Table of Contents
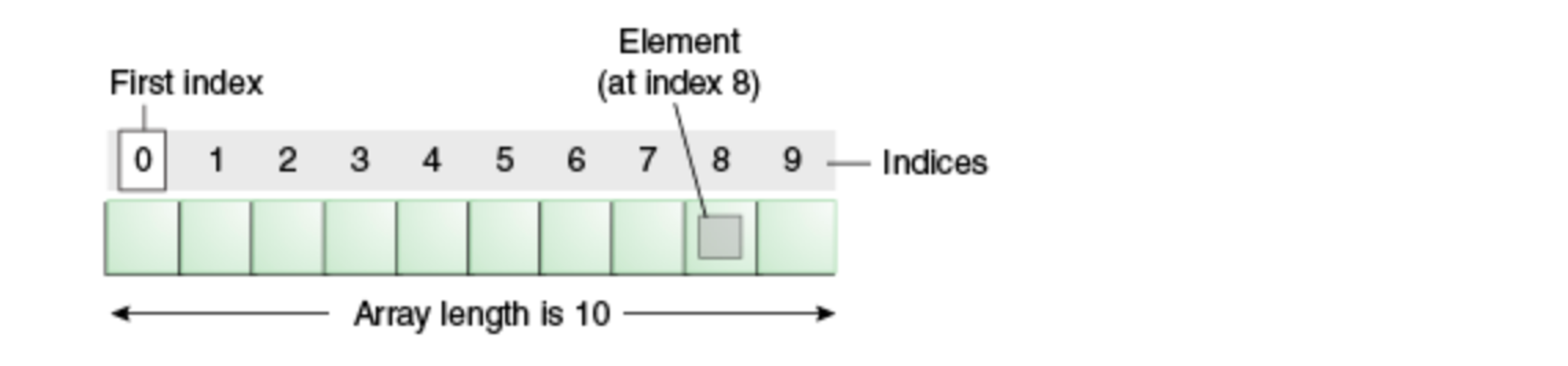
배열
- 배열은 같은 타입의 다수 데이터를 연속된 메모리 공간에 저장하고 있는 자료구조를 말한다
- An array is a container object that holds a fixed number of values of a single type
배열의 특징
빠른 임의 접근
- 같은 타입의 데이터이기 때문에 요소(element) 하나당 차지하고 있는 메모리의 크기가 일정하고, 연속되어 있기 때문에 처음 요소의 메모리 주소를 알면 어떤 위치에 있는 요소든 해당 요소의 메모리 주소를 알 수 있다.
- 결과적으로 임의의 위치에 있는 요소에 시간복잡도 O(1) 으로 접근할 수 있다
고정된 크기
- 일반적으로 배열은 크기가 고정되어 있는 정적 배열이다
- 배열의 크기가 가변적인 동적 배열도 있는데, 동적 배열은 배열의 메모리가 꽉 차면, 새로운 메모리 공간에 더 큰 메모리를 할당해 기존의 요소를 모두 이동시킨다
- 보통 메모리의 크기를 확장 할 때, 딱 추가된 요소의 메모리 크기만큼만 키우는게 아니라, 여분을 생각해서 기존 메모리 크기의 두 배 정도로 한다
- 결과적으로 아주 드문 확률로 doubling 작업이 요소의 추가/삭제 작업을 느리게 만든다
- (아주 드물게 일어나기 때문에 doubling을 배열의 추가/삭제 연산의 속도 문제의 원인으로 생각하지 않는다)
- (배열의 추가/삭제 연산이 비교적 느린 이유는, 요소의 순서를 유지하기 위해 요소들을 한 칸씩 옮기는 작업 때문이다)
배열의 주요 연산과 시간 복잡도
읽기
- 배열은 일정한 크기의 메모리 블록이 연속적으로 저장되어 있다
- 인덱스를 통해 메모리 주소를 계산할 수 있기 때문에, 임의의 위치에 O(1) 으로 접근할 수 있다
삽입
- 배열의 삽입은 추가하고 싶은 인덱스의 위치에 따라 시간복잡도가 다르다
- 맨 앞에 추가하는 경우, 기존 요소들을 모두 뒤로 한 칸씩 이동시켜야 하기 때문에 시간복잡도를 가진다
- 맨 뒤에 추가하는 경우, 별다른 추가 작업이 필요하지 않고, 끝의 위치로 O(1)으로 접근 가능하기 때문에 O(1) 시간복잡도를 가진다
- 임의의 위치에 추가하는 경우, 해당 위치가 앞에 있을수록 느려지고, 뒤에 위치할 수록 빠르다. 결과적으로 분할 상환 분석 측면에서 O(n) 시간복잡도를 가진다 (엄밀하게는 O(n/2))
| 위치 | 시간 복잡도 |
|---|---|
| 맨 앞 | O(n) |
| 맨 뒤 | O(1) |
| 임의의 위치 | O(n) |
삭제
- 삭제는 삽입과 비슷하다
- 다른 점은, 뒤로 한 칸씩 옮기는게 아니라, 앞으로 한 칸씩 옮긴다
| 위치 | 시간 복잡도 |
|---|---|
| 맨 앞 | O(n) |
| 맨 뒤 | O(1) |
| 임의의 위치 | O(n) |
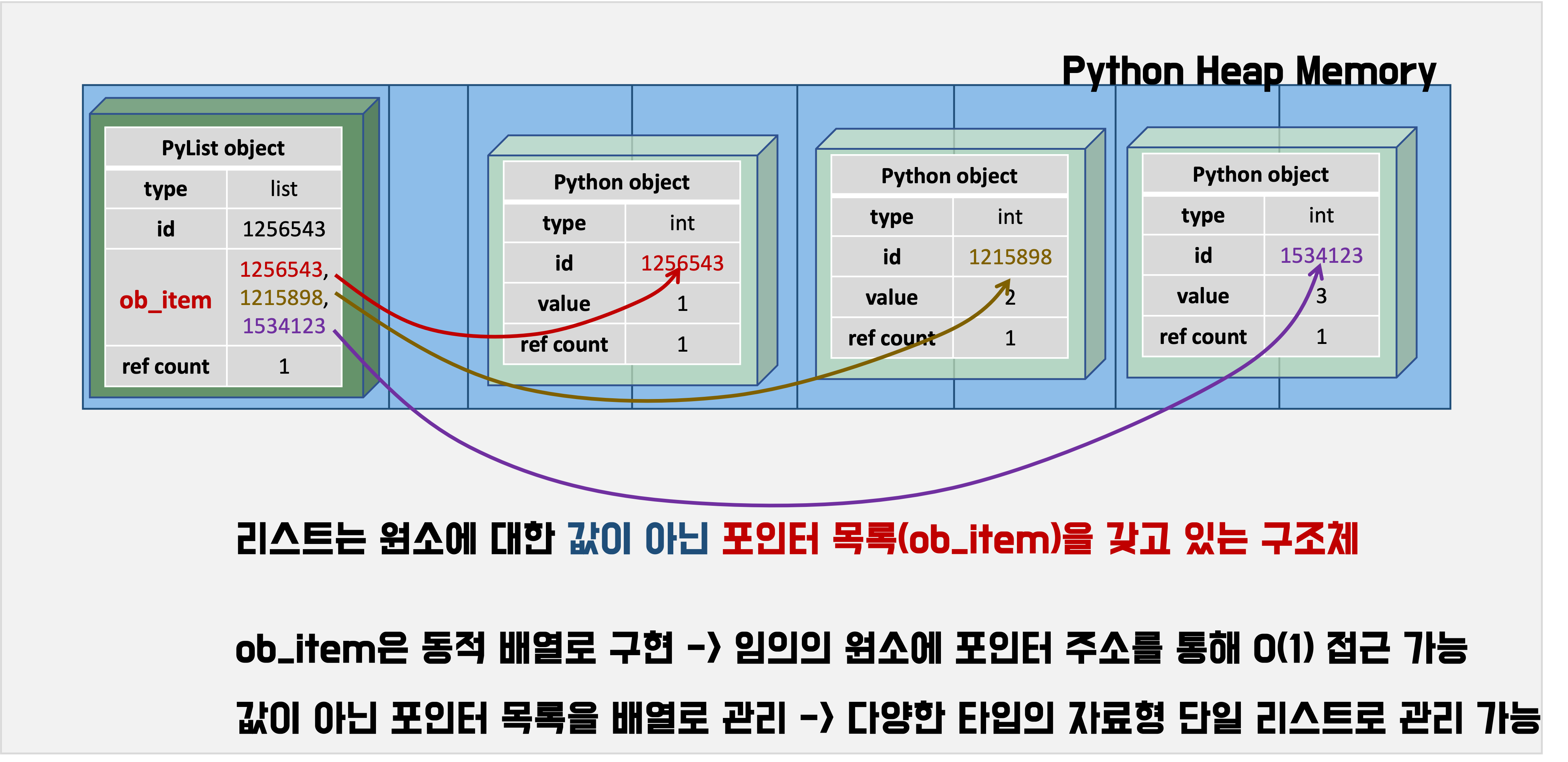
서로 다른 자료형을 가지고 있는 배열
- 파이썬의 리스트는 임의 접근(random access)이 가능하면서도 서로 다른 자료형을 요소로 가질 수 있다
- 파이썬의 리스트는 요소의 실제값이 아니라, 값의 메모리 주소를 가리키는 포인터를 요소로 갖는 배열이다
- 어차피 요소에는 포인터로 접근하기 때문에, 실제로 요소들은 메모리에 연속되어 있을 필요도 없고, 그래서 자료형이 달라도 여전히 임의 접근이 가능하다
- (포인터는 정수형이라는 단일 자료형이기 때문에 배열로 가질 수 있다)