Table of Contents
n_data = 100
x_data = np.random.normal(0, 1, (n_data,))
y_data = np.random.normal(0, 1, (n_data,))
fig, ax = plt.subplots(figsize=(4, 4))
ax.scatter(x_data, y_data, s=400)
ax.scatter(x_data, y_data, s=100)

n_data = 200
x_data = np.random.normal(0, 1, (n_data,))
y_data = np.random.normal(0, 1, (n_data,))
fig, ax = plt.subplots(figsize=(4, 4))
ax.scatter(x_data, y_data, s=100, alpha=0.3)

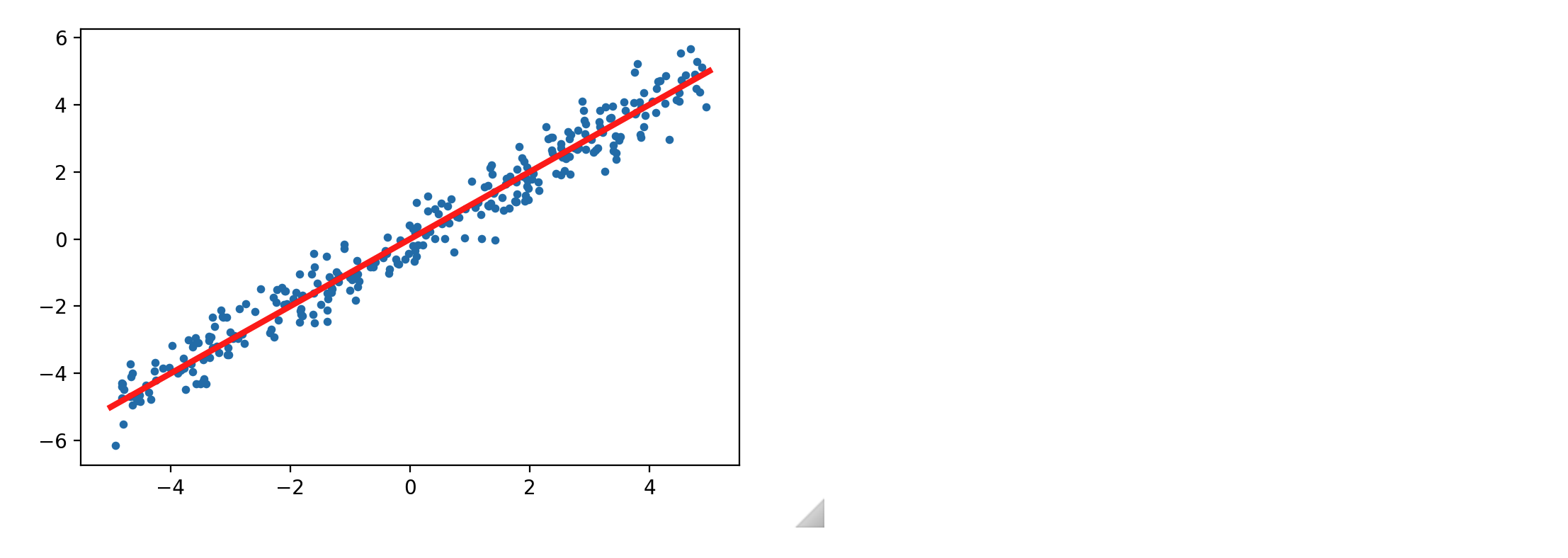
x_min, x_max = -5, 5
n_data = 300
x_data = np.random.uniform(x_min, x_max, n_data)
y_data = x_data + 0.5*np.random.normal(0, 1, n_data)
pred_x = np.linspace(x_min, x_max, 300)
pred_y = pred_x
fig, ax = plt.subplots(figsize=(6, 4))
ax.scatter(x_data, y_data, s=10)
ax.plot(pred_x, pred_y, color='red', linewidth=3)
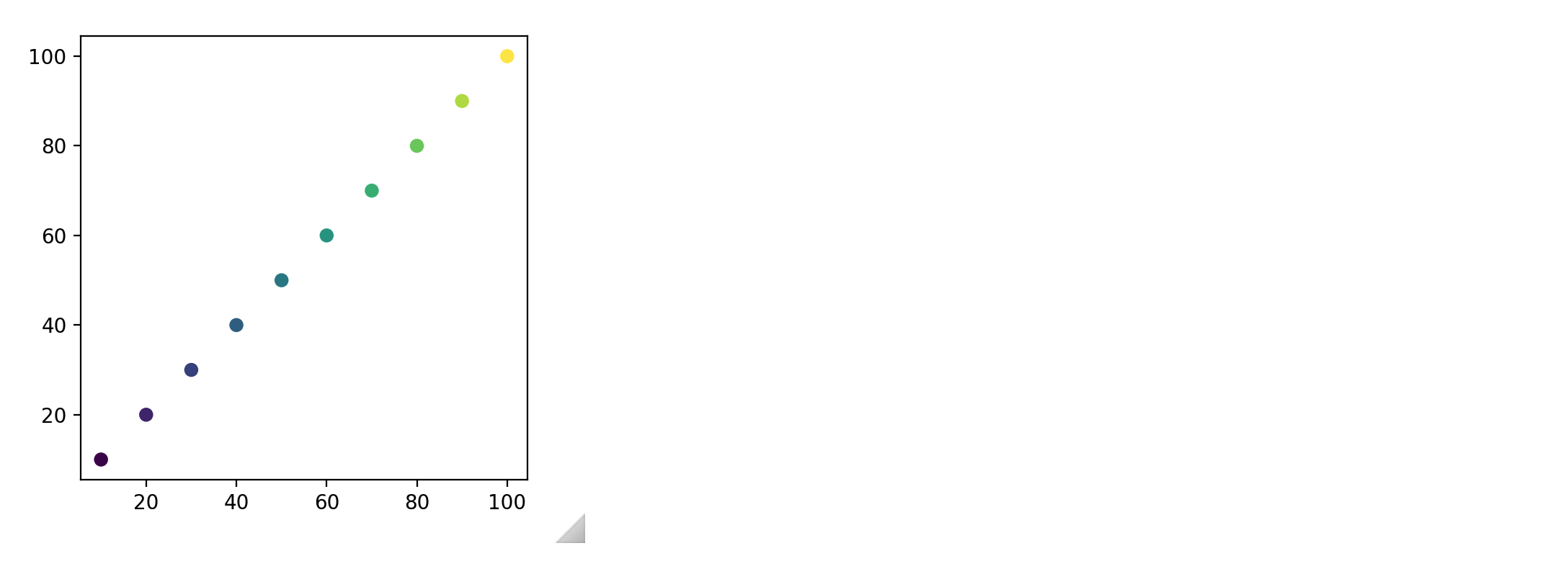
x_data = np.linspace(10, 100, 10)
y_data = np.linspace(10, 100, 10)
size_array = np.linspace(10, 400, 10)
fig, ax = plt.subplots(figsize=(4, 4))
ax.scatter(x_data, y_data, s=size_array)

x_data = np.linspace(10, 100, 10)
y_data = np.linspace(10, 100, 10)
color_array = [i / 10 for i in range(1, 11)]
fig, ax = plt.subplots(figsize=(4, 4))
ax.scatter(x_data, y_data, c=color_array)
# scatter의 size 범위를 그냥 데이터 크기로 하면 안정성이 떨어진다
# 데이터가 음수~양수 분포할 수도 있고, 최대값이 1000000 이런식으로 엄청 큰 값일 수도 있기 때문에,
# 우리가 원하는 값 범위 min_size ~ max_size 로 들어오도록 조정해야 한다
def data2size(data, min_size, max_size):
data = np.array(data)
data -= np.min(data)
data = data / np.max(data)
interval = max_size - min_size
data *= interval
data += min_size
return data
n_data = 200
x_data = np.random.normal(0, 1, (n_data,))
y_data = np.random.normal(0, 1, (n_data,))
z_data = np.random.normal(-100, 10000, (n_data,))
fig, ax = plt.subplots(figsize=(4, 4))
ax.scatter(x_data, y_data, s=z_data, alpha=0.7)

n_data = 200
x_data = np.random.normal(0, 1, (n_data,))
y_data = np.random.normal(0, 1, (n_data,))
z_data = np.random.normal(-100, 10000, (n_data,))
fig, ax = plt.subplots(figsize=(4, 4))
ax.scatter(x_data, y_data, s=data2size(z_data, 10, 400), alpha=0.7)

n_data = 50
x_data = np.random.normal(0, 1, (n_data,))
y_data = np.random.normal(0, 1, (n_data,))
z_data = np.random.normal(-100, 10000, (n_data,))
fig, ax = plt.subplots(figsize=(4, 4))
ax.scatter(x_data, y_data, s=data2size(z_data, 10, 300), alpha=0.7, facecolor='None', edgecolor='tomato', linewidth=2)

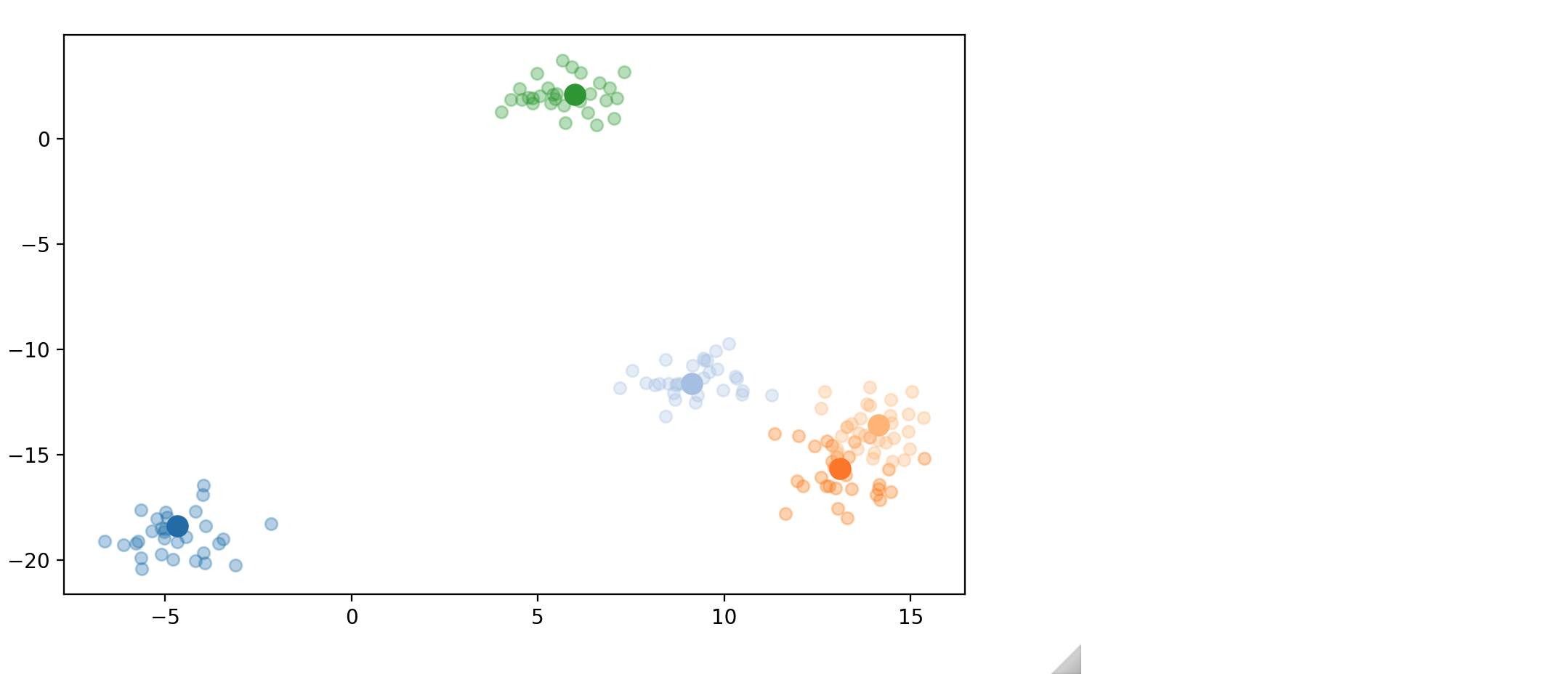
n_class = 5
n_data = 30
center_point = np.random.uniform(-20, 20, (n_class, 2))
cmap = cm.get_cmap('tab20')
colors = [cmap(i) for i in range(n_class)]
data_dict = {'class'+str(i):None for i in range(n_class)}
for i in range(n_class):
x_data = center_point[i][0] + np.random.normal(0, 1, (1, n_data))
y_data = center_point[i][1] + np.random.normal(0, 1, (1, n_data))
data = np.vstack((x_data, y_data))
data_dict['class'+str(i)] = data
fig, ax = plt.subplots(figsize=(8, 5))
for i in range(n_class):
ax.scatter(center_point[i][0], center_point[i][1], s=100, facecolor=colors[i])
ax.scatter(data_dict['class'+str(i)][0], data_dict['class'+str(i)][1], facecolor=colors[i], alpha=0.3, label='class'+str(i))