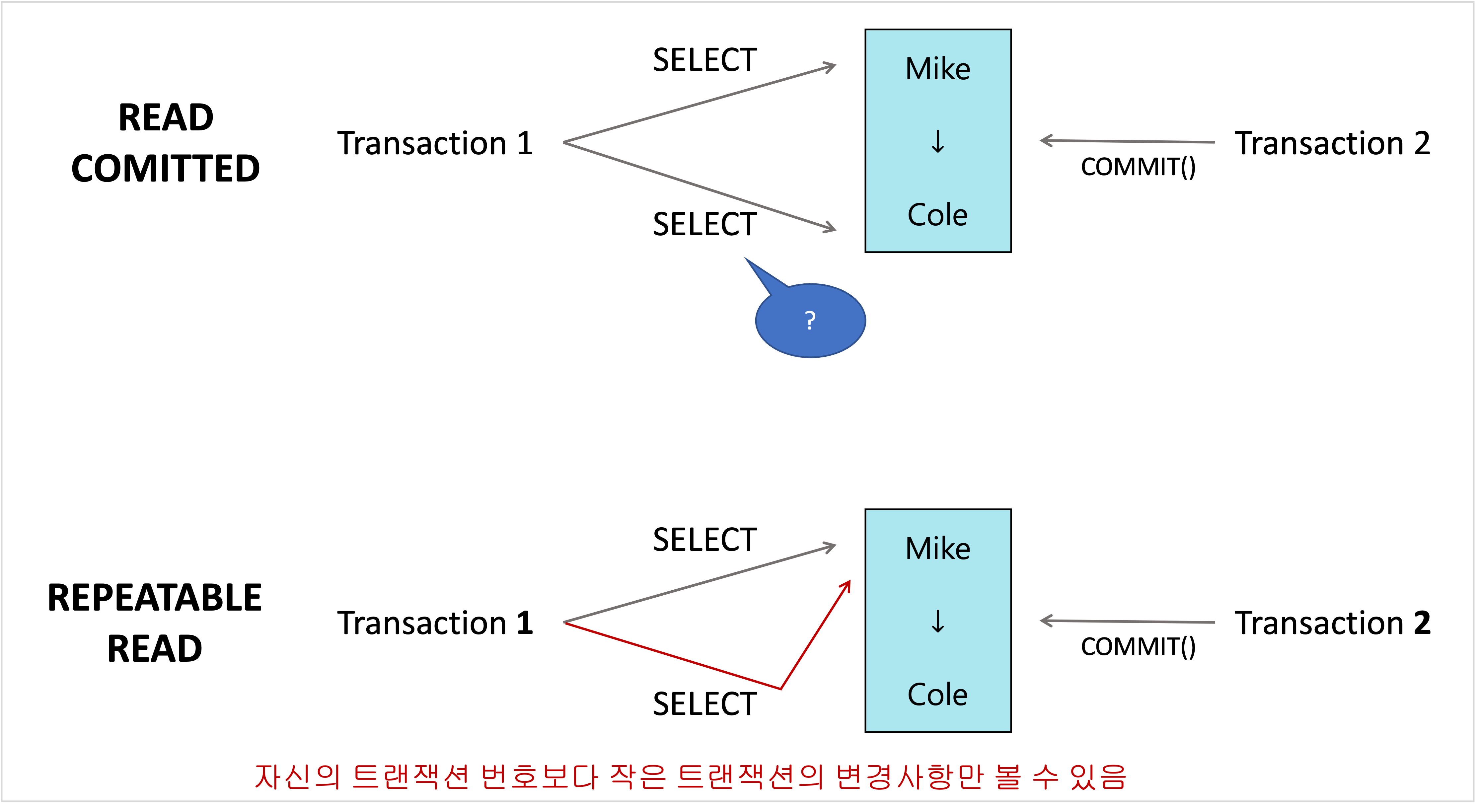
- NON-REPEATABLE READ 문제 발생
- 어떤 트랜잭션내에서 SELECT 요청이 두 번 발생하는 동안 다른 트랜잭션이 데이터 변경 후 커밋하면 하나의 트랜잭션내에서 같은 SELECT 요청에 대해 다른 결과가 나오게 됨
REPEATABLE READ
- InnoDB 스토리지 엔진에서 기본적으로 사용되는 격리 수준
- READ COMMITTED, REPEATABLE READ 모두 트랜잭션이 커밋되지 않은 경우 MVCC를 이용해 이전에 커밋된 데이터를 보여줌
- 차이는 언두 영역에 백업된 레코드의 여러 버전 가운데 몇 번째 이전 버전까지 찾아 들어가야 하느냐는 것
- 모든 트랜잭션은 순차적으로 증가하는 고유한 트랜잭션 번호를 가지며 언두 영역에 백업된 모든 레코드에는 변경을 발생시킨 트랜잭션의 번호가 포함돼 있음
- 트랜잭션은 자신보다 작은 트랜잭션 번호를 가지는 트랜잭션이 변경한 사항만 볼 수 있음